目录
目录结构:
运行环境:
首次运行:
如何训练自己的模型:
数据预处理:
训练模型:
如何确定这个--val_num数值:
编辑编辑最后说明:
打算做一个微博自动评论的一个模型,假象可以模拟回复粉丝,或者评论其他微博。
首先下载GPT2模型代码:
https://github.com/yangjianxin1/GPT2-chitchat 代码版权归原作者所有。
解压下载好的zip,并用pycharm打开
目录结构:
打开README.md文件里面说明了目录结构:
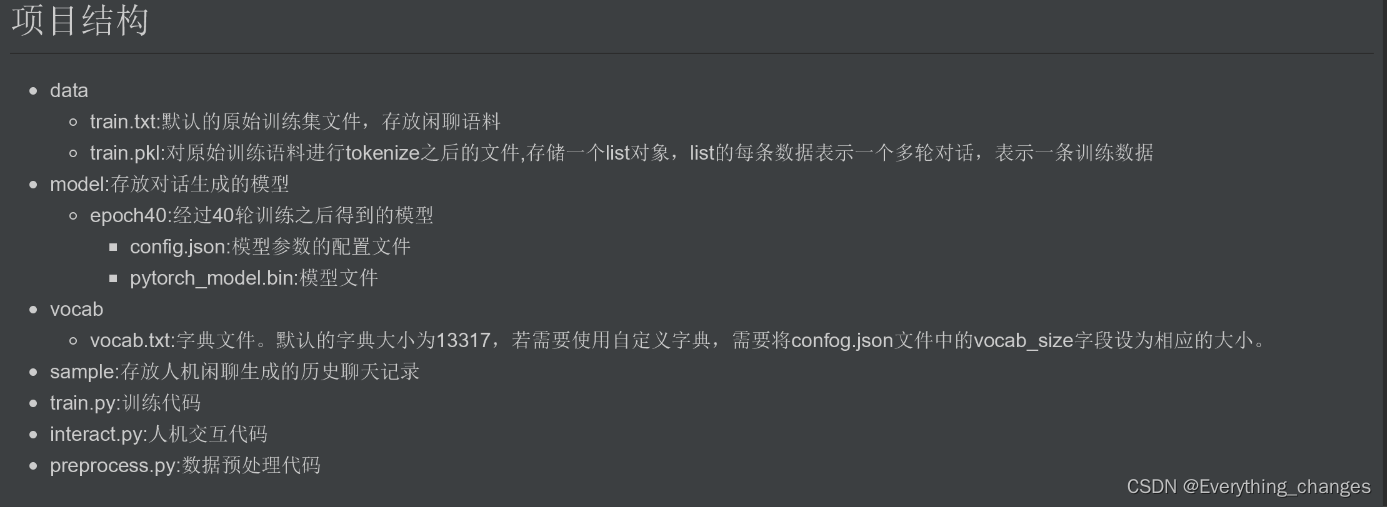
对应着左边的目录结构:
说明:data下的train.txt、train.pkl;model下的epoch40;sample是训练和预测了之后才会出现的,在下载时并没有这些文件,训练和预测下面会说。
运行环境:
文件的原始运行环境:

我的运行环境:
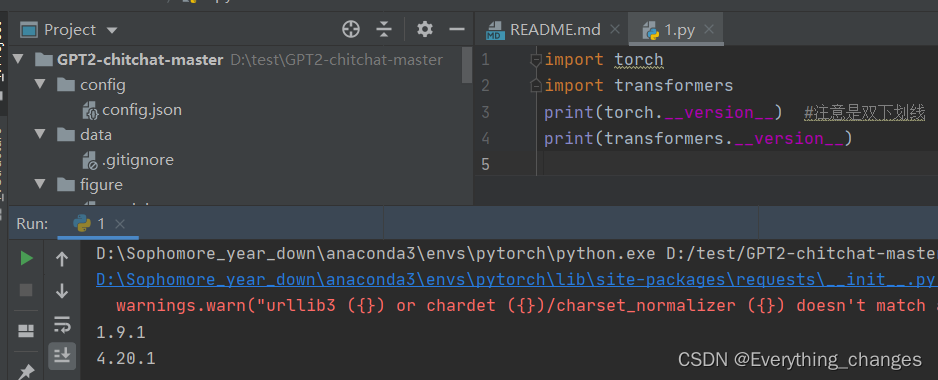
python的版本号为:3.9.7

说明:如果配置了源文本的运行环境一定是跑的出来的,当时我因为已经早就下载好了pytorch,所以我就直接下载transformer发现能运行的出来,代码能执行就是好的。
pytorch的下载参考网上的资源,挺多的帖子。
首次运行:

下载好作者训练好了的模型:
链接:https://pan.baidu.com/s/1wu1C0izDNGp0TL0A2cAdCw
提取码:20m7
说明:我只采用了百度网盘的下载,你们跟着就好了。没有用GoogleDrive下载
将下载好了的模型放入model文件下如图:
执行代码:

说明: 我用的是第一条命令行, interact.py是执行的文件, --no_cuda是用cpu来跑, model_epoch40_50w是上面下载好了的模型
在终端执行以下命令:
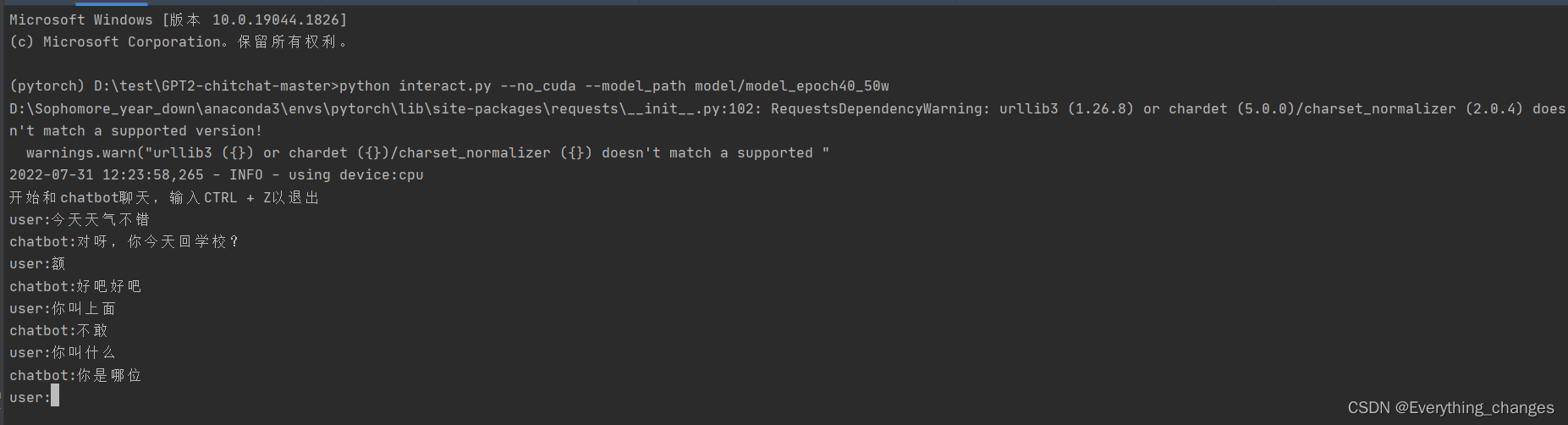
python interact.py --no_cuda --model_path model/model_epoch40_50w
注意:--model_path 不能对着README.md照抄,路径是会报错的,我上面的命令和原始文件的命令是有一点区别的。
原始文件是--model_path model_epoch40_50w
而我的是--model_path model/model_epoch40_50w
执行之后的效果为:点击图片放大查看效果!!!
如何训练自己的模型:
数据预处理:

说明:将语料放入data目录下,语料的第一行是自己说,第二行是机器人回应以此交互。中间的空白行表示一次对话结束,进行下一次的语料训练。
不同的语料训练出来的对话结果不同,区别是使用者偏向使模型想要说出自己想要的语句。
这里我提供我自己微博上爬取的语料:
链接:https://pan.baidu.com/s/1wYdH0YWJqaMukULH60LLsw
提取码:mcqb
训练模型:

说明先将:train.txt转换成train.pkl
在终端运行:
python preprocess.py --train_path data/train.txt --save_path data/train.pkl
运行结果:
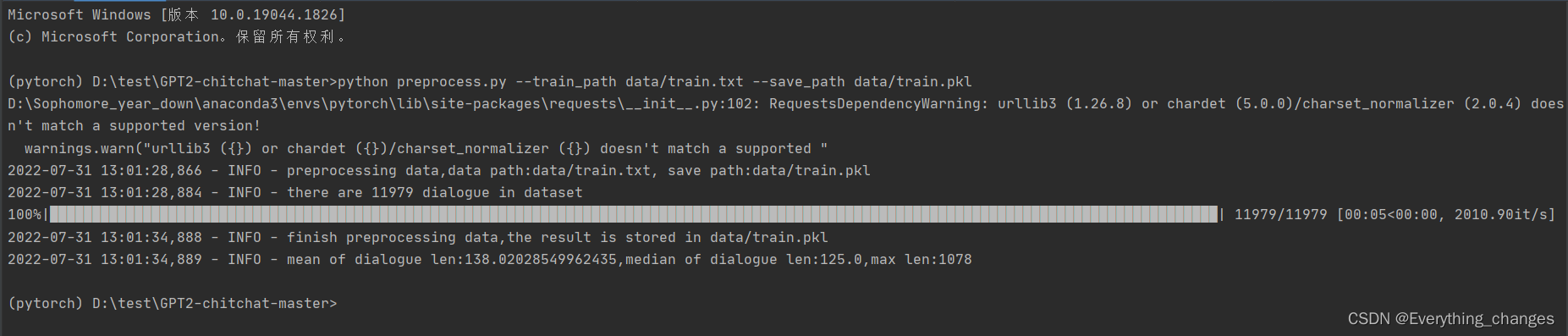
在data下生成了train.pkl文件
开始训练自己的模型:

在终端运行:
python train.py --epochs 40 --batch_size 8 --no_cuda --train_path data/train.pkl --pretrained_model model/model_epoch40_50w --val_num 11200
说明:--val_num 14000 这里的意思是将train.txt这个分为训练集:验证集=7:3
--pretrained_model 是预训练模型
如何确定这个--val_num数值:
打开train.txt文件: 数据集一共有47874行,而我的这个数据集每一次对话只有两行,再加一次空白行,那么47874/3约为16000个数据,训练集:验证集 = 7:3 得出训练集为 16000*0.7 = 11200

训练过程:

 最后说明:
最后说明:
每一次运行完一个epoch都会保存到model下面,在预测的时候直接调用model下面最后一个epoch就行,有问题可以发评论,我看见且我看得懂的话就会,哈哈哈

对python感兴趣的同学可以加我
qq进行讨论,qq:3149452335 记得备注CSDN嗷