一、安装nvidia_driver
1、在 软件和更新 中选择一个可用的驱动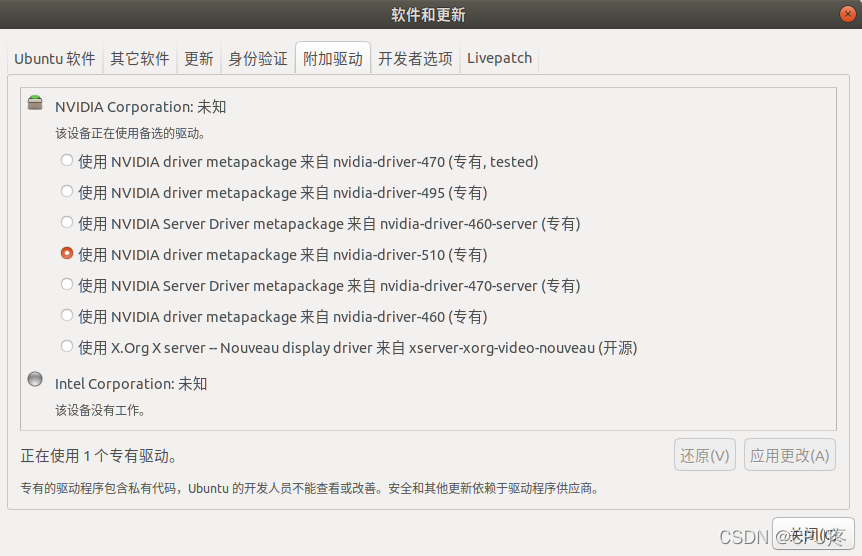
2.1首先我们需要添加源
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
2.2选择一个版本安装即可(如1,我选择安装510)
sudo apt install nvidia-driver-510
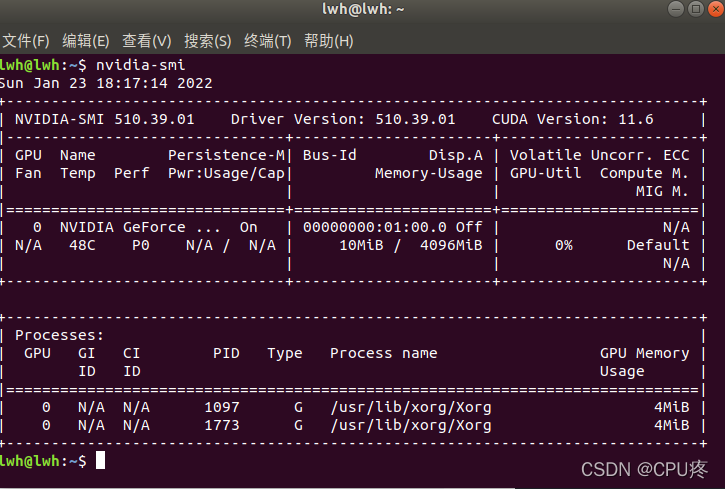
2.3 重启电脑后终端输入
nvidia-smi
查看驱动信息
二、安装CUDA
1、官网找到自己的版本(如2.3版本信息中,我510驱动对应的cuda_11.6)
CUDA Toolkit Archive | NVIDIA Developer 选择runfile格式的CUDA文件下载
2、选择环境,并根据官网步骤安装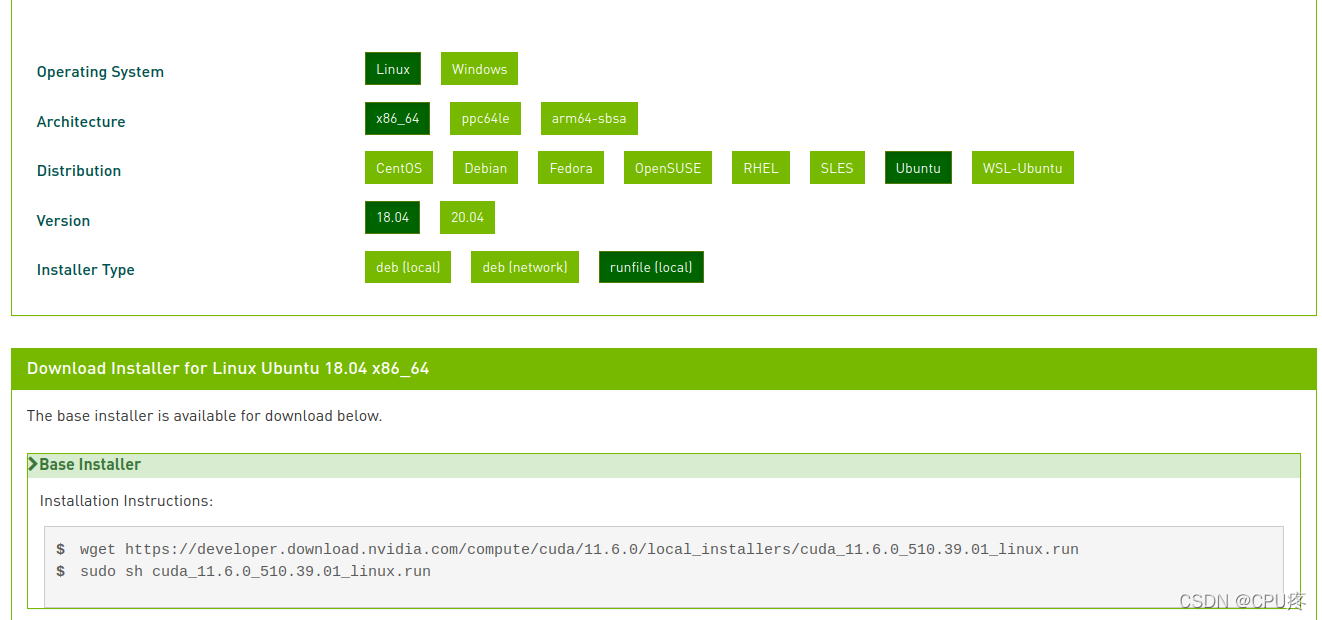
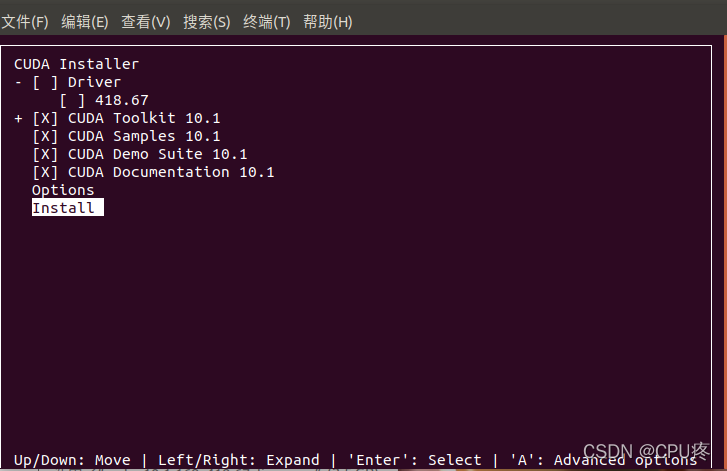
3、下载完成后,解压,并运行上图中的命令,会有条款,接受即可。
3.1注意安装CUDA的时候不要安装驱动(因为在第一步我们已经安装过了)
 3.2添加环境变量
3.2添加环境变量
sudo gedit ~/.bashrc
在打开的txt文件末尾加
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda-11.6/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
保存,退出。终端执行
source ~/.bashrc
3.3 验证cuda
3.3.1
11.6版本cuda的安装目录/usr/local/cuda-11.6/samples里只有一个txt文件,大致意思是告诉你新版本的cuda,samples中内容需要自己在github下载。
由于github下载过慢,在此放上gitee链接
git clone https://gitee.com/liwuhaoooo/cuda-samples.git
在samples文件夹下打开终端执行上述语句。
大概率无权访问,此时在cuda-11.6文件夹下打开终端
su
输入密码切换超级用户
chmod 777 samples
再次执行git clone 就可以了。
3.3.2
进入/usr/local/cuda-11.6/samples/cuda-samples/Samples
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
输出
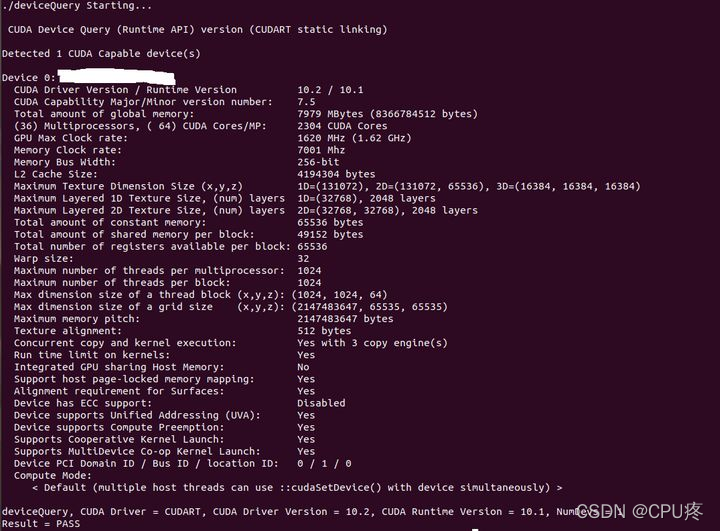
则安装成功。
三、安装cuDNN
1、
进入NVIDIA cuDNN | NVIDIA Developer注册,并选择合适的版本下载(cuDNN Library for Linux),然后解压;
2、
并进入到/home/lwh/Downloads/cudnn-11.3-linux-x64-v8.2.1.32目录,运行以下命令:
sudo cp cuda/include/cudnn.h /usr/local/cuda-11.6/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-11.6/lib64
sudo chmod a+r /usr/local/cuda-11.6/include/cudnn.h
sudo chmod a+r /usr/local/cuda-11.6/lib64/libcudnn*
若无权访问,像3.3.1一样,分别更改include和lib64文件夹权限。
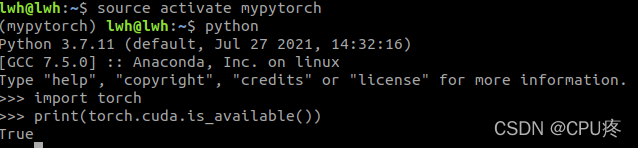
四、验证GPU可用
import torch
print(torch.cuda.is_available())
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)