今天我们来聊一聊基于物品的协同过滤即Item-based CF方法。有了上一篇的经验,你可能很容易就想到Item-based CF就是通过计算物品之间的相似度,然后用户曾与那些商品发生过交互,给他推荐与这些商品最接近的东西给他。这样做有什么好处呢?可解释性!虽然同样是计算相似度,但User-based只能说某个人看起来和你兴趣一致,他喜欢过这个所以我给你推荐这个;而Item-baed则是你曾经看过这个,所以我给你推荐了和这个相似的也许你会喜欢。很明显,第二种更具可解释性,毕竟那是从你直接发生过交互的商品中来的,而人与人之间的相似度,通过简单的统计其实并不能很好的衡量。
那么如何进行Item-baed CF呢?首先是计算物品之间的相似度。这里计算相似度并没有引进物品的属性,而是简单地通过分析用户的历史行为记录进行计算,简单地讲,就是如果有用户购买了某商品的同时又买了其他的商品,那么很有可能这两个商品就是相似的,所以还是可以用余弦相似度来度量
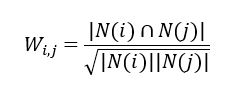
User-baesd CF我们建立了物品用户倒排表方便我们统计对同一商品存在交互的用户,避免把大量的时间浪费在计算没有交互的用户上,这里类似地我们建立用户商品倒排表,对某一用户发生过的所有物品进行两两之间的统计来计算物品之间的相似度,具体实现如下
def Item_Similarity(train):
# Co-rated items between users
C = {}
N = {}
W = {}
for user, items in train.items():
for i in items:
if i not in N.keys():
N[i] = 0
N[i] += 1
if i not in C.keys():
C[i] = {}
W[i] = {}
for j in items:
if j == i:
continue
if j not in C[i].keys():
C[i][j] = 0
W[i][j] = 0
C[i][j] += 1
print('Co-rated items count finished')
# Calculate similarity matrix
for i, related_items in C.items():
for j, cij in related_items.items():
W[i][j] = cij/(N[i]*N[j])**0.5
print('Similarity calculation finished')
return W
有了相似度之后,我们就可以进行推荐了。首先找到用户历史上发生交互的所有商品,然后选择和该商品最相似且没有和用户发生交互的若干商品进入备选集,用两物品之间的相似度作为权值进行累加。这样最后就得到了一个商品及其权值的集合,选择得分最高的若干个结果推荐给用户,公式表示如下

其中rui为用户u对物品i的兴趣,这里可以简单地处理成只要发生交互就为1。代码实现如下
def Recommend(user, train, W, K):
rank = {}
already_items = train[user]
for i in already_items:
for j, wij in sorted(W[i].items(), key=itemgetter(1), reverse=True)[:K]:
if j in already_items:
continue
if j not in rank.keys():
rank[j] = 0
rank[j] += wij
return rank
到了这里我们已经完成了Item-baed CF的推荐过程了,下面还是用MovieLens的数据集进行离线实验。数据划分过程依旧和上次一样,训练集测试集4:1,采用8次计算的结果均值进行效果估计。该实验中主要的可变参数是选择和发生交互商品相似的商品数量K,下图显示了对于不同的K值推荐系统的性能

从图中我们可以看出,对于召回率和准确率而言,K值的变化对于其影响并不是线性的,一开始增大K值可以提高其表现,但很快就开始下降;对于覆盖率而言,由于参与推荐的商品越来越多,所以也越来越倾向于推荐热门商品,导致覆盖率随着K值得增大不断降低,对应的流行度也开始增加,但随着K增大到某种程度之后,流行度不再有明显的变化。
上一篇User-baed CF我们考虑了热门商品人人都爱,它对我们计算用户之间的相似度没有什么贡献,所以我们用Inverse Item Frequence来进行惩罚。同样的,在Item-baed CF中,存在着这样一种用户,他与很多商品都发生过交互,但他发生交互可能是因为他是做这个生意的或者怎么,并不是因为这些商品之间存在某种相似性,所以这里我们同样可以引入Inverse User Frequence来对物品相似度进行加权,从而避免这种用户的影响,新的相似度计算公式如下
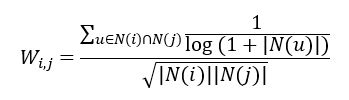
我们使用相同参数(K=160,N=10)的模型,仅仅是相似度计算不同,算法的表现如下图所示

从图中可以看到,召回和准确率提升了,但同时覆盖率和流行度两个指标略有所下降,和我们的分析略微有一点点小出入,我觉得原因主要在于我懒得换新的参数,直接用K=160进行测试的,如此多的待选商品进入备选,商品的流行度和覆盖率表现肯定不好,感兴趣的同学可以试试K=20的情况,同时这也说明一点,离线实验的结果并不那么可信啊!!!
此外,对于Item-baed CF还有一个小trick,就是我们可以对相似度矩阵每一行进行归一化,这样可以得到更好的性能。为啥呢?我们知道物品通常属于若干类,我们再计算相似度的时候,类内的相似度肯定是大于类之间的相似度,这没问题,但不同类内的相似度却是不同的,这就导致我们的推荐的算法有了倾向性,它肯定会推荐更多当前计算相似度高的类。而我们对相似度进行归一化之后,不同类内的最大相似度都被归化到1,某种程度上我们可以认为每个类内的相似度是在同一尺度上的,这样就避免了上面说的那个问题,可以公平地在多个类之间进行推荐,所以这样也可以提高推荐的覆盖率,降低流行度。我们将上一个实验计算得到的相似度矩阵进行归一化之后再进行推荐比较一下性能

从图中我们可以看出对相似度进行归一化之后,所有的评价指标都得到了提高,说明归一化确实可以提高了Item-baed CF的性能。
===============================================================================
到这里对于基于邻域的两种协同过滤的方法都介绍完了,最后我们再来比较一下这两种方法的异同。
首先从原理上来看,User-baed CF是给用户推荐和他兴趣相似的用户喜欢的物品,某种程度上就是寻找一个兴趣相似的小群体,所以其推荐往往更加社会化,但可解释性不太高;而Item-baed CF则是给用户推荐与其喜欢的物品相似的商品,所以在粒度上会更细,个性化更高,而且基于历史记录的推荐,可解释性比较好。
其次,两种方法分别对应于维护两张表。基于用户的需要维护一个用户相似度的表,而基于物品的则需要维护一个物品相似度的表,所以对于用户特别多的情况,计算用户相似度矩阵代价太高,所以更适合Item-baed CF,物品太多的情况类似。对于新物品产生速度非常快如新闻推荐领域,基于物品的协同过滤明显不合适,因为只有更新了物品相似度表该物品才能被推荐,所以对于时效性要求比较高的领域User-baed CF更加合适。
最后,CF方法在我看来来其实都是基于统计的方法,因为它并没有一个学习的过程,所以算是推荐领域比较基础的算法,效果只能说还行,比较适合召回过程这种对排序没性能没有太大要求的场合;另外,CF方法基本上只用了用户历史行为记录,包括用户,包括商品还有环境等特征信息都没有使用,所以效果相比于后面的方法来说肯定会略差一点。
好啦,基于邻域的方法就到这里为止啦,下一篇我们要介绍的是LFM,隐因子模型~