版权声明:本文为CSDN博主「Xav Zewen」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39591031/article/details/124462430
目录
前言
问题说明
方法一:重装CUDA
方法二:手动配置
思路说明
操作步骤
参考链接
前言
参考了两篇文章以及其中的评论(链接见结尾),终于解决。这里分享一下,希望帮到后来的人。
本篇文章在下面的条件下执行(若有任何应用使用的版本不同,请在实际操作中对路径中的版本号等做相应的更改后尝试):
先下载CUDA,后下载的Visual Studio
CUDA版本11.3
VS用的是Visual Studio 2019,安装时只勾选了C++桌面开发,且使用的默认配置
问题说明
CUDA为Visual Studio提供了搭建cuda项目模板的插件,在安装CUDA时,该插件会被自动下载并配置。然而,如果是先安装CUDA后安装Visual Studio,插件不会被自动配置到VS中,而需在下载了VS后手动配置,或者干脆重装CUDA。
方法一:重装CUDA
重装CUDA很简单,首先删除NVIDIA应用中以版本号结尾的程序(比如我的是11.3)。然后重新安装一遍即可。这里建议使用geek应用来卸载,可以在卸载的同时擦除痕迹。
方法二:手动配置
思路说明
配置的大致思路是:
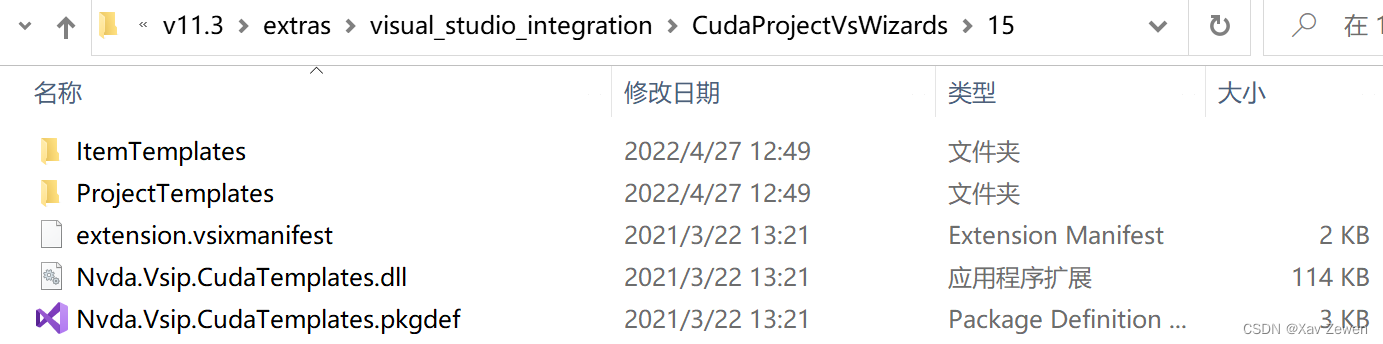
找到CUDA提供的VS模板插件
对这个存有模板的文件夹创建符号链接,链接至Visual Studio存放插件的文件夹下
更新VS的配置并重启VS
操作步骤
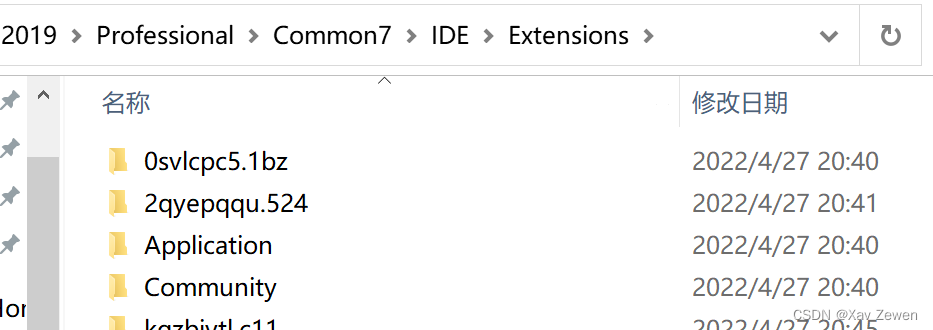
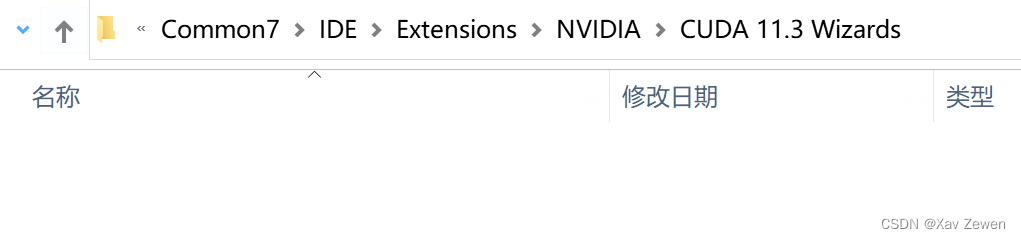
进入C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\Common7\IDE\Extensions目录,创建NVIDIA文件夹;然后进入NVIDIA文件夹,创建CUDA 11.3 Wizards文件夹
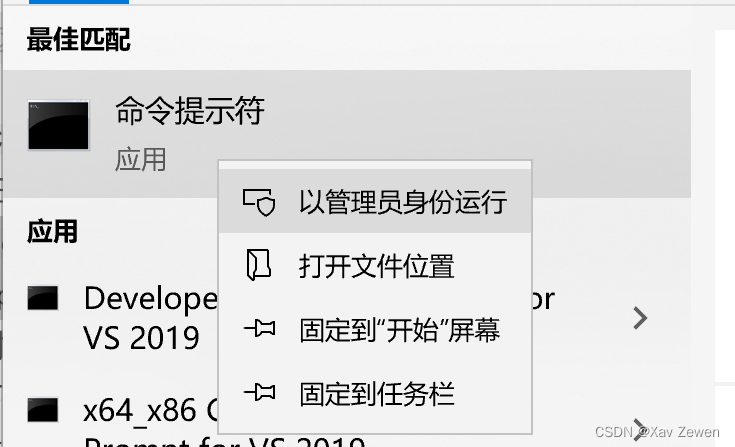
Ctrl + S打开搜索框,输入cmd,选择以管理员身份运行
在打开的命令行中,输入
mklink /d "C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\Common7\IDE\Extensions\NVIDIA\CUDA 11.3 Wizards\11.3" "C:\ProgramData\NVIDIA GPU Computing Toolkit\v11.3\extras\visual_studio_integration\CudaProjectVsWizards\15"
1
这个命令的作用是,对C:\ProgramData\NVIDIA GPU Computing Toolkit\v11.3\extras\visual_studio_integration\CudaProjectVsWizards下的15文件夹创建一个符号链接(类似创建快捷方式),创建的符号链接位于第一步中新建的CUDA 11.3 Wizards文件夹,该符号链接名为11.3。

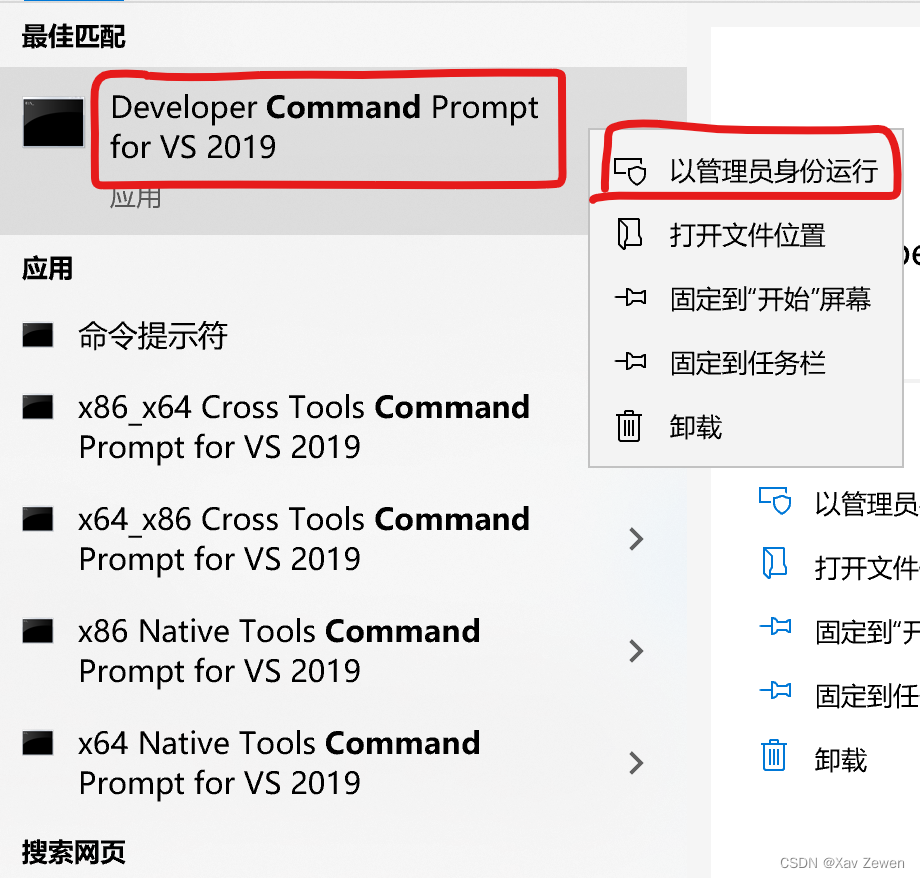
Ctrl + S打开搜索框,输入command,找到Developer Command Prompt for VS 2019,右键,选择以管理员方式运行
找到VS2019的安装位置中,2019文件夹的位置(比如我的是在C:\Program Files (x86)\Microsoft Visual Studio\2019),在命令行中输入cd <2019文件夹的路径>(如:cd C:\Program Files (x86)\Microsoft Visual Studio\2019)
然后运行devenv /updateconfiguration,等待运行完毕

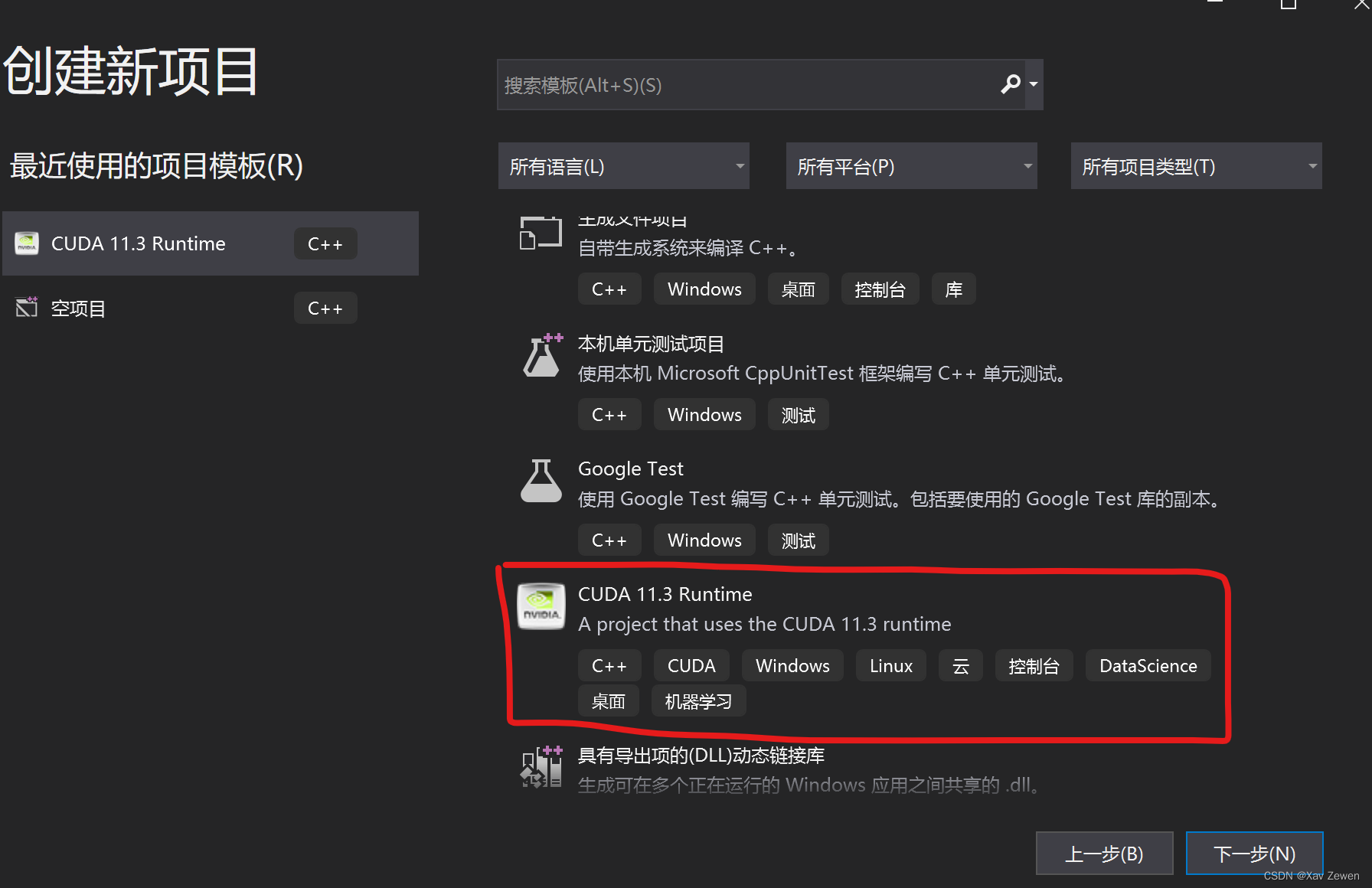
重启Visual Studio,再次创建新项目的时候应该就能看见CUDA模板了
参考链接
VS2017+CUDA9.2 新建项目里没有CUDA选项 - CSDN
Visual Studio 2022 中的 CUDA 11.6 缺少項目模板 - NVIDIA论坛
windows 软链接的建立及删除 - ChinaUnix
Win10中CUDA、cuDNN的安装与卸载 - CSDN