ARM于近期推出了两款图形处理器产品,分别为Mali-G52以及Mali-G31,主要应用于主流移动市场。

由于移动端AI计算、图形处理需求的与日俱增,GPU之于手机SoC的作用日渐凸显,ARM全新的图形核心也呼之欲出。近日,据媒体报道,ARM于推出了两款图形处理器产品,分别为Mali-G52以及Mali-G31,主要应用于主流移动市场。这两款核心均是ARM现有的Bifrost图形架构的变种,重点改善了其机器学习性能以及功耗表现。
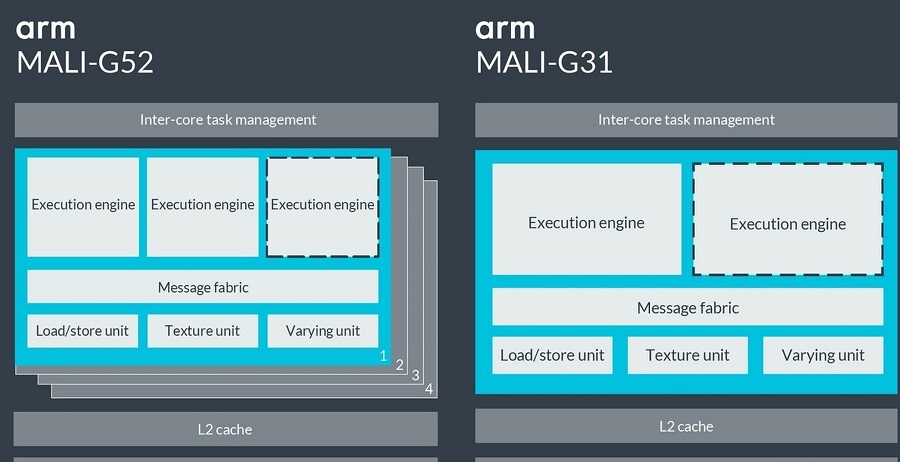
据悉,Mali-G52采用更宽的执行引擎,相比前代产品的4线程,Mali-G52最多可提供8线程,可在相同芯片面积上,提供更高的图形性能。实测数据显示,相比上一代,G52性能密度提高30%,能效提高15%,可降低设备的功耗和散热,并支持更长的游戏时间,甚至可支持AR等高耗电技术。
而Mali-G31主要针对720P或更低显示分辨率的高能效设备而设计,与Mali-G51 MP2相比,Mali-G31的芯片面积可以缩小20%,并且仍然可以提供12%的性能提升。更重要的是,Mali-G31是ARM支持Vulkan API和OpenGL ES 3.2标准的最小芯片。
ARM资深市场营销总监Ian Smythe表示:“对终端设备而言,支持丰富的多层用户界面以及一系列广泛的最新应用已成为必然趋势。更为重要的是,机器学习不再是高端智能手机的专有配置。各级用户都希望轻松使用配备机器学习功能的各类APP应用,3D游戏、混合现实和4k内容越来越流行,新型的游戏也不断出现在主流手机上。在新一代用户的需求之下,ARM以技术驱动创新,推出新一代解决方案,为用户提供更酣畅的视觉体验。”
最后,ARM还公布称,迄今已向它的合作伙伴交付超过1250亿枚芯片,并预计到2021年这一数字将达到2000亿。
原文发布时间:
2018-03-07 22:04
本文作者:
巫盼
本文来自云栖社区合作伙伴镁客网,了解相关信息可以关注镁客网。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)