原文链接:基于stm32串口环形缓冲队列处理机制—入门级(单字节)
串口环形缓冲区实验
1.1 实验简介
最简单的串口数据处理机制是数据接收并原样回发的机制是:成功接收到一个数,触发进入中断,在中断函数中将数据读取出来,然后立即回发。这一种数据处理机制是“非缓冲中断方式”,虽然这种数据处理方式不消耗时间,但是这种数据处理方式严重的缺点是:数据无缓冲区,如果先前接收的的数据如果尚未发送完成(处理完成),然后串口又接收到新的数据,新接收的数据就会把尚未处理的数据覆盖,从而导致“数据丢包”。
对于“数据丢包”,最简单的办法就是使用一个数组来接收数据:每接收一个数据,数组下标偏移。虽然这样的做法能起到一定的“缓冲效果”,但是数组的空间得不到很好的利用,已处理的数据仍然会占据原有的数据空间,直到该数组“满载”(数组的每一个元素都保存了有效的数据),将整个数组的数据处理完成后,重新清零数组,才能开启新一轮的数据接收。
那么,有什么好的数据接收处理机制既能起到“缓冲”效果,又能有效地利用“数组空间”?答案是:有的,那就是“环形缓冲区”。
环形缓冲区就是一个带“头指针”和“尾指针”的数组。“头指针”指向环形缓冲区中可读的数据,“尾指针”指向环形缓冲区中可写的缓冲空间。通过移动“头指针”和“尾指针”就可以实现缓冲区的数据读取和写入。在通常情况下,应用程序读取环形缓冲区的数据仅仅会影响“头指针”,而串口接收数据仅仅会影响“尾指针”。当串口接收到新的数组,则将数组保存到环形缓冲区中,同时将“尾指针”加1,以保存下一个数据;应用程序在读取数据时,“头指针”加1,以读取下一个数据。当“尾指针”超过数组大小,则“尾指针”重新指向数组的首元素,从而形成“环形缓冲区”!,有效数据区域在“头指针”和“尾指针”之间。如下图所示。
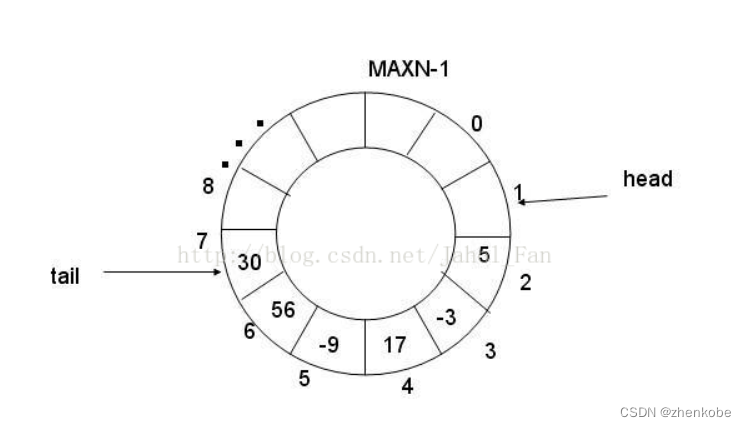
当然,环形缓冲区的“头指针”和“尾指针”可以用“头变量”和“尾变量”来代替,因为切换数组的元素空间,除了可以用“指针偏移法”之外,还可以用“素组下标偏移法”。当串口接收到新的数组,则将数组保存到环形缓冲区中,同时将“尾变量”加一,以保存下一个数据;应用程序在读取数据时,“头变量”加一,以读取下一个数据。
“环形缓冲区”数据接收处理机制的好处在于:利用了队列的特点,一头进,一头出,互不影响,在数据进去(往里存)的时候,另一边也可以把数据读出来,而读出来的数据,留下的空位,又可以增加多的存储空间,从而避免一边接收数据且一边处理数据会在数据量密集的时候而导致的丢掉数据或者数据产生冲突的问题。
如果仅有一个线程读取环形缓冲区的数据,只有一个串口往环形缓冲区写入数据,则不需要添加互斥保护机制就可以保证数据的正确性。
需要注意的是,如果串口每接收x个字节的数据才处理一次,则环形缓冲区的缓冲数组的大小必须是x的N倍,具体N为多少,需要结合具体的数据接收速率以及处理速率,适当调节。这就好比喻,水壶永远大于水杯,这样子水壶才能存放很多杯水。
下面我们来一起讨论一下环形队列的具体状态以及实现。下文构建的环形队列采用的是“头变量”“尾变量”来控制队列的存储和读取。
环形队列采用 “头指针”和“尾指针”来控制队列的存储和读取可以参考 环形缓冲区控制队列的存储和读取方法之指针
首先,我们会构造一个结构体,并定义一个结构变量。
#define MAX_SIZE 12
typedef struct
{
unsigned char head;
unsigned char tail;
unsigned char ringBuf[MAX_SIZE];
} ringBuffer_t;
ringBuffer_t buffer;
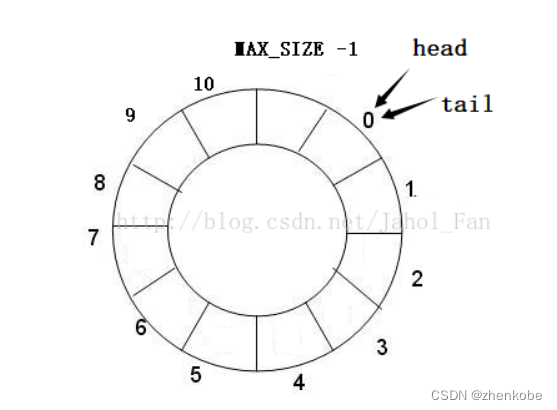
定义一个结构头体则表示新的消息队列已经创建完成。新建创建的队列,头指针head和尾指针tail都是指向数组的元素0。如下图所示,此时的消息队列是“空队列”。
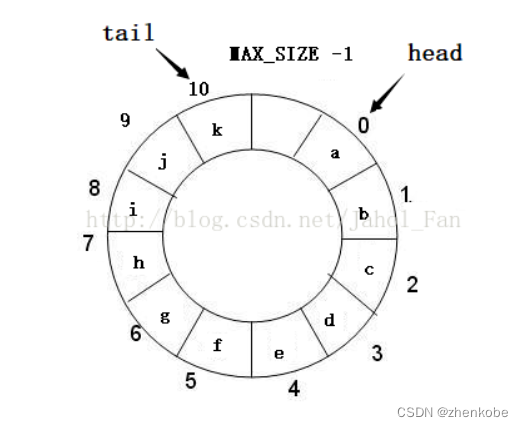
当如果有11个数据 abcdefghijk 存入缓冲队列,则如下图所示:
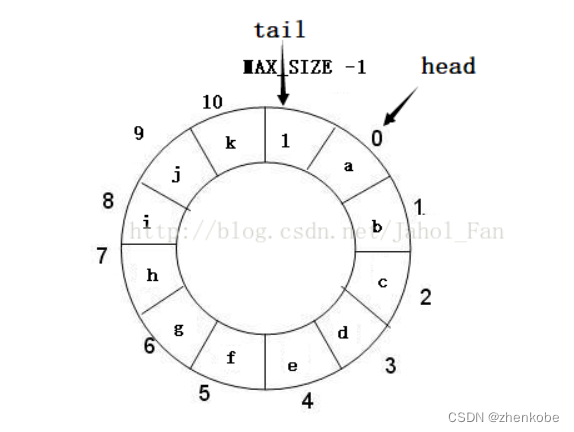
当如果 l 加入队列,则缓冲队列处于满载状态,如下图所示:如果此时,接收到新的数据并需要保存,则tail需要归零,将接收到的数据存到数组的第一个元素空间,如果尚未读取缓冲数组的一个元素空间的数据,则此数据会被新接收的数据覆盖。同时head需要增加1,修改头节点偏移位置丢弃早期数据。
读取缓冲队列中的11个数据后,状态如下:
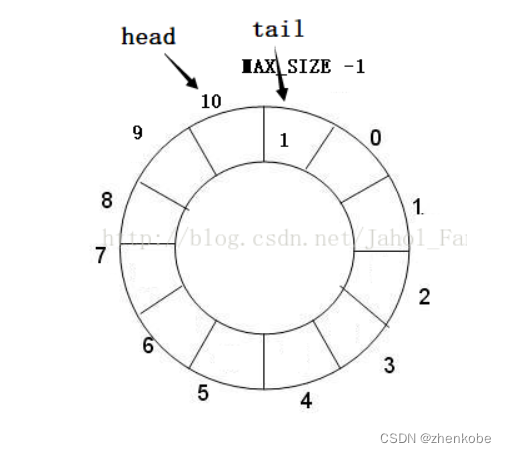
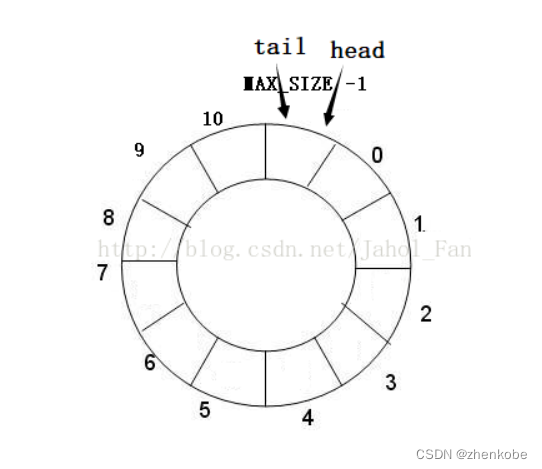
当消息队列中的所有数据都读取出来后,此时环形队列是空的,状态如下图所示。从图可以总结得知,如果tail和head相等,则表示缓冲队列是空的。
1.2 软件设计
ringBuffer.c
1. 构造环形缓冲区
#include "ringbuffer.h"
#define BUFFER_MAX 36
typedef struct
{
unsigned char headPosition;
unsigned char tailPositon;
unsigned char ringBuf[BUFFER_MAX];
} ringBuffer_t;
ringBuffer_t buffer;
首先,需要构建一个结构体ringBuffer_t,如果定义一个结构体变量buffer,则意味着创建一个环形缓冲区。
2. 往环形缓冲区存数据
void RingBuf_Write(unsigned char data)
{
buffer.ringBuf[buffer.tailPositon]=data;
if(++buffer.tailPositon>=BUFFER_MAX)
buffer.tailPositon=0;
if(buffer.tailPositon == buffer.headPosition)
if(++buffer.headPosition>=BUFFER_MAX)
buffer.headPosition=0;
}
8行:将数据存放到tailPosition所指向的元素空间。
9行:tailPosition变量自增1,并且判断,如果大于最大缓冲,则将tailPosition归零。
11行:如果tailPositon与headPosition相等,则表示,数据存入速度大于数据取出速度,从而导致“追尾”。此时headPosition需要自增1,以丢弃早期数据,这也就是数据“覆盖现象”,这种现象是不允许存在的,解决这种现象的办法是将缓冲队列的空间再开大点。
13行:如果headPosition也大于最大数组,则需要将headPosition清零。
3. 读取环形缓冲区的数据
u8 RingBuf_Read(unsigned char* pData)
{
if(buffer.headPosition == buffer.tailPositon)
{
return 1;
}
else
{
*pData=buffer.ringBuf[buffer.headPosition];
if(++buffer.headPosition>=BUFFER_MAX)
buffer.headPosition=0;
return 0;
}
}
8行:首先判断headPosition是否等于tailPositon,如果相等,则表明,此时缓冲区是空的。
10行:缓冲区为空,则直接返回,不执行后面的程序
12行:如果缓冲区不为空,则条件成立并执行
14行:读取headPosition所指向的环形缓冲队列的元素空间的数据。
15行:headPosition自增1以读取下一个数据。如果headPosition大于最大值BUFFER_MAX,则将headPosition归零。
17行:返回0,表示读取数据成功。
Hal_uart.c
void USART1_IRQHandler(void)
{
if(USART_GetITStatus(USART1, USART_IT_RXNE) != RESET)
{
USART_ClearITPendingBit(USART1,USART_IT_RXNE);
RingBuf_Write(USART_ReceiveData(USART1));
while (USART_GetFlagStatus(USART1, USART_FLAG_TXE) == RESET);
}
}
11行:数据接收成功,则将数据存入环形缓冲队列。
Main.c
#include "Hal_Led/Hal_Led.h"
#include "Hal_delay/delay.h"
#include "Hal_Key/Hal_Key.h"
#include "Hal_Relay/Hal_Relay.h"
#include "Hal_Usart/hal_uart.h"
#include "ringbuffer.h"
int main(void)
{
u8 data = 0;
SystemInit();
delayInit(72);
uartxInit();
while(1)
{
if(0 == RingBuf_Read(&data))
{
USART_SendData(USART1,data);
}
delayMs(1);
}
}
30行:读取环形缓冲的数据,如果环形缓冲队列有数据,则条件成立
32行:将数据原样回发
34行:延时1ms的目的是:使得处理数据的速度小于接收数据的速度,用于验证接收缓冲区的“缓冲”特性。实际上,在项目工程中,项目代码的执行是消耗一定的CPU时间的,本例程序用延时1毫秒来等效替代项目代码执行小号的CPU时间。
1.3 下载验证
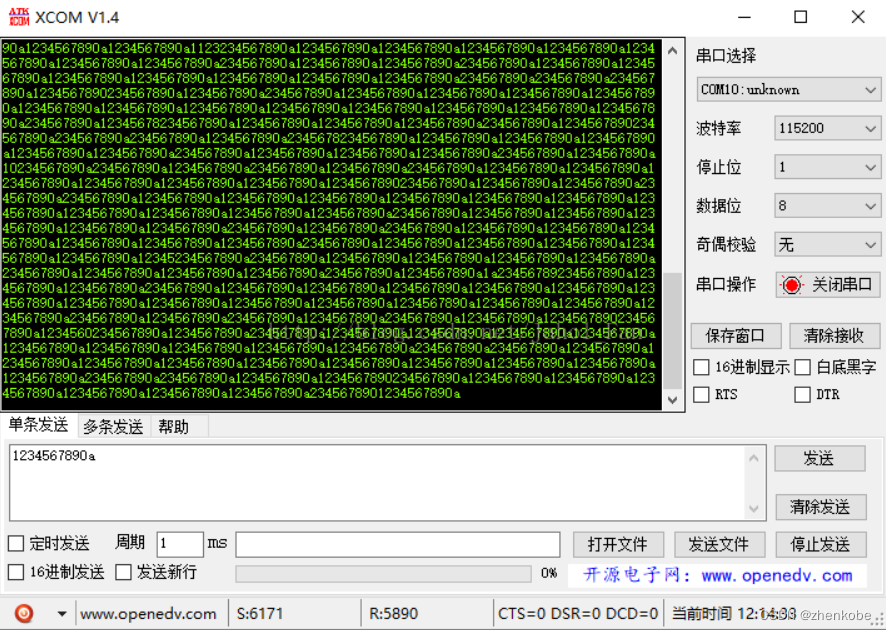
当如果将缓冲队列最大缓冲空间设为12
#define BUFFER_MAX 12 //缓冲区大小
串口助手毫秒发送11个字节的数据(115200的波特率每毫秒最多发送115200bit/s÷10bit÷1000 = 111.52Byte/ms),11个字节的数据是:1234567890a。经过测试,发送6167个字节的数据,实际上接收到的数据只有5890个字节,丢包很严重!如下图所示:
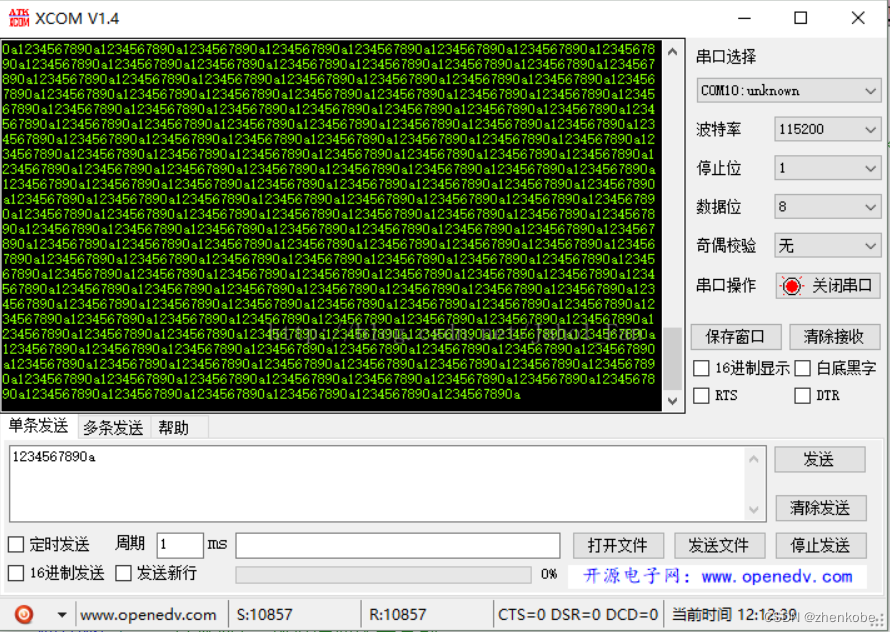
当如果将缓冲队列最大缓冲空间设为100
#define BUFFER_MAX 100 //缓冲区大小
串口助手毫秒发送11个字节的数据,11个字节的数据是:1234567890a。经过测试,发送10857个字节的数据,接收到的数据也是10857个字节,没有丢包!现象如下图所示:
版权归原作者所有,如有侵权,请联系删除。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)