Python爬取
1.爬取内容:对某网站内容与热度进行爬取
分析:我们所需的数据是热搜榜的1—10,第一个数据pass
divs = html.xpath('//div[@class="wbpro-side-card7"]/div[position()>1]')
2.解决没有热力的问题:
别的内容都有热力,但是内容有的热搜内容没有热力,我们取值是会有问题。
解决方法:
if len(hot) == 0:
hot = 0
else:
hot = hot[0]
3.先解决代码报错:
1.UnicodeDecodeError:'utf-8’e0dec can’t decode byte 0xca in position 339: invalid continuation byte
content = response.content.decode('utf8')
这个问题很明显,就是编码错误,我们添加参数:
content = response.content.decode('utf8','ignore')
2.查看我们的content,发现有乱码:红框
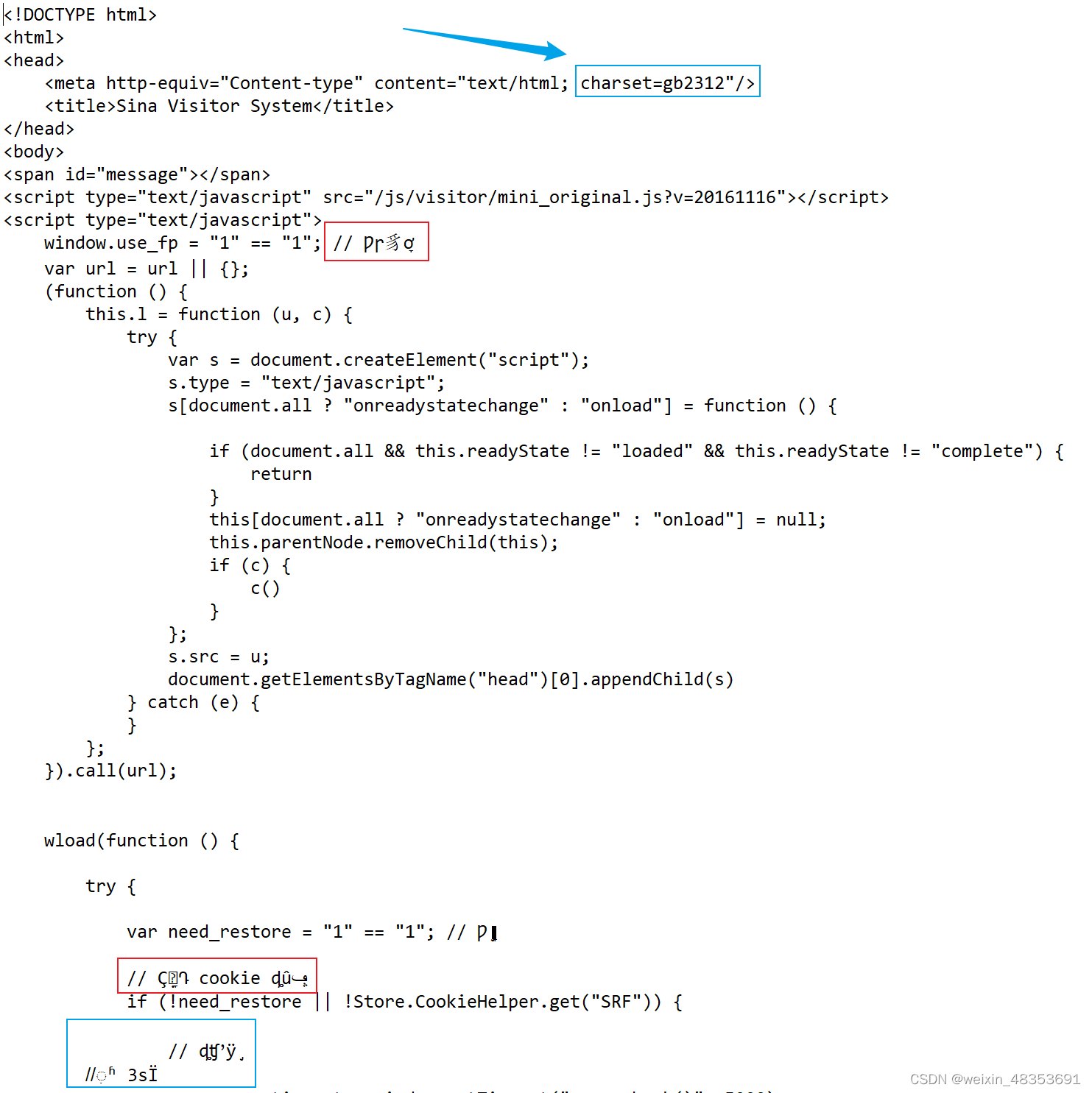
这是编码问题,我们可以看到蓝框的编码格式为gbk,所以我们解码方式改为gbk即可。
3.虽然解决了乱码问题,但我们发现我们的content内容不是微博的html,这岂不是完完?

这就得cookie发挥作用了,我们在headers里面把微博的cookie加进去即可。
注意了:把cookie加进去后我们还要看微博html页面的编码方式,记得改,否则又是乱码。
4.完整代码
import requests
from lxml import etree
url = "https://weibo.com/"
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
"referer":"https://www.baidu.com/",
"cookie":"XSRF-TOKEN=6RDFJg1UNTj_DEvPoqRTAUG9; login_sid_t=ef0d49f7574fc9751c749ba1de65a0b7; cross_origin_proto=SSL; _s_tentry=weibo.com; Apache=6183611172558.001.1668847725620; SINAGLOBAL=6183611172558.001.1668847725620; ULV=1668847725622:1:1:1:6183611172558.001.1668847725620:; wb_view_log=1707*10671.5; appkey=; WBtopGlobal_register_version=2022111916; SUB=_2A25OfOiaDeRhGeFN6lAV9S_EyjuIHXVtCF1SrDV8PUNbmtANLXLSkW9NQHs9kD7YvLPzwuZfd_ycV5SvA3egivkh; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW_.LS0eBuoJRgiGqUDM.ax5JpX5o275NHD95QNe02ESh-p1h2NWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNS0epeoBfeKnpS7tt; ALF=1669452618; SSOLoginState=1668847818; wvr=6; webim_unReadCount=%7B%22time%22%3A1668849960587%2C%22dm_pub_total%22%3A1%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A5%2C%22msgbox%22%3A0%7D; WBPSESS=bSNb1S0dm5_Di4PbdV1iF-fRcZmZMnHImuU-f9Sg5ZfKmlaBX2ffAcb2wpbO6TG5EwxBdK63gFe2sBp1ieb5z9s7XxvQQYRktTJx7xZQTsSPM1jWIqVqNgz9OYf-CPeJYKyJDBzA8pCoJUez48onGA=="
}
response = requests.get(url,headers = headers)
content = response.content.decode('utf8','ignore')
html = etree.HTML(content)
divs = html.xpath('//div[@class="wbpro-side-card7"]//div[position()>1]')
weibo = []
for div in divs:
eg={}
content = div.xpath('./a//div[@title]/text()')[0]
hot = div.xpath('./a/div/div[3]/text()')
if len(hot) == 0:
hot = 0
else:
hot = hot[0]
print(content,hot)
eg = {
"content":content,
"hot":hot
}
weibo.append(eg)
这样我们就爬取到某网站的内容与热度啦!!!