0.Hadoop分布式文件系统 HDFS
HDFS以流式数据访问模式来存储超大文件,运行与商用硬件集群上。
1.流式数据访问
HDFS的构建思路:一次写入,多次读取是最高效的访问模式。
2. Block数据块
HDFS基本读写单位,类似于磁盘的页,每次都是读写一个块一般大小为64M,配置大的块目的是最小化寻址开销。
因为:
1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;
2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;
3)对数据块进行读写,减少建立网络的连接成本
一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小;每个块都会被复制到多台机器,默认复制3份,确保数据的容错能力和可用性。如果发现一个块不可用,系统会从不其他地方读取另一个复本。
对于分布式文件系统中的块进行抽象的好处:
- 一个文件的大小可以大于网络中的任意一个磁盘的容量。
- 使用块抽象而非整个文件作为存储单元,大大简化了存储子系统的设计。
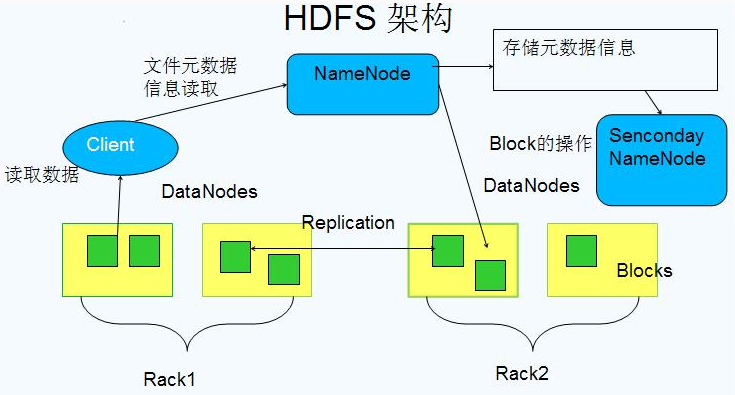
3. namenode
HDFS基础主从架构