查询设置
增大内存
一个查询任务在单个BE结点上使用的内存默认不超过2GB,如果超过,可能会出现Memory limit exceeded。查看内存限制:
mysql> SHOW VARIABLES LIKE "%mem_limit%";
+----------------+------------+
| Variable_name | Value |
+----------------+------------+
| exec_mem_limit | 2147483648 |
| load_mem_limit | 0 |
+----------------+------------+
2 rows in set (0.00 sec)
exec_mem_limit的单位是byte,可通过set命令改变exec_mem_limit的值:
set exec_mem_limit = 8589934592;
该命令只针对当前会话,如需永久有效,则要添加global参数:
set global exec_mem_limit = 8589934592;
修改超时时间
默认最长查询时间为300s,如果超时未完成,则会被取消掉,查看配置:
mysql> SHOW VARIABLES LIKE "%query_timeout%";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| query_timeout | 300 |
+---------------+-------+
1 row in set (0.00 sec)
设置方法同exec_mem_limit。
查询重试和高可用
当部署多个FE结点时,用户可以在多个FE之上部署负载均衡层来实现Doris的高可用。
代码方式
自己在应用层代码进行重试和负载均衡。比如发现一个连接挂掉,就自动在其他连接上进行重试。应用层代码重试需要应用自己配置多个 doris 前端节点地址。
JDBC连接器
若使用MySQL的JDBC connector来连接Doris,则可以使用jdbc的自动重试机制:
jdbc:mysql://[host1][:port1],[host2][:port2][,[host3][:port3]]...[/[database]][?propertyName1=propertyValue1[&propertyName2=propertyValue2]...]
ProxySQL方式
ProxySQL是灵活强大的MySQL代理层, 是一个能实实在在用在生产环境的 MySQL 中间件,可以实现读写分离,支持Query路由功能,支持动态指定某个SQL进行cache,支持动态加载配置、故障切换和一些SQL的过滤功能。
Doris的FE进程负责接收用户连接和查询请求,其本身是可以横向扩展且高可用的,但是需要用户在多个FE上架设一层proxy,来实现自动的连接负载均衡。
首先,安装ProxySQL:
[root@scentos szc]# vim /etc/yum.repos.d/proxysql.repo
[proxysql_repo]
name= ProxySQL YUM repository
baseurl=http://repo.proxysql.com/ProxySQL/proxysql-1.4.x/centos/\$releasever
gpgcheck=1
gpgkey=http://repo.proxysql.com/ProxySQL/repo_pub_key
[root@scentos szc]# yum clean all
[root@scentos szc]# yum makecache
[root@scentos szc]# yum -y install proxysql
[root@scentos szc]# proxysql --version
ProxySQL version 1.4.16-23-gf954ef3, codename Truls
设置开机自启:
[root@scentos szc]# systemctl enable proxysql && systemctl start proxysql
启动后会监听两个端口, 默认为 6032 和 6033。6032 端口是 ProxySQL 的管理端口,6033 是 ProxySQL 对外提供服务的端口 (即连接到转发后端的真正数据库的转发端口)。
第二步,配置ProxySQL
ProxySQL有配置文件/etc/proxysql.cnf和数据库配置文件/var/lib/proxysql/proxysql.db,如果想要前者的配置在ProxySQL重启后生效,则需要在修改后删除后者,本场景下不用修改。
然后连接ProxySQL管理端口,默认用户名和密码都是admin:
[root@scentos szc]# mysql -h 127.0.0.1 -P 6032 -u admin -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.5.30 (ProxySQL Admin Module)
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
在ProxySQL中配置DorisFE,有多个插入多个即可:
mysql> insert into mysql_servers(hostgroup_id, hostname,port) values(10, 'scentos', 9030);
Query OK, 1 row affected (0.00 sec)
查看FE状态:
mysql> select * from mysql_servers\G
*************************** 1. row ***************************
hostgroup_id: 10
hostname: scentos
port: 9030
status: ONLINE
weight: 1
compression: 0
max_connections: 1000
max_replication_lag: 0
use_ssl: 0
max_latency_ms: 0
comment:
1 row in set (0.00 sec)
将FE的server配置加载到运行时,并存盘:
mysql> load mysql servers to runtime;
Query OK, 0 rows affected (0.00 sec)
mysql> save mysql servers to disk;
Query OK, 0 rows affected (0.03 sec)
监控DorisFE结点配置,首先在DorisFE主数据结点上创建一个用于监控的用户名:
mysql> create user monitor@'192.168.31.%' identified by 'monitor';
Query OK, 0 rows affected (0.01 sec)
mysql> grant ADMIN_PRIV on *.* to monitor@'192.168.31.%';
Query OK, 0 rows affected (0.02 sec)
再回到ProxySQL中配置监控:
mysql> set mysql-monitor_username='monitor';
Query OK, 1 row affected (0.00 sec)
mysql> set mysql-monitor_password='monitor';
Query OK, 1 row affected (0.00 sec)
mysql> load mysql servers to runtime;
Query OK, 0 rows affected (0.00 sec)
mysql> save mysql servers to disk;
Query OK, 0 rows affected (0.00 sec)
查看配置结果,配置监控用户名和密码前,日志中会出现Access denied错误,配置后就没有了,且新环境中的只读日志为空:
mysql> select * from mysql_server_connect_log;
+----------+------+------------------+-------------------------+------------------------------------------------------------------------+
| hostname | port | time_start_us | connect_success_time_us | connect_error |
+----------+------+------------------+-------------------------+------------------------------------------------------------------------+
| scentos | 9030 | 1652667572521858 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667632526585 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667692861809 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667752870084 | 2403 | NULL |
| scentos | 9030 | 1652667812873528 | 1959 | NULL |
+----------+------+------------------+-------------------------+------------------------------------------------------------------------+
5 rows in set (0.00 sec)
mysql> select * from mysql_server_ping_log;
+----------+------+------------------+----------------------+------------------------------------------------------------------------+
| hostname | port | time_start_us | ping_success_time_us | ping_error |
+----------+------+------------------+----------------------+------------------------------------------------------------------------+
| scentos | 9030 | 1652667523027559 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667532947750 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667543014963 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667552875834 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667562914012 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667572941974 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667582893764 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667592959601 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667603011943 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667612992504 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667622958538 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667632936523 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667642893430 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667652948737 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667662952283 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667673089193 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667682946538 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667693028613 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667702868941 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667713002938 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667722963990 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667733036470 | 0 | Access denied for user 'default_cluster:monitor' (using password: YES) |
| scentos | 9030 | 1652667743059712 | 7171 | NULL |
| scentos | 9030 | 1652667752944582 | 493 | NULL |
| scentos | 9030 | 1652667762936507 | 708 | NULL |
| scentos | 9030 | 1652667772993064 | 412 | NULL |
| scentos | 9030 | 1652667782935183 | 1395 | NULL |
| scentos | 9030 | 1652667792877624 | 436 | NULL |
| scentos | 9030 | 1652667803030817 | 409 | NULL |
| scentos | 9030 | 1652667812902970 | 643 | NULL |
| scentos | 9030 | 1652667823086544 | 407 | NULL |
| scentos | 9030 | 1652667832999904 | 400 | NULL |
| scentos | 9030 | 1652667843080748 | 375 | NULL |
| scentos | 9030 | 1652667853084720 | 374 | NULL |
| scentos | 9030 | 1652667862940854 | 409 | NULL |
| scentos | 9030 | 1652667872944847 | 432 | NULL |
| scentos | 9030 | 1652667882914813 | 450 | NULL |
+----------+------+------------------+----------------------+------------------------------------------------------------------------+
37 rows in set (0.00 sec)
mysql> select * from mysql_server_read_only_log;
Empty set (0.00 sec)
mysql> load mysql servers to runtime;
Query OK, 0 rows affected (0.00 sec)
mysql> save mysql servers to disk;
Query OK, 0 rows affected (0.07 sec)
mysql> select hostgroup_id,hostname,port,status,weight from mysql_servers;
+--------------+----------+------+--------+--------+
| hostgroup_id | hostname | port | status | weight |
+--------------+----------+------+--------+--------+
| 10 | scentos | 9030 | ONLINE | 1 |
+--------------+----------+------+--------+--------+
1 row in set (0.00 sec)
然后是配置Doris用户,包括发送SQL语句的用户、SQL语句的路由规则、SQL查询的缓存、SQL语句的重写等。假设Doris端有用户root,则在ProxySQL中进行如下配置:
mysql> insert into mysql_users(username,password,default_hostgroup) values('root','root',10);
Query OK, 1 row affected (0.00 sec)
mysql> load mysql users to runtime;
Query OK, 0 rows affected (0.00 sec)
mysql> save mysql users to disk;
Query OK, 0 rows affected (0.00 sec)
查看结果:
mysql> select * from mysql_users\G
*************************** 1. row ***************************
username: root
password: root
active: 1
use_ssl: 0
default_hostgroup: 10
default_schema: NULL
schema_locked: 0
transaction_persistent: 1
fast_forward: 0
backend: 1
frontend: 1
max_connections: 10000
1 row in set (0.00 sec)
确保active和transaction_persistent字段为1,然后配置参数mysql-forward_autocommit和mysql-autocommit_false_is_transaction:
mysql> UPDATE global_variables SET variable_value='true' WHERE variable_name='mysql-forward_autocommit';
Query OK, 1 row affected (0.01 sec)
mysql> UPDATE global_variables SET variable_value='true' WHERE variable_name='mysql-autocommit_false_is_transaction';
Query OK, 1 row affected (0.00 sec)
mysql> load mysql VARIABLES to runtime;
Query OK, 0 rows affected (0.00 sec)
mysql> save mysql VARIABLES to disk;
Query OK, 98 rows affected (0.09 sec)
这样就可以在MySQL中以root的用户名密码连接ProxySQL了。
第三步,测试:
[root@scentos szc]# mysql -uroot -proot -P 6033 -h scentos -e "show databases;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| test |
+--------------------+
简单查询
基本查询
mysql> SELECT * FROM example_site_visit LIMIT 3;
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| user_id | date | city | age | sex | last_visit_date | last_visit_date_not_null | cost | max_dwell_time | min_dwell_time |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 11:22:00 | 2017-10-03 10:20:22 | 55 | 19 | 6 |
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
3 rows in set (0.12 sec)
mysql> SELECT * FROM example_site_visit ORDER BY user_id;
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| user_id | date | city | age | sex | last_visit_date | last_visit_date_not_null | cost | max_dwell_time | min_dwell_time |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2017-10-01 07:00:00 | 2 | 22 | 22 |
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | NULL | 200 | 5 | 5 |
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 11:22:00 | 2017-10-03 10:20:22 | 55 | 19 | 6 |
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
| 10005 | 2017-10-03 | 长沙 | 29 | 1 | 2017-10-03 18:11:02 | 2017-10-03 18:11:02 | 3 | 1 | 1 |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
7 rows in set (0.03 sec)
联合(join)查询
mysql> SELECT SUM(example_site_visit.cost) FROM example_site_visit JOIN example_site_visit2 WHERE example_site_visit.user_id = example_site_visit2.user_id;
+----------------------------------+
| sum(`example_site_visit`.`cost`) |
+----------------------------------+
| 612 |
+----------------------------------+
1 row in set (0.12 sec)
mysql> select example_site_visit.user_id, sum(example_site_visit.cost) from example_site_visit join example_site_visit2 where example_site_visit.user_id = example_site_visit2.user_id group by example_site_visit.user_id;
+---------+----------------------------------+
| user_id | sum(`example_site_visit`.`cost`) |
+---------+----------------------------------+
| 10004 | 310 |
| 10000 | 70 |
| 10001 | 2 |
| 10002 | 200 |
| 10003 | 30 |
+---------+----------------------------------+
5 rows in set (0.16 sec)
子查询
mysql> SELECT SUM(cost) FROM example_site_visit2 WHERE user_id IN (SELECT user_id FROM example_site_visit WHERE user_id > 10003);
+-------------+
| sum(`cost`) |
+-------------+
| 111 |
+-------------+
1 row in set (0.07 sec)
Join查询
广播Join
系统默认实现Join的方式,是将小表进行条件过滤后,将其广播到大表所在的各个节点上,形成一个内存Hash表,然后流式读出大表的数据进行Hash Join。Doris会自动尝试进行Broadcast Join,如果预估小表过大则会自动切换至Shuffle Join。注意,如果此时显式指定了Broadcast Join也会自动切换至Shuffle Join。
默认使用 Broadcast Join
mysql> EXPLAIN SELECT SUM(example_site_visit.cost) FROM example_site_visit JOIN example_site_visit2 WHERE example_site_visit.city = example_site_visit2.city;
+---------------------------------------------------------------------------------------+
| Explain String |
+---------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 4> sum(`example_site_visit`.`cost`) |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 6:AGGREGATE (merge finalize) |
| | output: sum(<slot 3> sum(`example_site_visit`.`cost`)) |
| | group by: |
| | cardinality=-1 |
| | |
| 5:EXCHANGE |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit`.`user_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 05 |
| UNPARTITIONED |
| |
| 3:AGGREGATE (update serialize) |
| | output: sum(`example_site_visit`.`cost`) |
| | group by: |
| | cardinality=1 |
| | |
| 2:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: Tables are not in the same group |
| | equal join conjunct: `example_site_visit`.`city` = `example_site_visit2`.`city` |
| | runtime filters: RF000[in] <- `example_site_visit2`.`city` |
| | cardinality=7 |
| | |
| |----4:EXCHANGE |
| | |
| 0:OlapScanNode |
| TABLE: example_site_visit |
| PREAGGREGATION: ON |
| runtime filters: RF000[in] -> `example_site_visit`.`city` |
| partitions=1/1 |
| rollup: example_site_visit |
| tabletRatio=10/10 |
| tabletList=10231,10233,10235,10237,10239,10241,10243,10245,10247,10249 |
| cardinality=7 |
| avgRowSize=1496.4286 |
| numNodes=1 |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit2`.`user_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 1:OlapScanNode |
| TABLE: example_site_visit2 |
| PREAGGREGATION: OFF. Reason: null |
| partitions=1/1 |
| rollup: example_site_visit2 |
| tabletRatio=10/10 |
| tabletList=10255,10257,10259,10261,10263,10265,10267,10269,10271,10273 |
| cardinality=6 |
| avgRowSize=1358.0 |
| numNodes=1 |
+---------------------------------------------------------------------------------------+
66 rows in set (0.00 sec)
显式使用 Broadcast Join
mysql> EXPLAIN SELECT SUM(example_site_visit.cost) FROM example_site_visit JOIN [broadcast] example_site_visit2 WHERE example_site_visit.city = example_site_visit2.city;
+---------------------------------------------------------------------------------------+
| Explain String |
+---------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 4> sum(`example_site_visit`.`cost`) |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 6:AGGREGATE (merge finalize) |
| | output: sum(<slot 3> sum(`example_site_visit`.`cost`)) |
| | group by: |
| | cardinality=-1 |
| | |
| 5:EXCHANGE |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit`.`user_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 05 |
| UNPARTITIONED |
| |
| 3:AGGREGATE (update serialize) |
| | output: sum(`example_site_visit`.`cost`) |
| | group by: |
| | cardinality=1 |
| | |
| 2:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: Has join hint |
| | equal join conjunct: `example_site_visit`.`city` = `example_site_visit2`.`city` |
| | runtime filters: RF000[in] <- `example_site_visit2`.`city` |
| | cardinality=7 |
| | |
| |----4:EXCHANGE |
| | |
| 0:OlapScanNode |
| TABLE: example_site_visit |
| PREAGGREGATION: ON |
| runtime filters: RF000[in] -> `example_site_visit`.`city` |
| partitions=1/1 |
| rollup: example_site_visit |
| tabletRatio=10/10 |
| tabletList=10231,10233,10235,10237,10239,10241,10243,10245,10247,10249 |
| cardinality=7 |
| avgRowSize=1496.4286 |
| numNodes=1 |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit2`.`user_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 1:OlapScanNode |
| TABLE: example_site_visit2 |
| PREAGGREGATION: OFF. Reason: null |
| partitions=1/1 |
| rollup: example_site_visit2 |
| tabletRatio=10/10 |
| tabletList=10255,10257,10259,10261,10263,10265,10267,10269,10271,10273 |
| cardinality=6 |
| avgRowSize=1358.0 |
| numNodes=1 |
+---------------------------------------------------------------------------------------+
66 rows in set (0.00 sec)
混洗Join
如果当小表过滤后的数据量无法放入内存的话,此时Join将无法完成,通常的报错应该是首先造成内存超限。可以显式指定Shuffle Join,也被称作Partitioned Join。即将小表和大表都按照Join的key进行Hash,然后进行分布式的Join,此时对内存的消耗就会分摊到集群的所有计算节点上:
mysql> SELECT SUM(example_site_visit.cost) FROM example_site_visit JOIN [shuffle] example_site_visit2 WHERE example_site_visit.city = example_site_visit2.city;
+----------------------------------+
| sum(`example_site_visit`.`cost`) |
+----------------------------------+
| 651 |
+----------------------------------+
1 row in set (0.16 sec)
Colocation Join
Colocation Join是在Doris0.9版本引入的功能,旨在为Join查询提供本性优化,来减少数据在节点上的传输耗时,加速查询。
原理
Colocation Join功能,是将一组拥有CGS的表组成一个CG。保证这些表对应的数据分片会落在同一个be节点上,那么使得两表再进行join的时候,可以通过本地数据进行直接join,减少数据在节点之间的网络传输时间。
Colocation Group(CG)
一个CG中会包含一张及以上的Table。在同一个 Group内的Table有着相同的Colocation Group Schema,并且有着相同的数据分片分布。
Colocation Group Schema(CGS)
用于描述一个CG 中的Table,和Colocation相关的通用Schema信息。包括分桶列类型,分桶数以及副本数等。
一个表的数据,最终会根据分桶列值Hash、对桶数取模的后落在某一个分桶内。假设一个 Table 的分桶数为8,则共有[0, 1, 2, 3, 4, 5, 6, 7]8个分桶(Bucket)我们称这样一个序列为一个 BucketsSequence,每个Bucket内会有一个或多个数据分片(Tablet)。当表为单分区表时,一个Bucket内仅有一个Tablet。如果是多分区表,则会有多个。
使用限制
(1)建表时两张表的分桶列的类型和数量需要完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制;
(2)同一个CG内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个Tablet的某一个副本,在同一个 BE 上没有其他的表分片的副本对应;
(3)同一个CG内的表,分区的个数、范围以及分区列的类型不要求一致。
使用
建表
先建两张表,分桶列都是int类型,且桶数都为8:
CREATE TABLE `tbl1_j` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1",
"replication_num" = "1",
"storage_medium" = "SSD"
);
CREATE TABLE `tbl2_j` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1",
"replication_num" = "1",
"storage_medium" = "SSD"
);
查询
编写查询语句,查看执行计划:
mysql> explain SELECT * FROM tbl1_j INNER JOIN tbl2_j ON (tbl1_j.k2 = tbl2_j.k2)\G
*************************** 1. row ***************************
Explain String: PLAN FRAGMENT 0
*************************** 2. row ***************************
Explain String: OUTPUT EXPRS:`default_cluster:test`.`tbl1_j`.`k1` | `default_cluster:test`.`tbl1_j`.`k2` | `default_cluster:test`.`tbl1_j`.`v1` | `default_cluster:test`.`tbl2_j`.`k1` | `default_cluster:test`.`tbl2_j`.`k2` | `default_cluster:test`.`tbl2_j`.`v1`
*************************** 3. row ***************************
Explain String: PARTITION: HASH_PARTITIONED: `default_cluster:test`.`tbl1_j`.`k2`
*************************** 4. row ***************************
Explain String:
*************************** 5. row ***************************
Explain String: RESULT SINK
*************************** 6. row ***************************
Explain String:
*************************** 7. row ***************************
Explain String: 2:HASH JOIN
*************************** 8. row ***************************
Explain String: | join op: INNER JOIN
*************************** 9. row ***************************
Explain String: | hash predicates:
*************************** 10. row ***************************
Explain String: | colocate: true
*************************** 11. row ***************************
Explain String: | equal join conjunct: (`tbl1_j`.`k2` = `tbl2_j`.`k2`)
*************************** 12. row ***************************
Explain String: | runtime filters: RF000[in] <- `tbl2_j`.`k2`
*************************** 13. row ***************************
Explain String: | cardinality=0
*************************** 14. row ***************************
Explain String: |
*************************** 15. row ***************************
Explain String: |----1:OlapScanNode
*************************** 16. row ***************************
Explain String: | TABLE: tbl2_j
*************************** 17. row ***************************
Explain String: | PREAGGREGATION: OFF. Reason: null
*************************** 18. row ***************************
Explain String: | partitions=0/1
*************************** 19. row ***************************
Explain String: | rollup: null
*************************** 20. row ***************************
Explain String: | tabletRatio=0/0
*************************** 21. row ***************************
Explain String: | tabletList=
*************************** 22. row ***************************
Explain String: | cardinality=0
*************************** 23. row ***************************
Explain String: | avgRowSize=28.0
*************************** 24. row ***************************
Explain String: | numNodes=1
*************************** 25. row ***************************
Explain String: |
*************************** 26. row ***************************
Explain String: 0:OlapScanNode
*************************** 27. row ***************************
Explain String: TABLE: tbl1_j
*************************** 28. row ***************************
Explain String: PREAGGREGATION: OFF. Reason: No AggregateInfo
*************************** 29. row ***************************
Explain String: runtime filters: RF000[in] -> `tbl1_j`.`k2`
*************************** 30. row ***************************
Explain String: partitions=0/2
*************************** 31. row ***************************
Explain String: rollup: null
*************************** 32. row ***************************
Explain String: tabletRatio=0/0
*************************** 33. row ***************************
Explain String: tabletList=
*************************** 34. row ***************************
Explain String: cardinality=0
*************************** 35. row ***************************
Explain String: avgRowSize=24.0
*************************** 36. row ***************************
Explain String: numNodes=1
36 rows in set (0.01 sec)
查看group
mysql> SHOW PROC '/colocation_group';
+-------------+--------------+--------------+------------+-------------------------+----------+----------+----------+
| GroupId | GroupName | TableIds | BucketsNum | ReplicaAllocation | DistCols | IsStable | ErrorMsg |
+-------------+--------------+--------------+------------+-------------------------+----------+----------+----------+
| 10003.13036 | 10003_group1 | 13034, 13070 | 8 | tag.location.default: 1 | int(11) | true | |
+-------------+--------------+--------------+------------+-------------------------+----------+----------+----------+
1 row in set (0.00 sec)
删除group
当Group中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过DROP TABLE命令删除后,会在回收站默认停留一天的时间后,再删除),该Group也会被自动删除。
修改表的colocate组
mysql> ALTER TABLE tbl1_j SET ("colocate_with" = "group2");
Query OK, 0 rows affected (0.00 sec)
如果该表之前没有指定过Group,则该命令检查Schema,并将该表加入到该Group(Group 不存在则会创建);
如果该表之前有指定其他Group,则该命令会先将该表从原有Group中移除,并加入新Group(Group 不存在则会创建)。
删除表的colocate组
ALTER TABLE tbl SET ("colocate_with" = "");
另外,当对一个具有Colocation属性的表进行增加分区(ADD PARTITION)、修改副本数时,Doris会检查修改是否会违反Colocation Group Schema,如果违反则会拒绝。
桶混洗Join
Bucket Shuffle Join是在Doris 0.14版本中正式加入的新功能,旨在为某些Join查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询。
原理
Doris支持的常规分布式Join方式包括了shuffle join和broadcast join。这两种join都会导致不小的网络开销.
举个例子,当前存在A表与B表的Join查询,它的Join方式为HashJoin,不同Join类型的开销如下:
-
Broadcast Join: 如果根据数据分布,查询规划出A表有3个执行的HashJoinNode,那么需要将B表全量地发送到3个HashJoinNode,那么它的网络开销是3B,它的内存开销也是3B;
-
Shuffle Join: Shuffle Join会将A、B两张表的数据根据哈希计算分散到集群的节点之中,所以它的网络开销为A + B,内存开销为B。
在FE之中保存了Doris每个表的数据分布信息,如果join语句命中了表的数据分布列,使用数据分布信息来减少join语句的网络与内存开销,这就是Bucket Shuffle Join,原理如下图:
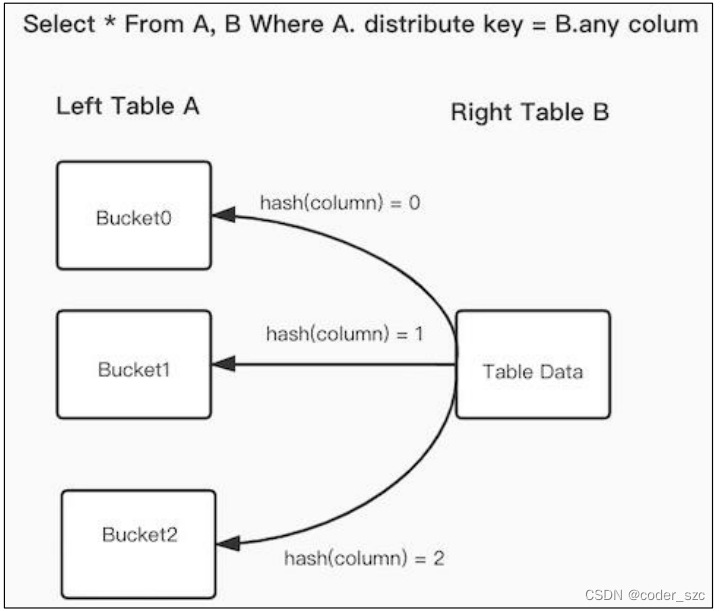
SQL语句为A表join B表,并且join的等值表达式命中了A的数据分布列。而Bucket Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储计算节点。Bucket Shuffle Join开销如下:
- 网络开销: B < min(3B, A + B);
- 内存开销: B <= min(3B, B)。
可见,相比于Broadcast Join与Shuffle Join,Bucket Shuffle Join有着较为明显的性能优势,减少数据在节点间的传输耗时和Join时的内存开销。相对于 Doris 原有的Join方式,它有着下面的优点:
-
Bucket-Shuffle-Join降低了网络与内存开销,使一些Join查询具有了更好的性能,尤其是当 FE 能够执行左表的分区裁剪与桶裁剪时;
- 与
Colocate Join不同,它对于表的数据分布方式并没有侵入性,这对于用户来说是透明的,对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题;
- 它可以为
Join Reorder提供更多可能的优化空间。
使用
首先,查看并设置变量:
mysql> show variables like '%bucket_shuffle_join%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| enable_bucket_shuffle_join | true |
+----------------------------+-------+
1 row in set (0.00 sec)
mysql> set enable_bucket_shuffle_join = true;
在FE进行分布式查询规划时,优先选择的顺序为Colocate Join -> Bucket Shuffle Join ->Broadcast Join -> Shuffle Join。但是如果用户显式指定了 Join 的类型,则以上优先级无效,如:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
可以通过explain查看join类型:
mysql> EXPLAIN SELECT SUM(example_site_visit.cost) FROM example_site_visit JOIN example_site_visit2 ON example_site_visit.user_id = example_site_visit2.user_id;
+--------------------------------------------------------------------------------------------+
| Explain String |
+--------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 4> sum(`example_site_visit`.`cost`) |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 6:AGGREGATE (merge finalize) |
| | output: sum(<slot 3> sum(`example_site_visit`.`cost`)) |
| | group by: |
| | cardinality=-1 |
| | |
| 5:EXCHANGE |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit`.`user_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 05 |
| UNPARTITIONED |
| |
| 3:AGGREGATE (update serialize) |
| | output: sum(`example_site_visit`.`cost`) |
| | group by: |
| | cardinality=1 |
| | |
| 2:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
| | hash predicates: |
| | colocate: false, reason: Tables are not in the same group |
| | equal join conjunct: `example_site_visit`.`user_id` = `example_site_visit2`.`user_id` |
| | runtime filters: RF000[in] <- `example_site_visit2`.`user_id` |
| | cardinality=7 |
| | |
| |----4:EXCHANGE |
| | |
| 0:OlapScanNode |
| TABLE: example_site_visit |
| PREAGGREGATION: ON |
| runtime filters: RF000[in] -> `example_site_visit`.`user_id` |
| partitions=1/1 |
| rollup: example_site_visit |
| tabletRatio=10/10 |
| tabletList=10231,10233,10235,10237,10239,10241,10243,10245,10247,10249 |
| cardinality=7 |
| avgRowSize=1496.4286 |
| numNodes=1 |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit2`.`user_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| BUCKET_SHFFULE_HASH_PARTITIONED: `example_site_visit2`.`user_id` |
| |
| 1:OlapScanNode |
| TABLE: example_site_visit2 |
| PREAGGREGATION: OFF. Reason: null |
| partitions=1/1 |
| rollup: example_site_visit2 |
| tabletRatio=10/10 |
| tabletList=10255,10257,10259,10261,10263,10265,10267,10269,10271,10273 |
| cardinality=6 |
| avgRowSize=1358.0 |
| numNodes=1 |
+--------------------------------------------------------------------------------------------+
66 rows in set (0.00 sec)
注意事项
(1)Bucket Shuffle Join只生效于 Join 条件为等值的场景,原因与Colocate Join类似,它们都依赖hash来计算确定的数据分布;
(2)在等值Join条件之中包含两张表的分桶列,当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join;
(3)由于不同的数据类型的hash值计算结果不同,所以Bucket Shuffle Join要求左表的分桶列的类型与右表等值join列的类型需要保持一致,否则无法进行对应的规划;
(4)Bucket Shuffle Join只作用于Doris原生的OLAP表,对于ODBC、MySQL、ES 等外表,当其作为左表时是无法规划生效的;
(5)对于分区表,由于每一个分区的数据分布规则可能不同,所以Bucket Shuffle Join只能保证左表为单分区时生效。所以在SQL 执行之中,需要尽量使用where条件使分区裁剪的策略能够生效;
(6)假如左表为Colocate表,那么它每个分区的数据分布规则是确定的,BucketShuffle Join能在Colocate 表上表现更好。
运行时过滤
Runtime Filter是在Doris 0.15版本中正式加入的新功能,旨在为某些Join查询在运行时动态生成过滤条件,来减少扫描的数据量,避免不必要的I/O和网络传输,从而加速查询。
原理
Runtime Filter在查询规划时生成,在HashJoinNode中构建,在ScanNode中应用。
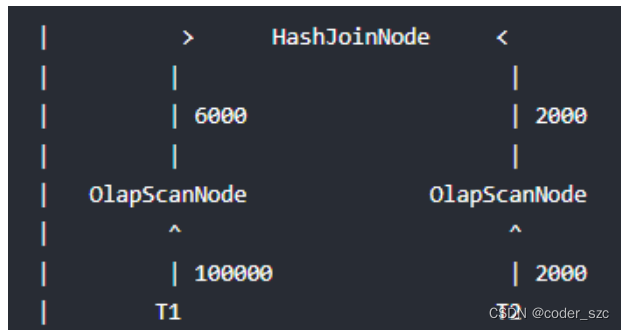
举个例子,当前存在T1表与T2表的Join 查询,它的 Join 方式为HashJoin,T1是一张事实表,数据行数为100000,T2是一张维度表,数据行数为2000,Doris join的实际情况是:

显而易见对T2扫描数据要远远快于T1,如果我们主动等待一段时间再扫描T1,等T2将扫描的数据记录交给HashJoinNode后,HashJoinNode根据T2的数据计算出一个过滤条件,比如T2数据的最大和最小值,或者构建一个Bloom Filter,接着将这个过滤条件发给等待扫描T1的ScanNode,后者应用这个过滤条件,将过滤后的数据交给HashJoinNode,从而减少probe hash table的次数和网络开销,这个过滤条件就是Runtime Filter,效果如下:
如果能将过滤条件(Runtime Filter)下推到存储引擎,则某些情况下可以利用索引来直接减少扫描的数据量,从而大大减少扫描耗时,效果如下:
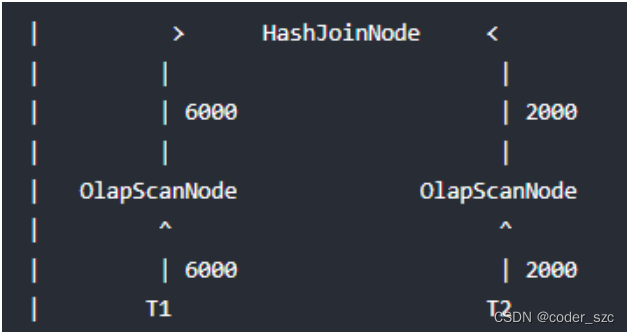
可见,和谓词下推、分区裁剪不同,Runtime Filter是在运行时动态生成的过滤条件,即在查询运行时解析join on clause确定过滤表达式,并将表达式广播给正在读取左表的ScanNode,从而减少扫描的数据量,进而减少probe hash table的次数,避免不必要的I/O和网络传输。
Runtime Filter主要用于优化针对大表的join,如果左表的数据量太小,或者右表的数据量太大,则Runtime Filter可能不会取得预期效果。
使用
首先指定运行过滤器的类型:
mysql> set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
Query OK, 0 rows affected (0.00 sec)
然后建表,插数据:
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2 PROPERTIES("replication_num" = "1", "storage_medium" = "SSD");
INSERT INTO test VALUES (1), (2), (3), (4);
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2 PROPERTIES("replication_num" = "1", "storage_medium" = "SSD");
INSERT INTO test2 VALUES (3), (4), (5);
查看执行计划:
mysql> EXPLAIN SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
+---------------------------------------------------------------------------------------------------------------+
| Explain String |
+---------------------------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:`t1` |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 4:EXCHANGE |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`test`.`t1` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 2:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
| | hash predicates: |
| | colocate: false, reason: Tables are not in the same group |
| | equal join conjunct: `test`.`t1` = `test2`.`t2` |
| | runtime filters: RF000[in] <- `test2`.`t2`, RF001[bloom] <- `test2`.`t2`, RF002[min_max] <- `test2`.`t2` |
| | cardinality=0 |
| | |
| |----3:EXCHANGE |
| | |
| 0:OlapScanNode |
| TABLE: test |
| PREAGGREGATION: ON |
| runtime filters: RF000[in] -> `test`.`t1`, RF001[bloom] -> `test`.`t1`, RF002[min_max] -> `test`.`t1` |
| partitions=1/1 |
| rollup: test |
| tabletRatio=2/2 |
| tabletList=13092,13094 |
| cardinality=0 |
| avgRowSize=4.0 |
| numNodes=1 |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`test2`.`t2` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 03 |
| BUCKET_SHFFULE_HASH_PARTITIONED: `test2`.`t2` |
| |
| 1:OlapScanNode |
| TABLE: test2 |
| PREAGGREGATION: ON |
| partitions=1/1 |
| rollup: test2 |
| tabletRatio=2/2 |
| tabletList=13099,13101 |
| cardinality=0 |
| avgRowSize=4.0 |
| numNodes=1 |
+---------------------------------------------------------------------------------------------------------------+
56 rows in set (0.00 sec)
可以看到,HASH JOIN生成了ID为RF000的IN predicate,其中`test2`.`t2`的key values 仅在运行时可知,在OlapScanNode使用该IN predicate以便在读取`test`.`t1`时过滤不必要的数据。
通过profile查看效果:
mysql> set enable_profile=true;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
+------+
| t1 |
+------+
| 3 |
| 4 |
+------+
2 rows in set (0.05 sec)
然后可以在http://scentos:8030/QueryProfile/上查看执行效果,如下所示:
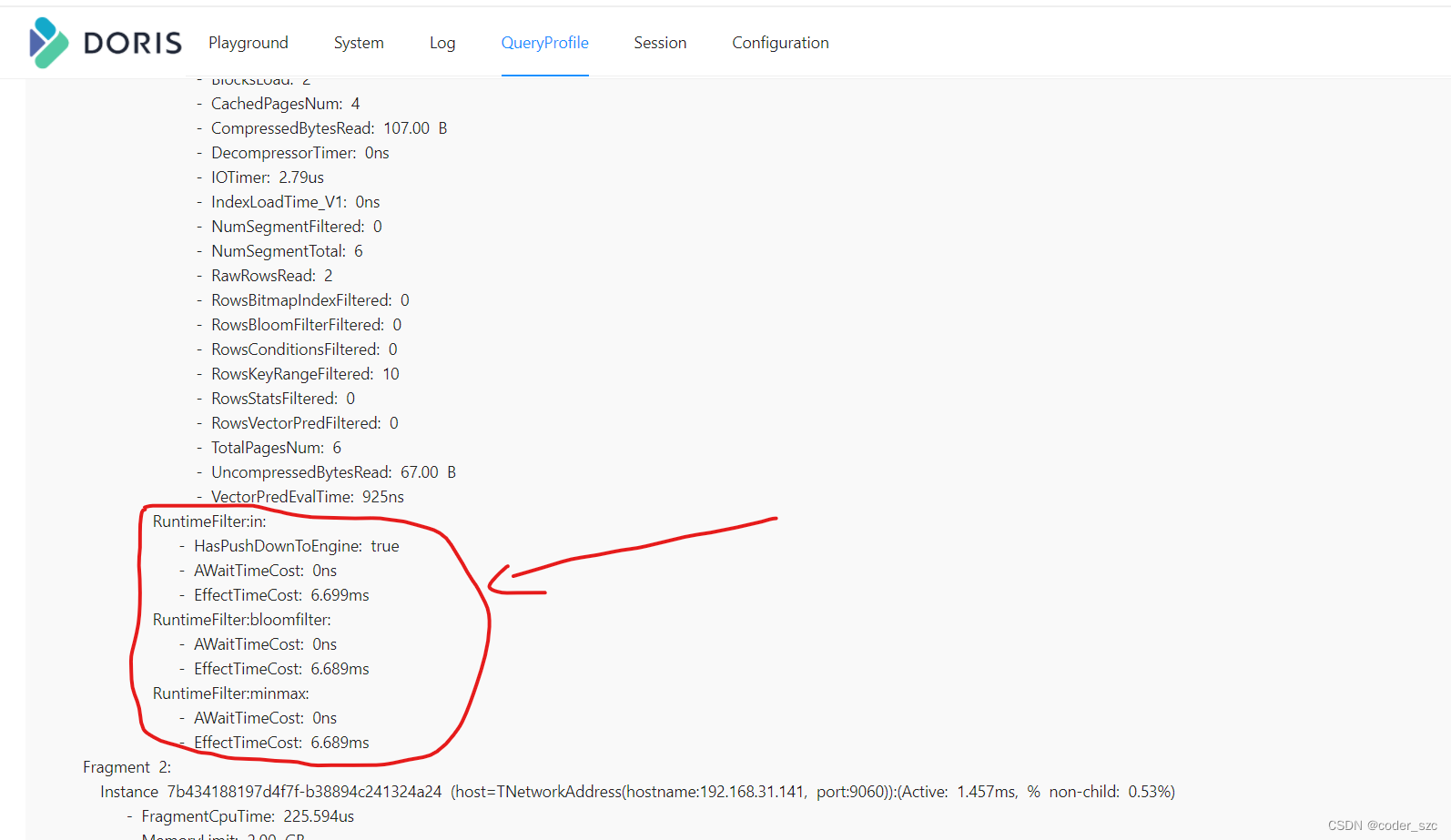
可以看到每个Runtime Filter是否下推、等待耗时、以及OLAP_SCAN_NODE从prepare到接收到Runtime Filter的总时长:
RuntimeFilter:in:
- HasPushDownToEngine: true
- AWaitTimeCost: 0ns
- EffectTimeCost: 6.699ms
-
在profile的OLAP_SCAN_NODE 中可以查看Runtime Filter下推后的过滤效果和耗时:
- RowsVectorPredFiltered: 0
....
- VectorPredEvalTime: 346ns
具体参数说明
大多数情况下,只需要调整runtime_filter_type选项,其他选项保持默认即可: 包括BLOOM_FILTER、IN、MIN_MAX(也可以通过数字设置),默认会使用IN,部分情况下同时使用Bloom Filter、MinMax Filter、IN predicate时性能更高,每个类型含义如下:
(1)Bloom Filter: 有一定的误判率,导致过滤的数据比预期少一点,但不会导致最终结果不准确,在大部分情况下Bloom Filter都可以提升性能或对性能没有显著影响,但在部分情况下会导致性能降低。
Bloom Filter构建和应用的开销较高,所以当过滤率较低时,或者左表数据量较少时,Bloom Filter可能会导致性能降低;
目前只有左表的Key列应用Bloom Filter才能下推到存储引擎,而测试结果显示Bloom Filter不下推到存储引擎时往往会导致性能降低;
目前Bloom Filter仅在ScanNode上使用表达式过滤时有短路(short-circuit)逻辑,即当假阳性率(实际是假但误辨为真的情况)过高时,不继续使用Bloom Filter,但当Bloom Filter下推到存储引擎后没有短路逻辑,所以当过滤率较低时可能导致性能降低。
(2)MinMax Filter: 包含最大值和最小值,从而过滤小于最小值和大于最大值的数据,MinMax Filter的过滤效果与join on clause中Key列的类型和左右表数据分布有关:
当join on clause中Key 列的类型为int/bigint/double等时,极端情况下,如果左右表的最大最小值相同则没有效果,反之右表最大值小于左表最小值,或右表最小值大于左表最大值,则效果最好;
当join on clause中Key 列的类型为varchar等时,应用MinMax Filter往往会导致性能降低。
(3)IN predicate: 根据join on clause中Key列在右表上的所有值构建IN predicate,使用构建的IN predicate在左表上过滤,相比Bloom Filter构建和应用的开销更低,在右表数据量较少时往往性能更高:
默认只有右表数据行数少于1024才会下推(可通过session变量中的runtime_filter_max_in_num调整);
目前IN predicate已实现合并方法;
当同时指定In predicate和其他filter,并且in的过滤数值没达到runtime_filter_max_in_num时,会尝试把其他filter去除掉。原因是In predicate是精确的过滤条件,即使没有其他filter也可以高效过滤,如果同时使用则其他filter会做无用功。目前仅在Runtime filter的生产者和消费者处于同一个fragment时才会有去除非in filter的逻辑。
其他查询选项通常仅在某些特定场景下,才需进一步调整以达到最优效果。通常只在性能测试后,针对资源密集型、运行耗时足够长且频率足够高的查询进行优化:
runtime_filter_mode: 用于调整Runtime Filter的下推策略,包括OFF、LOCAL、GLOBAL三种策略,默认设置为GLOBAL策略;
runtime_filter_wait_time_ms: 左表的ScanNode等待每个Runtime Filter的时间,默认1000ms;
runtime_filters_max_num: 每个查询可应用的Runtime Filter中Bloom Filter的最大数量,默认10;
runtime_bloom_filter_min_size: Runtime Filter中Bloom Filter的最小长度,默认1048576(1M);
runtime_bloom_filter_max_size: Runtime Filter中Bloom Filter的最大长度,默认16777216(16M);
runtime_bloom_filter_size: Runtime Filter中Bloom Filter的默认长度,默认2097152(2M);
runtime_filter_max_in_num: 如 join右表数据行数大于这个值,我们将不生成IN predicate,默认 1024。
注意事项
(1)只支持对join on clause中的等值条件生成Runtime Filter,不包括Null-safe条件,因为其可能会过滤掉join左表的null值;
(2)不支持将Runtime Filter下推到left outer、full outer、anti join的左表;
(3)不支持src expr或target expr是常量;
(4)不支持src expr和target expr相等;
(5)不支持src expr的类型等于HLL或者BITMAP;
(6)目前仅支持将Runtime Filter下推给OlapScanNode;
(7)不支持target expr包含NULL-checking表达式,比如COALESCE/IFNULL/CASE,因为当outer join上层其他join的join on clause包含NULL-checking表达式并生成Runtime Filter时,将这个Runtime Filter下推到outer join的左表时可能导致结果不正确;
(8)不支持target expr 中的列(slot)无法在原始表中找到某个等价列;
(9)不支持列传导,这包含两种情况:
一是例如join on clause包含A.k = B.k and B.k = C.k 时,目前C.k 只可以下推给B.k,而不可以下推给A.k;
二是例如join on clause包含A.a + B.b = C.c,如果A.a可以列传导到B.a,即 A.a和 B.a是等价的列,那么可以用B.a替换A.a,然后可以尝试将Runtime Filter下推给 B(如果A.a 和 B.a不是等价列,则不能下推给B,因为target expr必须与唯一一个 join 左表绑定);
(10)Target expr和src expr的类型必须相等,因为Bloom Filter基于hash,若类型不等则会尝试将target expr的类型转换为src expr的类型;
(11)不支持PlanNode.Conjuncts生成的Runtime Filter下推,与HashJoinNode的eqJoinConjuncts和otherJoinConjuncts不同,PlanNode.Conjuncts生成的Runtime Filter在测试中发现可能会导致错误的结果,例如IN 子查询转换为join时,自动生成的join on clause将保存在PlanNode.Conjuncts中,此时应用Runtime Filter可能会导致结果缺少一些行。
SQL函数
查看内置函数:
mysql> show builtin functions in test;
+--------------------------------+
| Function Name |
+--------------------------------+
| %element_extract% |
| abs |
| acos |
| add |
| add_months |
| adddate |
| aes_decrypt |
......
| years_add |
| years_diff |
| years_sub |
| yearweek |
+--------------------------------+
302 rows in set (0.00 sec)
查看某内置函数的具体信息:
mysql> show full builtin functions in test like 'year';
+----------------+-------------+---------------+-------------------+------------------------------------------------------------------------------------------------------------------------------+
| Signature | Return Type | Function Type | Intermediate Type | Properties |
+----------------+-------------+---------------+-------------------+------------------------------------------------------------------------------------------------------------------------------+
| year(DATETIME) | INT | Scalar | NULL | {"symbol":"_ZN5doris18TimestampFunctions4yearEPN9doris_udf15FunctionContextERKNS1_11DateTimeValE","object_file":"","md5":""} |
+----------------+-------------+---------------+-------------------+------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.05 sec)
更多请参见官网。