
作者 | 奇伢
来源 | 奇伢云存储

小文件存储

小文件存储,老生常谈的问题。先聊聊小文件存储重点关注的是什么?
以前我们提过,对于磁盘来说,小 io 吃 iops,大块 io 吃吞吐。
划重点:小文件的重点是 io 次数。
为什么每次提到海量小文件的时候,总说传统的文件系统不合适呢?
因为它的元数据操作太惹人眼球了。假设有 1K 的数据,元数据如果搞个 1K ,这个开销就太大了,空间大一倍,性能下降一倍。所以,只要是针对小文件的存储优化,基本上都会在元数据上下点功夫。

Haystack 的背景

Haystack 是 Facebook 为了解决他们图片存储而专门设计的一套存储架构,2012 年发表论文《 Finding a needle in Haystack: Facebook’s photo storage 》。
文中提到当时( 2012 年 )他们已经有 2600 亿张图片,超过 20 PB 的数据,用户每周上传 10 亿张,大约 60 TB 的数据。
从这个数据量来看,确实谈得上海量的文件。算出来的图片平均大小 64K 左右吧,不大,就是以前普通图片的大小。
64K 不知道怎么算的?
用 60 TB 除一个 10 亿就知道了。

Haystack 的特点

接下来聊聊 Haystack 的设计到底有什么神奇特点呢?可以归纳下面四点:
Write Once
Read Often
Nerver Modify
Rarely Deleted
大白话就是,只写一次,从不更新,不定期会读,极少删除。这个 Haystack 特点是适配 Facebook 的图片场景的。
注意,是先有 facebook 的业务场景特点,然后才把 Haystack 设计成这样的。因果关系不要搞反了哦。

海量的文件的挑战在哪里?

每一次文件存储会涉及到元数据和数据两部分的操作。当数量是海量的时候,无论是对存储容量和元数据的量都会带来巨大的影响。
存储容量这个自不用提,这是用户的数据,它是你必须要存储的,通常这里考虑的是存储效率,考虑用更少的介质、更高的可靠性,来存储更多的数据,通常这里的选型是副本和纠删码。
元数据就有意思了,因为这个是内部的设计导致的冗余数据(为了索引用户数据而产生的数据),元数据的设计则会影响到用户的体验,特别是海量的场景。
童鞋思考个问题:海量、小文件 的前提下,为什么元数据会带来挑战?挑战主要是哪些方面?
1 存储成本有挑战
划重点:任何的评估不能脱离场景。
举个简单的例子,假如每个文件 1K ,每个文件对应元数据也 1K ,这开销大不大?
太大了嘛。一倍的浪费。在海量的背景下,用户存储 1P 的数据,就要存储 1P 的元数据,浪费在元数据的成本无法容忍。
那元数据设计成 1K 的是错误的吗?
不一定。
比如说,如果是每个文件 1G,对应每个元数据 1K 呢,这个开销大不大?
不大,因为 1K/1G 才是 0.00009% ,也就是说,用户存储 1P 的数据,元数据消耗为 0.092 TB ,这成本几乎可以忽略。
所以,前提很重要,设计好坏并不是绝对的,都是相对而言的,任何架构都要适配自己的场景。
2 存储性能有挑战
接着上面的例子,每个文件 1K ,每个文件对应元数据也 1K ,这性能开销大不大?
太大了嘛。性能是一倍的损耗。每个文件 1K ,本该一次磁盘 IO 就能解决,但是另外还要加一次元数据操作的磁盘 IO 。也就是说磁盘极限如果 1 万的 iops ,用户只能获取到 5000 的 iops 性能。内部损耗一半。
那如果是每个文件 1G,对应每个元数据 1K 呢,这个开销大不大?
不大嘛,假设每笔 io 是 4K 的定长大小。1G 的数据写 262144 次。只是多加一次元数据 IO ,无关紧要。
3 Hasystack 的突围方向
划重点:小文件的场景,元数据的成本消耗和性能消耗会显得更突出。再加上海量的前提下,这个是必须要解决的挑战。
那 Haystack 应该怎么做呢?两个方面:
重新设计元数据结构,而不是使用文件系统的结构,要精简元数据的大小;
削减元数据的 io 的次数,甚至从 io 路径上彻底消除元数据它;
你如果理解了上面的栗子,对于这两个优化方向的导出应该也是水到渠成的。

Haystack 的目标

高吞吐,低延迟
高可靠,具备故障容错能力;
架构简单,底成本

Haystack 的架构设计

1 整体架构
Haystack 的架构非常简单,截取论文中的图片:

图中表明了三个核心组件:
Haystack Directory
Haystack Cache
Haystack Store
Store 就是一个单机的存储引擎,上层告诉它写哪,它就写哪。管理的单位是一个个大块文件。Haystack 里面叫做 Physical Volume ,其实就是一个个大文件而已啦。
划重点:Haystack 也是基于文件系统之上的。
Physical Volume 有一个阈值,比如写满 100 GB就不写了。可以把它理解成一个大日志文件,数据的写入方式也是 log 日志的方式,append 写入。
Directory 是最上层的一个抽象,上面提到 Store 管理的是 Physical Volume ,上报到 Directory 组件,Directory 把这些底层的 Physical Volume 按照副本关系组织起来形成 Logical Volume 。Logical Volume 就是提供给用户写入数据用的。
举个简单的例子,如果是三副本的 Haystack 系统,那么一个 Logical Volume 由 3 个 Physical Volume 组成副本镜像。
Cache 这个就不用说了,就是一个单纯的缓存组件。
2 数据怎么组织
奇伢用几个问题的形式来阐述数据的组织。
问题一:Physical Volume 是什么?
其实就是大文件,Haystack Store 是基于文件系统之上的。Physical Volume 就实现形式来讲就是文件,可以是 ext4 的文件,也可以是 xfs 的文件。只不过这个文件有名字( Physical Volume ID ),也是一个阈值,比如 100 GB 。
问题二:Logical Volume 是什么?
抽象出来的结构。由多个 Physical Volume 组成。它的个数由副本数决定,比如一个 3 副本 Logical Volume 由 3 个 Physical Volume 组成。
问题三:Physical Volume 内部又是有什么构成呢?
一个叫做 Needle 的东西。
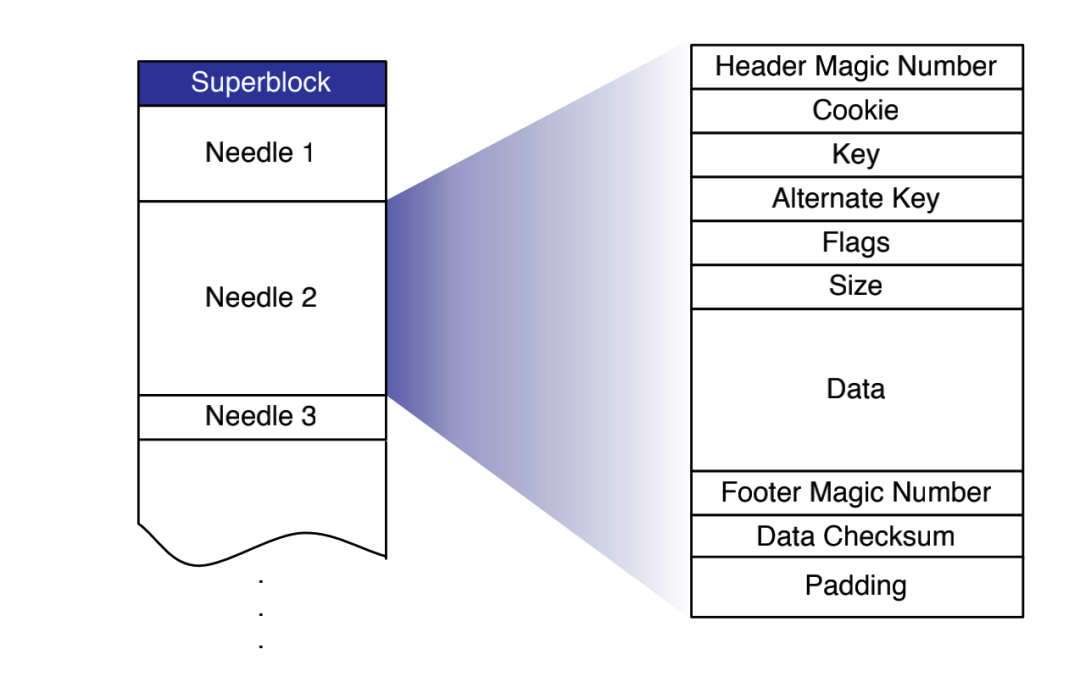
Needle 其实就是用户数据加一些头部,加一些尾部构成的一个整体结构。Physical Volume 就是由这一个个 Needle 组成的。
问题四:Needle 的头尾有啥用?
主要几个方面:
用来构建元数据索引用的,里面有 key,size 等关键数据;
用来校验数据是否损坏,里面有 magic,crc 等;
用来标识数据是否删除,里面有 Flags 标记位;
这些头尾数据就是 Haystack 给每个用户对象重新设计的元数据了,相比文件系统的元数据,这个太精简了。
在内存中的内存表,甚至只需要一个 16 个字节就够了,8 字节的 key ,4 字节的 offset,4 字节的 size 。这个比内核文件系统动辄几百字节甚至几 K 字节要好太多了。
问题四:元数据现在多大了?
元数据分为磁盘元数据(持久化了的)和内存元数据。
磁盘元数据可以看上面的 Needle 结构体,具体实现在 32 字节左右。内存元数据可以控制在 16 个字节。
3 读、写、删
数据写入的流程:

Web 接入点先去 Haystack Directory 选一个 Logical Volume ;
把数据发往 Haystack Store ,写到对应的三个 Physical Volume 即可(注意,append 写入哦);
数据读取的流程:
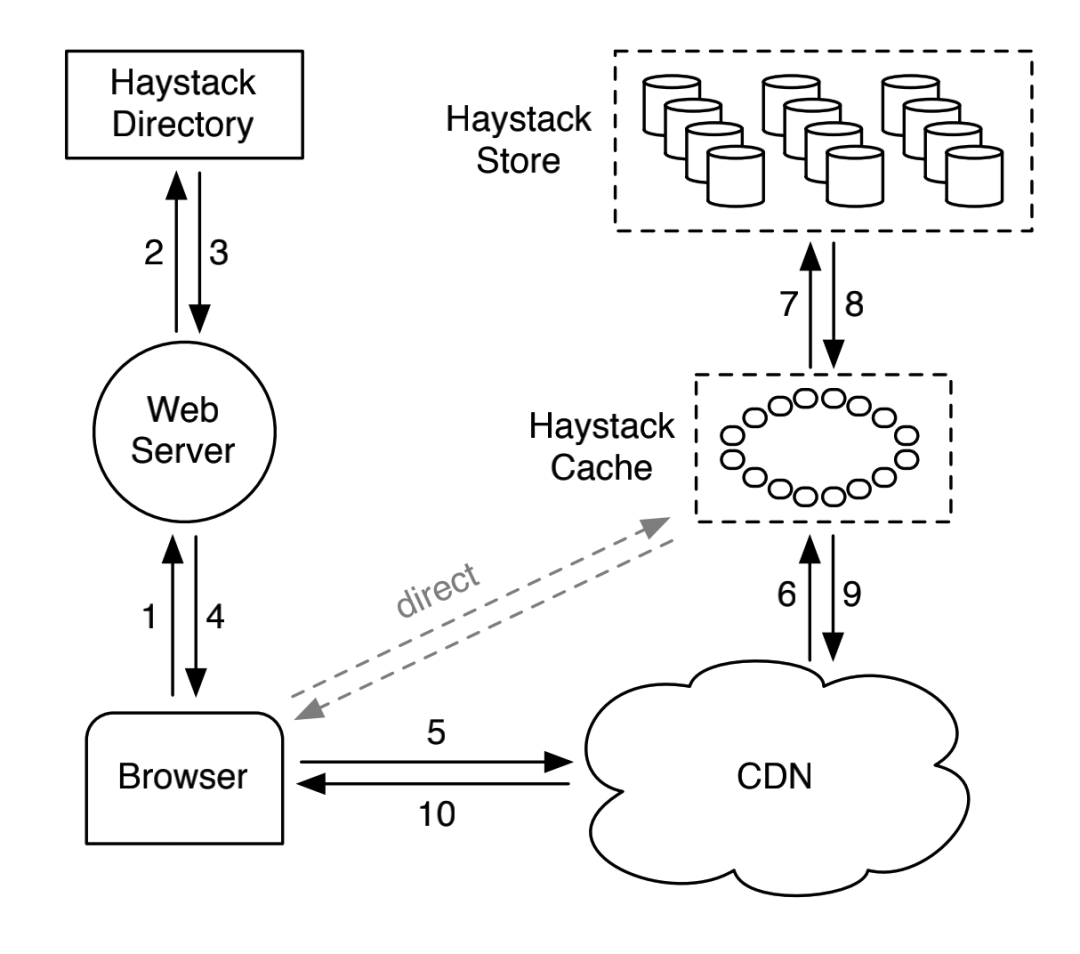
Web 接入点先去 Haystack Directory 拿到指定对象的元数据;
然后请求发给 Haystack Store ,读取数据(这里就不提 Haystack Cache 或者 CDN 的逻辑了,过于简单);
数据删除的流程:
Web 接入点先去 Haystack Directory 拿到指定对象的元数据;
然后把删除请求发给 Haystack Store ,就地更新 Needle 的标记位,标记成删除;
划重点:Haystack 的删除是就地更新,而不是 append 写入。这里跟纯粹的 log 文件不大一样。 但由于删除是极少的,所以就算不是 append 写入,也不影响大局。
4 空间回收
Haystack 也和 LSM,Bitcask 等设计类似,删除是删除,回收是回收,这是两个步骤。
空间回收就是 Compact ,太简单了,论文甚至都没稀的提它,寥寥数语说了两句,原文描述如下:
A Store machine compacts a volume file by copying needles into a new file while skipping any duplicate or deleted entries.
实现很简单,和以前提过的 Compact 并无二样。逻辑就是遍历 Volume 文件,把重复的和标记删除了的 Needle 跳过,有效的 Needle 读出来写到新的地方,即可。

不一样的思考

回想一下这个架构,思考一下它做到了它立的 flag 吗?
1 它的目标:高吞吐,低延迟,怎么实现的呢?
对于写请求,全都化为 append 请求,极力的保持磁盘的顺序性能。并且得益于 Needle 的设计,Haystack 把数据和元数据放在一起,一次性落盘,相当于省去了元数据的 IO 写开销。
当然,这种设计也必然有代价,由此带来的代价就是加载时间变长。
对于读请求,通过元数据的精简,让内存 hold 住所有的元数据,去除了元数据的 IO 开销,这样读操作也就只剩用户数据的 IO 。
注意:Haystack 删除不是 append 哦,而是覆盖写,但之前已经说过了,Haystack 的适用场景就是“极少删除” 。
2 高可靠,故障容错怎么实现的呢?
这个很简单,通过副本冗余来做的。Volume 的组织逻辑放在 Directory 组件中,一份数据存储多份,并且分散在不同的位置。当其中一份故障,则只需要拷贝其他副本即可。
3 毕竟 2012 年的论文,Haystack 的实践过时了吗?
论文中提到,Facebook 当时的实践是用 2U 的刀片服务器,48G 内存,搭配 12 * 1TB 的 SATA 盘。
如果按照一个文件 64 KB 算,一个 needle 内存元数据 16 字节(这个很极限了),只需要 3 G 的内存,单机 48 GB 的物理内存应对这整机的元数据确实绰绰有余。
但现在很多服务器已经升级到 64 盘,单盘 16 TB,满载的话需要 256 G 的内存装元数据。这个内存配比就不大合适了,如果元数据再稍微大点,就更不行了。
但话说回来,并不是每个人都用 64 盘 16 T 的高密服务器,所以并不能一概而论,还是要看自己的需求场景。
就算过去 10 年,我觉得它还能秀。

总结

Haystack 最核心的优化是?重新设计元数据的结构,使得内存元数据只有十几个字节,极大的减轻了负担,且设计的 Needle 结构可以完整恢复内存元数据;
得益于元数据的精简,Haystack 就能把单机全量元数据放在内存;
读的时候,元数据在内存,只有用户数据的 IO 消耗,极大的提高了性能;
写的时候,得益于 Needle 的设计,元数据更新操作不单独刷,而是和用户数据在一起刷,相当于省掉了元数据 IO 的开销;
和 Bitcask 类似,为了提高内存加载速度,也有索引(Index 文件)的实现;
Haystack 并不过时,可以结合自己的场景,焕发生机;

往期推荐
为什么还有这么多的网络故障?
k8s集群居然可以图形化安装了?
用了HTTPS,没想到还是被监控了
将 k8s 制作成 3D 射击游戏,好玩到停不下来

点分享

点收藏

点点赞

点在看