TinyKv Project3 PartB Multi-raft KV
- 前言
- Project3 PartB Multi-raft KV 文档翻译
- 发送请求
- LeaderTransfer 禅让
- ConfChange 集群成员变更
- Split region分裂
- 应用请求
- LeaderTransfer 禅让
- ConfChange 集群成员变更
- Split region分裂
- 为什么 add node 时并没有新建 peer 的操作?
前言
project3b:在Raft store上执行conf更改和区域拆分。project3B 要实现 project3A 的上层操作,即 LeaderTransfer 和 Add / Remove 的具体应用,涉及到 ConfChange。同时,3B 还要实现 region 的 split。
Project3 PartB Multi-raft KV 文档翻译
由于 Raft 模块现在支持成员变更和领导变更,在这一部分中,你需要在 Part A 的基础上使 TinyKV 支持这些 admin 命令。你可以在 proto/proto/raft_cmdpb.proto 中看到,有四种 admin 命令:
- CompactLog (已经在 Project2 的 PartC 实现)
- TransferLeader
- ChangePeer
- Split
TransferLeader 和 ChangePeer 是基于 Raft 支持的领导变更和成员变更的命令。这些将被用作平衡调度器的基本操作步骤。Split 将一个 region 分割成两个 region,这是 multi Raft 的基础。你将一步一步地实现它们。
代码
所有的变化都是基于 Project2 的实现,所以你需要修改的代码都是关于 kv/raftstore/peer_msg_handler.go 和 kv/raftstore/peer.go。
Propose 转移领导者
这一步相当简单。作为一个 Raft 命令,TransferLeader 将被提议为一个Raft 日志项。但是 TransferLeader 实际上是一个动作,不需要复制到其他 peer,所以你只需要调用 RawNode 的 TransferLeader() 方法,而不是 TransferLeader 命令的Propose()。
在raftstore中实现conf变更
conf change有两种不同的类型:AddNode 和 RemoveNode。正如它的名字所暗示的,它添加一个 Peer 或从 region 中删除一个 Peer。为了实现 conf change,你应该先学习 RegionEpoch 的术语。RegionEpoch 是 metapb.Region 的元信息的一部分。当一个 Region 增加或删除 Peer 或拆分时,Region的poch就会发生变化。RegionEpoch 的 conf_ver 在 ConfChange 期间增加,而版本在分裂期间增加。它将被用来保证一个 Region 中的两个领导者在网络隔离下有最新的region信息。
你需要使 raftstore 支持处理 conf change 命令。这个过程是:
- 通过 ProposeConfChange 提出 conf change admin 命令
- 在日志被提交后,改变 RegionLocalState,包括 RegionEpoch 和 Region 中的Peers。
- 调用 raft.RawNode 的 ApplyConfChange()。
提示:
- 对于执行AddNode,新添加的 Peer 将由领导者的心跳来创建,查看storeWorker 的 maybeCreatePeer()。在那个时候,这个 Peer 是未初始化的,它的 region 的任何信息对我们来说都是未知的,所以我们用 0 来初始化它的日志任期和索引。这时领导者会知道这个跟随者没有数据(存在一个从0到5的日志间隙),它将直接发送一个快照给这个跟随者。
- 对于执行 RemoveNode,你应该明确地调用 destroyPeer() 来停止 Raft 模块。销毁逻辑是为你提供的。
- 不要忘记更新 GlobalContext 的 storeMeta 中的 region 状态。
- 测试代码会多次安排一个 conf change 的命令,直到该 conf change 被应用,所以你需要考虑如何忽略同一 conf change 的重复命令。
在raftstore中实现分割区域
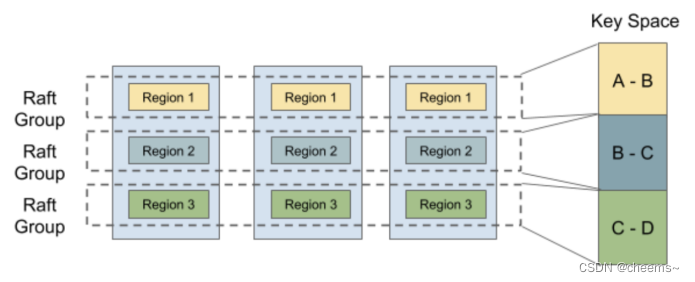
为了支持 multi-raft,系统进行了数据分片,使每个 raft 组只存储一部分数据。Hash 和 Range 是常用的数据分片方式。TinyKV 使用 Range,主要原因是 Range 可以更好地聚合具有相同前缀的key,这对扫描等操作来说很方便。此外,Range在分片上比 Hash 更有优势。通常情况下,它只涉及元数据的修改,不需要移动数据。
message Region {
uint64 id = 1;
// Region key range [start_key, end_key).
bytes start_key = 2;
bytes end_key = 3;
RegionEpoch region_epoch = 4;
repeated Peer peers = 5
}
让我们重新审视一下 Region 的定义,它包括两个字段 start_key 和 end_key,以表明 Region 所负责的数据范围。所以 Split 是支持多进程的关键步骤。在开始时,只有一个Region,其范围是[“”, “”)。你可以把 key 空间看作一个圈,所以[“”, “”)代表整个空间。随着数据的写入,分割检查器将在每一个 cfg.SplitRegionCheckTickInterval 检查 region 的大小,并在可能的情况下生成一个分割键,将该 region 切割成两部分,你可以在 kv/raftstore/runner/split_check.go 中查看其逻辑。分割键将被包装成一个 MsgSplitRegion,由 onPrepareSplitRegion() 处理。
为了确保新创建的 Region 和 Peers 的 id 是唯一的,这些 id 是由调度器分配的。onPrepareSplitRegion() 实际上为 pd Worker 安排了一个任务,向调度器索取id。并在收到调度器的响应后做出一个 Split admin命令,见kv/raftstore/runner/scheduler_task.go 中的 onAskSplit()。
所以你的任务是实现处理 Split admin 命令的过程,就像 conf change 那样。提供的框架支持 multi-raft,见 kv/raftstore/router.go。当一个 Region 分裂成两个 Region 时,其中一个 Region 将继承分裂前的元数据,只是修改其 Range 和 RegionEpoch,而另一个将创建相关的元信息。
提示:
- 这个新创建的 Region 的对应 Peer 应该由 createPeer() 创建,并注册到 router.regions。而 region 的信息应该插入 ctx.StoreMeta 中的regionRanges 中。
- 对于有网络隔离的 region split 情况,要应用的快照可能会与现有 region 的范围有重叠。检查逻辑在 kv/raftstore/peer_msg_handler.go 的checkSnapshot() 中。请在实现时牢记这一点,并照顾到这种情况。
- 使用 engine_util.ExceedEndKey() 与 region 的 end key 进行比较。因为当end key 等于"“时,任何 key 都将等于或大于”"。> - 有更多的错误需要考虑。ErrRegionNotFound, ErrKeyNotInRegion, ErrEpochNotMatch。
发送请求
func (d *peerMsgHandler) proposeRaftCommand(msg
if msg.AdminRequest != nil {
d.proposeAdminRequest(msg, cb)
} else {
d.proposeRequest(msg, cb)
}
}
func (d *peerMsgHandler) proposeAdminRequest(msg *raft_cmdpb.RaftCmdRequest, cb *message.Callback) {
case raft_cmdpb.AdminCmdType_CompactLog:
case raft_cmdpb.AdminCmdType_TransferLeader:
case raft_cmdpb.AdminCmdType_ChangePeer:
case raft_cmdpb.AdminCmdType_Split:
}
LeaderTransfer 禅让
LeaderTransfer 会作为一条 Admin 指令被 propose,直接调用d.RaftGroup.TransferLeader() 方法即可,它会通过 Step() 传递一个 MsgTransferLeader 到 raft 层中。LeaderTransfer 不需要被 raft 确认,是单边发起的, Leader 接收到了 MsgTransferLeader,直接开启转换。整个处理流程如下:
- 上层发送一条
AdminCmdType_TransferLeader请求, - 调用
d.RaftGroup.TransferLeader(msg.AdminRequest.TransferLeader.Peer.Id) 将命令转发给raft层的leader - 直接leader怎么去处理领导禅让,我在
project3 partA中已经写过了
case raft_cmdpb.AdminCmdType_TransferLeader:
d.RaftGroup.TransferLeader(msg.AdminRequest.TransferLeader.Peer.Id)
adminResp := &raft_cmdpb.AdminResponse{
CmdType: raft_cmdpb.AdminCmdType_TransferLeader,
TransferLeader: &raft_cmdpb.TransferLeaderResponse{},
}
cb.Done(&raft_cmdpb.RaftCmdResponse{
Header: &raft_cmdpb.RaftResponseHeader{},
AdminResponse: adminResp,
})
ConfChange 集群成员变更
ConfChange是集群成员变更,具体需要在apply后进行处理。在转发该消息的时候,需要注意的是,我们这里只能单次单次的去修改成员,也就是说,下一次的成员变更需要等待上一次完成之后才能继续进行。
如果 region 只有两个节点,并且需要 remove leader,则需要先完成 transferLeader将leader禅让给别人。
case raft_cmdpb.AdminCmdType_ChangePeer:
if d.peerStorage.AppliedIndex() >= d.RaftGroup.Raft.PendingConfIndex {
if len(d.Region().Peers) == 2 && msg.AdminRequest.ChangePeer.ChangeType == pb.ConfChangeType_RemoveNode && msg.AdminRequest.ChangePeer.Peer.Id == d.PeerId() {
for _, p := range d.Region().Peers {
if p.Id != d.PeerId() {
d.RaftGroup.TransferLeader(p.Id)
break
}
}
}
d.proposals = append(d.proposals, &proposal{
index: d.nextProposalIndex(),
term: d.Term(),
cb: cb,
})
context, _ := msg.Marshal()
d.RaftGroup.ProposeConfChange(pb.ConfChange{
ChangeType: msg.AdminRequest.ChangePeer.ChangeType,
NodeId: msg.AdminRequest.ChangePeer.Peer.Id,
Context: context,
})
}
Split region分裂
3B 要实现 Split,即将一个 region 一分为二,降低单个 region 的存储压力。当 regionA 容量超出 Split 阀值时触发 Split 操作,按照 Split Key 将 regionA 按照 Key 的字典序一分为二,成为 regionA 和 regionB,从此 regionA 、regionB 为两个独立的 region。
原本 0~100 的范围里面只能使用一个 Raft Group 处理请求,然后将其一分为二为两个 region,每个处理 50 个 Key,就可以用两个 Raft Group,能提升访问性能。
从1个raft group 分裂成 2 个raft group,并且他们是共用底层的存储,所以不涉及到数据迁移。等到3C的Schedule时,如果进行region的调度,就会在目标store创建一个新peer,然后日志同步之后,再把自身的peer删掉
Split 触发
- peer_msg_handler.go 中的 onTick() 定时检查,调用 onSplitRegionCheckTick() 方法,它会生成一个 SplitCheckTask 任务发送到 split_checker.go 中;
- 检查时如果发现满足 split 要求,则生成一个 MsgTypeSplitRegion 请求;
- 在 peer_msg_handler.go 中的 HandleMsg() 方法中调用 onPrepareSplitRegion(),发送 SchedulerAskSplitTask 请求到 scheduler_task.go 中,申请其分配新的 region id 和 peer id。申请成功后其会发起一个 AdminCmdType_Split 的 AdminRequest 到 region 中。
- 之后就和接收普通 AdminRequest 一样,propose 等待 apply。注意 propose 的时候检查 splitKey 是否在目标 region 中和 regionEpoch 是否为最新,因为目标 region 可能已经产生了分裂;
注意 propose 的时候检查 splitKey 是否在目标 region 中和 regionEpoch 是否为最新,因为目标 region 可能已经产生了分裂
case raft_cmdpb.AdminCmdType_Split:
if err := util.CheckRegionEpoch(msg, d.Region(), true); err != nil {
log.Infof("[AdminCmdType_Split] Region %v Split, a expired request", d.Region())
cb.Done(ErrResp(err))
return
}
if err := util.CheckKeyInRegion(msg.AdminRequest.Split.SplitKey, d.Region()); err != nil {
cb.Done(ErrResp(err))
return
}
log.Infof("[AdminCmdType_Split Propose] Region %v Split, entryIndex %v", d.Region(), d.nextProposalIndex())
d.proposals = append(d.proposals, &proposal{
index: d.nextProposalIndex(),
term: d.Term(),
cb: cb,
})
data, _ := msg.Marshal()
d.RaftGroup.Propose(data)
}
应用请求
func (d *peerMsgHandler) HandleRaftReady() {
kvWB = d.processCommittedEntry(&ent, kvWB)
}
func (d *peerMsgHandler) processCommittedEntry(entry *pb.Entry, kvWB *engine_util.WriteBatch) *engine_util.WriteBatch {
if entry.EntryType == pb.EntryType_EntryConfChange {
return d.processConfChange(entry, cc, kvWB)
}
if requests.AdminRequest != nil {
return d.processAdminRequest(entry, requests, kvWB)
} else {
return d.processRequest(entry, requests, kvWB)
}
}
LeaderTransfer 禅让
准确来说LeaderTransfer并不能算”应用“,因为它不需要apply。
- 判断自己的 leadTransferee 是否为空,如果不为空,则说明已经有 Leader Transfer 在执行。我们采用强制最新的原则,直接覆盖原来的 leadTransferee,不管其是否执行成功;
- 如果目标节点拥有和自己一样新的日志,则发送 pb.MessageType_MsgTimeoutNow 到目标节点。否则启动 append 流程同步日志。当同步完成后再发送 pb.MessageType_MsgTimeoutNow;
- 当 Leader 的 leadTransferee 不为空时,不接受任何 propose,因为正在转移;
- 如果在一个 electionTimeout 时间内都没有转移成功,则放弃本次转移,重置 leadTransferee 为 None。因为目标节点可能已经挂了;
- 目标节点收到 pb.MessageType_MsgTimeoutNow 时,应该立刻自增 term 开始选举;
- LeaderTransfer 之所以能成功,核心原因是目标节点的日志至少和旧 Leader 一样新,这样在新一轮选举中term+1比leader大,目标节点就可以顺利当选 Leader。
func (r *Raft) handleTransferLeader(m pb.Message) {
if _, ok := r.Prs[m.From]; !ok {
return
}
if m.From == r.id {
return
}
if r.leadTransferee != None {
if r.leadTransferee == m.From {
return
}
r.leadTransferee = None
}
r.leadTransferee = m.From
r.transferElapsed = 0
if r.Prs[m.From].Match == r.RaftLog.LastIndex() {
r.sendTimeoutNow(m.From)
} else {
r.sendAppend(m.From)
}
}
ConfChange 集群成员变更
- 检查 Command Request 中的 RegionEpoch 是否是过期的,以此判定是不是一个重复的请求
- 更新 metaStore 中的 region 信息
- 更新 peerCache
- 更新 raft 层的配置信息,即ApplyConfChange
- 处理 proposal
- 更新 scheduler 那里的 region 缓存(3C会说)
func (d *peerMsgHandler) processConfChange(entry *pb.Entry, cc *pb.ConfChange, kvWB *engine_util.WriteBatch) *engine_util.WriteBatch {
msg := &raft_cmdpb.RaftCmdRequest{}
if err := msg.Unmarshal(cc.Context); err != nil {
log.Panic(err)
}
region := d.Region()
changePeerReq := msg.AdminRequest.ChangePeer
if err, ok := util.CheckRegionEpoch(msg, region, true).(*util.ErrEpochNotMatch); ok {
log.Infof("[processConfChange] %v RegionEpoch not match", d.PeerId())
d.handleProposal(entry, ErrResp(err))
return kvWB
}
switch cc.ChangeType {
case pb.ConfChangeType_AddNode:
log.Infof("[AddNode] %v add %v", d.PeerId(), cc.NodeId)
if d.searchPeerWithId(cc.NodeId) == len(region.Peers) {
region.Peers = append(region.Peers, changePeerReq.Peer)
region.RegionEpoch.ConfVer++
meta.WriteRegionState(kvWB, region, rspb.PeerState_Normal)
d.updateStoreMeta(region)
d.insertPeerCache(changePeerReq.Peer)
}
case pb.ConfChangeType_RemoveNode:
log.Infof("[RemoveNode] %v remove %v", d.PeerId(), cc.NodeId)
if cc.NodeId == d.PeerId() {
d.destroyPeer()
log.Infof("[RemoveNode] destory %v compeleted", cc.NodeId)
return kvWB
}
n := d.searchPeerWithId(cc.NodeId)
if n != len(region.Peers) {
region.Peers = append(region.Peers[:n], region.Peers[n+1:]...)
region.RegionEpoch.ConfVer++
meta.WriteRegionState(kvWB, region, rspb.PeerState_Normal)
d.updateStoreMeta(region)
d.removePeerCache(cc.NodeId)
}
}
d.RaftGroup.ApplyConfChange(*cc)
d.handleProposal(entry, &raft_cmdpb.RaftCmdResponse{
Header: &raft_cmdpb.RaftResponseHeader{},
AdminResponse: &raft_cmdpb.AdminResponse{
CmdType: raft_cmdpb.AdminCmdType_ChangePeer,
ChangePeer: &raft_cmdpb.ChangePeerResponse{Region: region},
},
})
if d.IsLeader() {
d.HeartbeatScheduler(d.ctx.schedulerTaskSender)
}
return kvWB
}
Split region分裂
-
基于原来的 region clone 一个新 region,这里把原来的 region 叫 oldRegion,新 region 叫 newRegion。复制方法如下
- 1.1 把 oldRegion 中的 peers 复制一份;
- 1.2 将复制出来的 peers 逐一按照 req.Split.NewPeerIds[i] 修改 peerId,作为 newRegion 中的 peers,记作 cpPeers;
- 1.3 创建一个新的 region,即 newRegion。其中,Id 为 req.Split.NewRegionId,StartKey 为 req.Split.SplitKey,EndKey 为 d.Region().EndKey,RegionEpoch 为初始值,Peers 为 cpPeers;
-
oldRegion 的 EndKey 改为split.SplitKey
-
oldRegion 和 newRegion 的 RegionEpoch.Version 均自增;
-
持久化 oldRegion 和 newRegion 的信息;
-
更新 storeMeta 里面的 regionRanges 与 regions;
-
通过 createPeer() 方法创建新的 peer 并注册进 router,同时发送 message.MsgTypeStart 启动 peer;
-
更新 scheduler 那里的 region 缓存
case raft_cmdpb.AdminCmdType_Split:
if requests.Header.RegionId != d.regionId {
regionNotFound := &util.ErrRegionNotFound{RegionId: requests.Header.RegionId}
d.handleProposal(entry, ErrResp(regionNotFound))
return kvWB
}
if errEpochNotMatch, ok := util.CheckRegionEpoch(requests, d.Region(), true).(*util.ErrEpochNotMatch); ok {
d.handleProposal(entry, ErrResp(errEpochNotMatch))
return kvWB
}
if err := util.CheckKeyInRegion(adminReq.Split.SplitKey, d.Region()); err != nil {
d.handleProposal(entry, ErrResp(err))
return kvWB
}
if len(d.Region().Peers) != len(adminReq.Split.NewPeerIds) {
d.handleProposal(entry, ErrRespStaleCommand(d.Term()))
return kvWB
}
oldRegion, split := d.Region(), adminReq.Split
oldRegion.RegionEpoch.Version++
newRegion := d.createNewSplitRegion(split, oldRegion)
storeMeta := d.ctx.storeMeta
storeMeta.Lock()
storeMeta.regionRanges.Delete(®ionItem{region: oldRegion})
oldRegion.EndKey = split.SplitKey
storeMeta.regionRanges.ReplaceOrInsert(®ionItem{region: oldRegion})
storeMeta.regionRanges.ReplaceOrInsert(®ionItem{region: newRegion})
storeMeta.regions[newRegion.Id] = newRegion
storeMeta.Unlock()
meta.WriteRegionState(kvWB, oldRegion, rspb.PeerState_Normal)
meta.WriteRegionState(kvWB, newRegion, rspb.PeerState_Normal)
peer, err := createPeer(d.storeID(), d.ctx.cfg, d.ctx.schedulerTaskSender, d.ctx.engine, newRegion)
if err != nil {
log.Panic(err)
}
d.ctx.router.register(peer)
d.ctx.router.send(newRegion.Id, message.Msg{Type: message.MsgTypeStart})
d.handleProposal(entry, &raft_cmdpb.RaftCmdResponse{
Header: &raft_cmdpb.RaftResponseHeader{},
AdminResponse: &raft_cmdpb.AdminResponse{
CmdType: raft_cmdpb.AdminCmdType_Split,
Split: &raft_cmdpb.SplitResponse{Regions: []*metapb.Region{newRegion, oldRegion}},
},
})
log.Infof("[AdminCmdType_Split Process] oldRegin %v, newRegion %v", oldRegion, newRegion)
if d.IsLeader() {
d.HeartbeatScheduler(d.ctx.schedulerTaskSender)
d.notifyHeartbeatScheduler(newRegion, peer)
}
}
为什么 add node 时并没有新建 peer 的操作?
peer 不是你来创建的。在 store_worker.go 的 onRaftMessage() 方法中可以看到,当目标的 peer 不存在时,它会调用 d.maybeCreatePeer() 尝试创建 peer。新的 peer 的 startKey,endKey 均为空
因为他们等着 snapshot 的到来,以此来更新自己。这也是为什么在 ApplySnapshot() 方法中你需要调用 ps.isInitialized(),Project2有提到。而在 d.maybeCreatePeer() 中,有个 util.IsInitialMsg() 判断
func (d *storeWorker) onRaftMessage(msg *rspb.RaftMessage) error {
created, err := d.maybeCreatePeer(regionID, msg)
}
func (d *storeWorker) maybeCreatePeer(regionID uint64, msg *rspb.RaftMessage) (bool, error) {
if !util.IsInitialMsg(msg.Message) {
log.Debugf("target peer %s doesn't exist", msg.ToPeer)
return false, nil
}
}
func IsInitialMsg(msg *eraftpb.Message) bool {
return msg.MsgType == eraftpb.MessageType_MsgRequestVote ||
(msg.MsgType == eraftpb.MessageType_MsgHeartbeat && msg.Commit == RaftInvalidIndex)
}
可以看到,如果 Leader 要发送 heartbeat,那么其 msg.Commit 字段一定要是 RaftInvalidIndex(实际上就是 0),只有满足这个条件才算作初始化,才会继续后续步骤来创建原本不存在的 peer。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)