python爬虫爬取网页将特定信息存入excel
背景
1、最近遇到一个需要进行数据分析的项目,主要是将网页上需要的信息,进行归拢,分析。当信息量少的时候,采用复制粘贴-excel分析还比较快捷方便,当如果数据上升到几百甚至几千条时,一个一个的复制粘贴,就明显感觉效率低下,难以操作。
2、之前也一直听说过python爬虫,趁着这个机会正好来实验一波。笔者几年前曾学过python,有一定的基础。
需求分析:
1、目的:通过python爬虫,实现批量化抓取网页中的有效信息,然后将信息,一条一条的存储到excel中。最后通过用excel进行最后的数据统计分析。
2、功能需求
a,读取网页
b,抓取网页特定内容
c,将内容按顺序存储到excel中
功能实现
爬虫的本质是,编写程序,让程序模拟人操作浏览器进行网页访问。本文以豆瓣电影为例,实现爬取某类型影片的排名信息
网页分析
当打开豆瓣电影分类排行榜,选择动作片后,出现的页面如下。
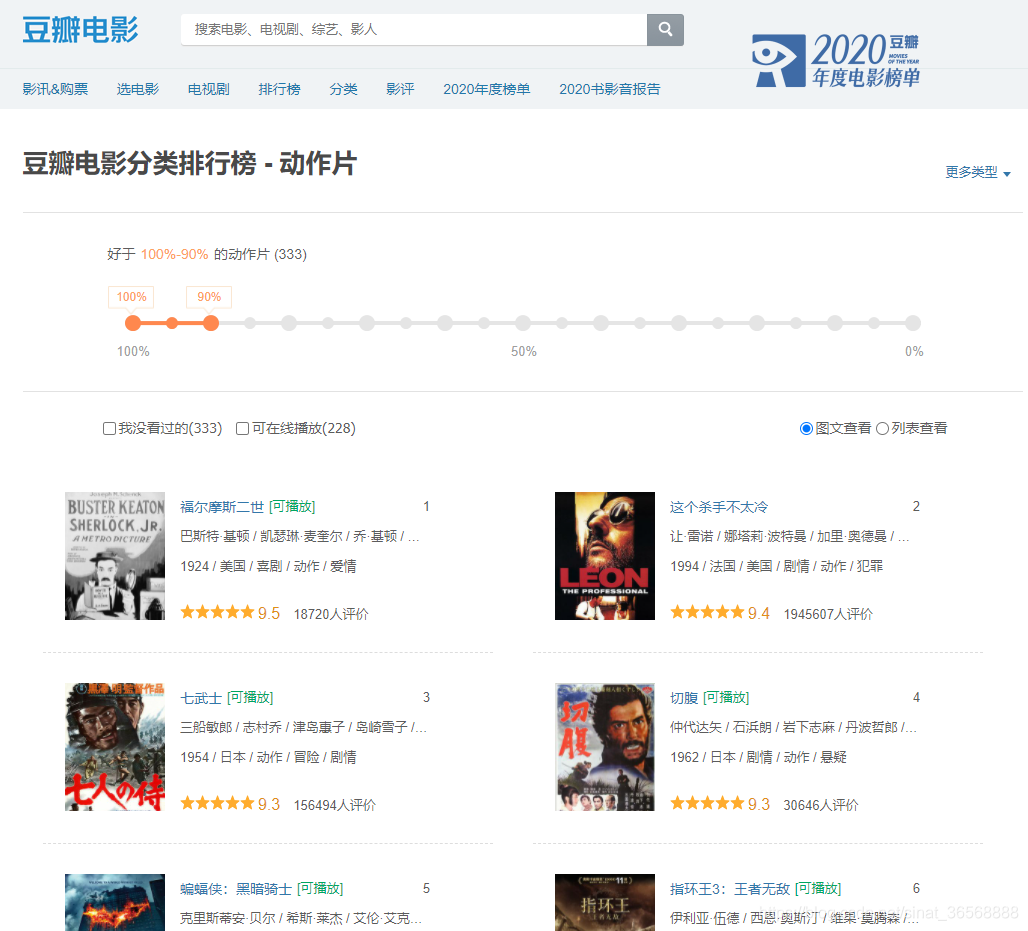
当页面的进度条拖到最下面,会直接刷新出新的页面,而不是重新刷新整个页面,这用的就是阿贾克斯网页动态局部加载技术。
下面右键网页,选择检查,切换到Network选项,筛选出XHR选项
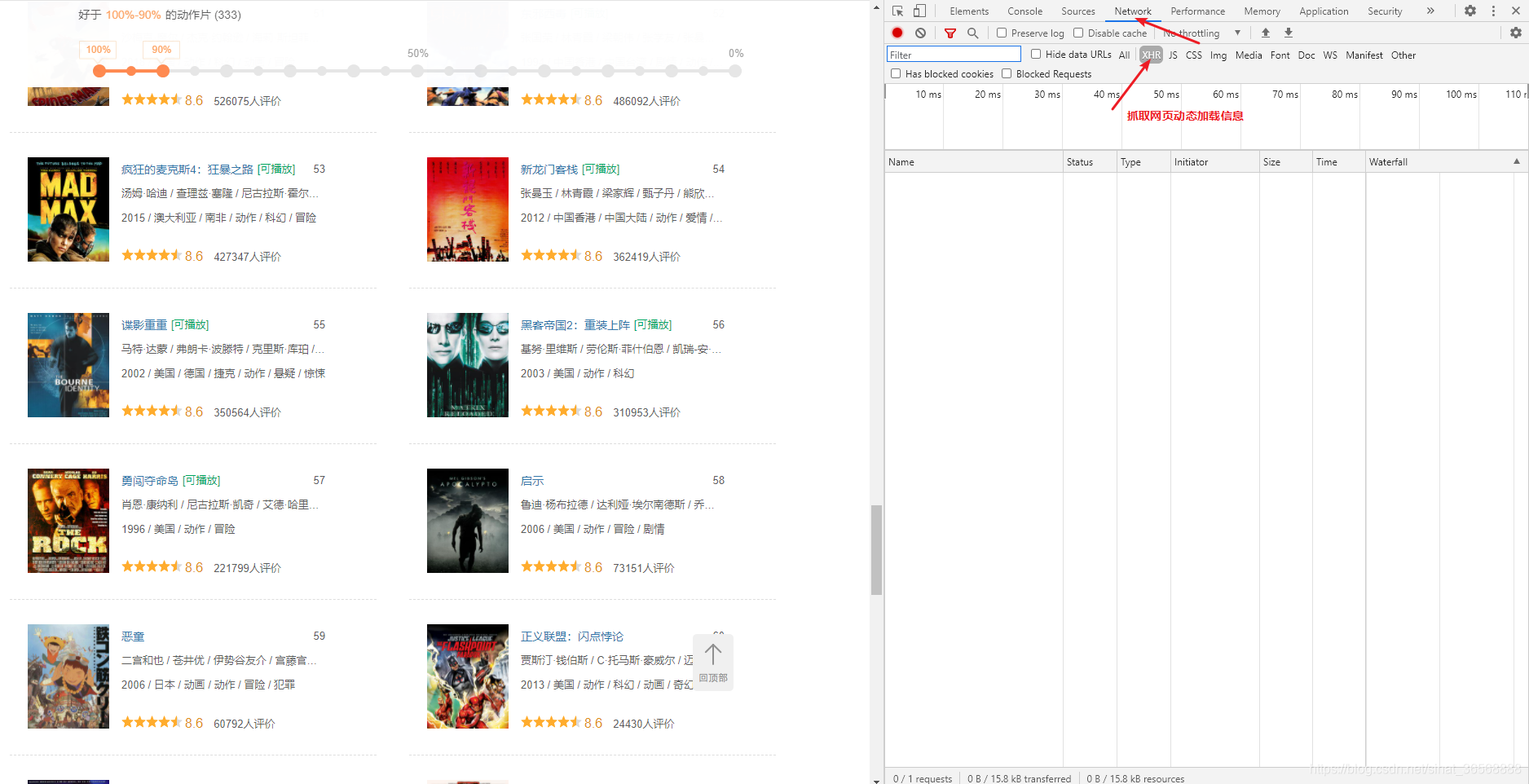
把进度条继续拖动到最下面,发现刷新出了,一个请求信息。
双击这个请求,可以看到Response里面是一个类似json格式的数据,里面信息刚好就是对应着页面中的电影信息

切换到Headers选项,仔细看下网页的请求接口,如果能找到这个请求接口,那么就可以python中request模块访问该接口,网页反馈的是类似json格式的数据,如果这一步走通了,接下来就好办了。那先来看下请求接口。
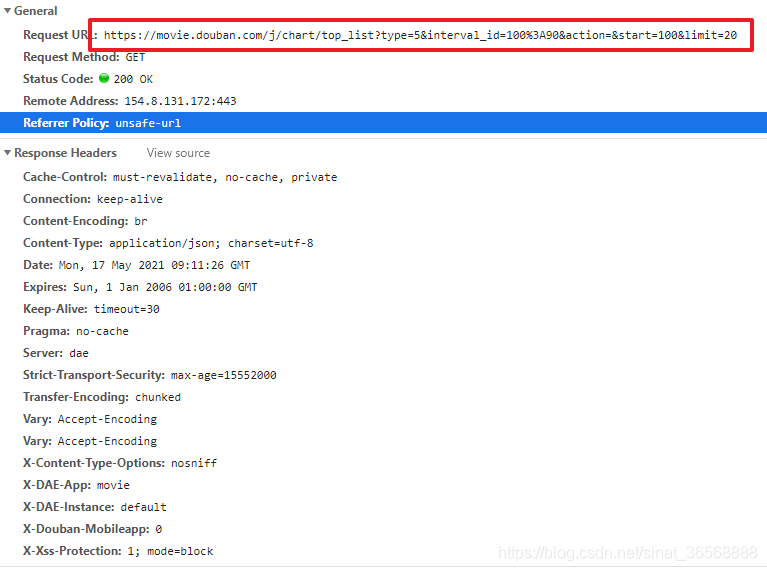
可以看到,请求的地址是https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=100&limit=20,请求的方式是GET。参数以后type,interval_id,action,start,limit。
通过对headers分析,发现,请求里面有5个参数,那这个参数都是什么含义呢?写python程序是需要对这些参数赋什么值呢?
其实爬虫我们要重点关注返回的数据,请求我们只要保证请求命令能正常得到反馈就行了。所以我们只需要找到这个请求中,哪些参数是变化的,然后分析出这个参数的含义,对于不变的参数,程序中就按照网页headers里面的填写即可。
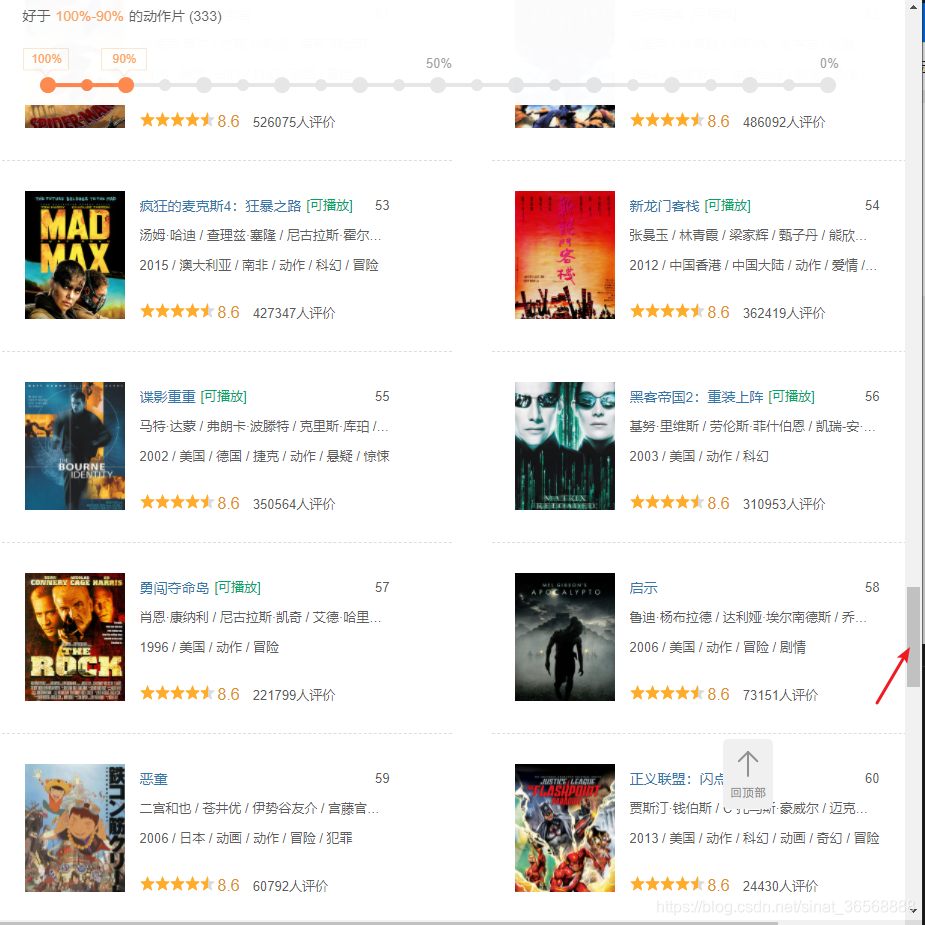
要找到变化的参数,只需要往下拉进度条,看新的请求数据
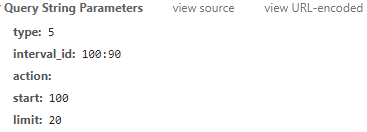

可以看到,里面只有start变化了,start 80;limit 20 ; start100 ; limit 20 。是不是可以猜测,这个20就是每次刷新的影片数量?start就是要从排名第几的影片开始读取?

通过初步分析下网页,这个可能性极大,要验证也简单呀,还记得里面的请求是GET,那么可以用浏览器直接访问该接口验证一下。
start =1 limit=2,刷新出来了这个杀手不太冷和七武士两部影片


start =2 limit=3,刷新出来了七武士、切腹、蝙蝠侠:黑暗骑士三部影片。由此可以验证start为从排名第几的影片开始请求。limit为每次请求影片数量。如果我想抓取排名前300的影片,那只需要将start=1,limit=300即可。网页分析到这里就可以了,已经得到了我们想要的信息
1、接口:https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=2&limit=3
2、请求方式:GET
3、参数:type interval_id action start limit 前面三个是固定不变的
小结:
1、本部分,通过分析网页,发现豆瓣影片排名采用的是网页局部动态加载技术
2、在检查里,筛选出来了动态加载的请求接口,以及请求的反馈是类json格式(便于后期python解析),以及通过猜想和直接调用接口,找到start和limit两个参数含义
python代码编写
1、User_agent介绍
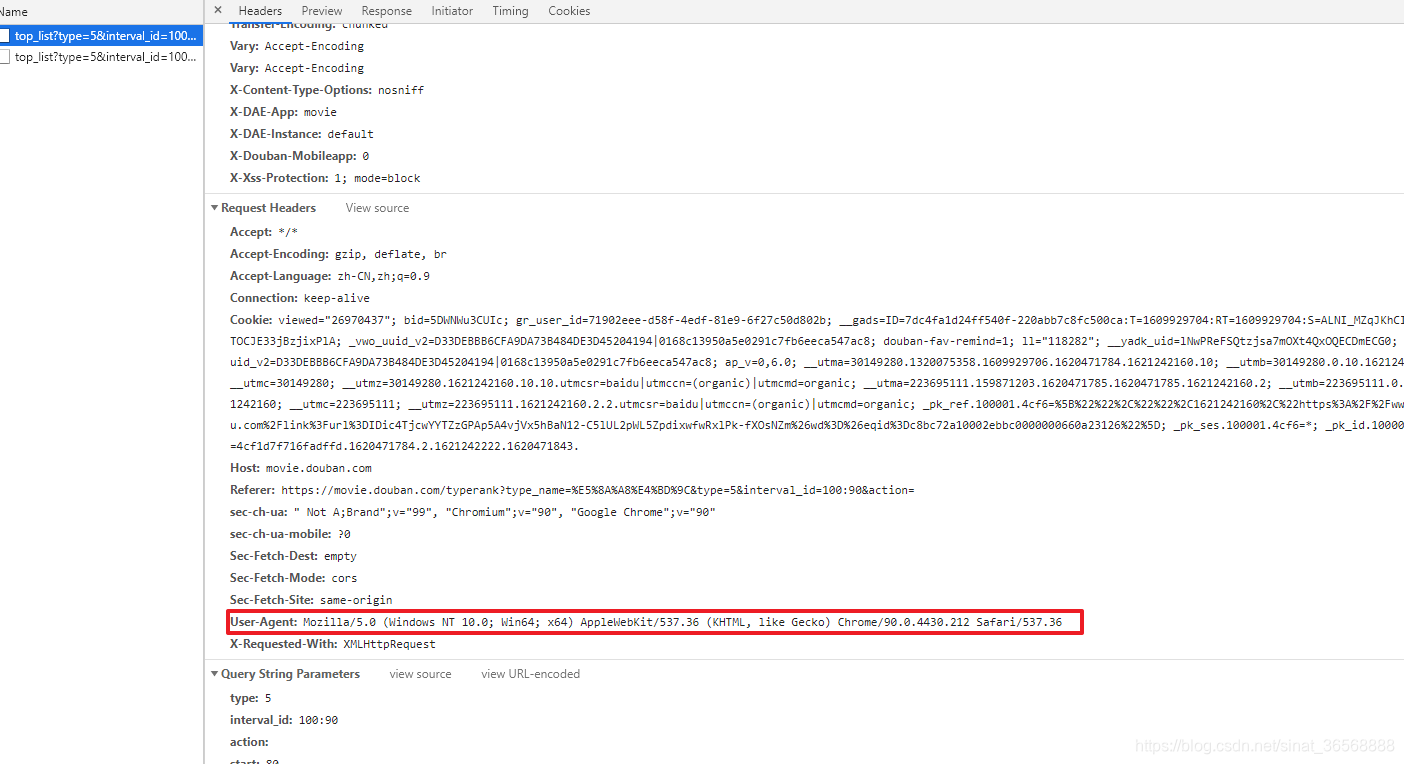
如果你是豆瓣网站的开发者,那你希望别人采用非正规的方式来批量抓取你网站里面的数据吗?稍微想一下,答案肯定是否定的。那么网站服务器怎么确定当前的访问是合法的呢?最基础的方式就是利用请求载体的身份识别信息User_agent来做,不同的浏览器都有不同的身份识别信息
如下是笔者谷歌浏览器的身份识别信息。那么为了防止写的程序求被服务器拒绝访问,在用request模块请求的时候要带上身份识别信息。
2、代码
先直接上代码,及excel数据
```python
import requests
import json
import xlwings as xw
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
response = requests.get(url=url, params=param,headers = headers)
dic_obj = response.json()
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
执行一下,程序已经在正确输出信息了
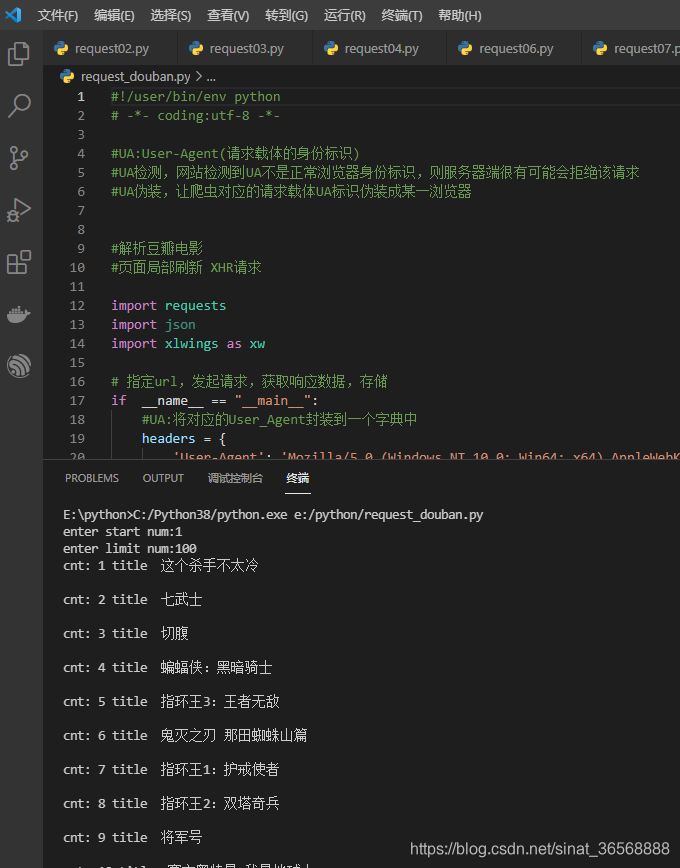
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
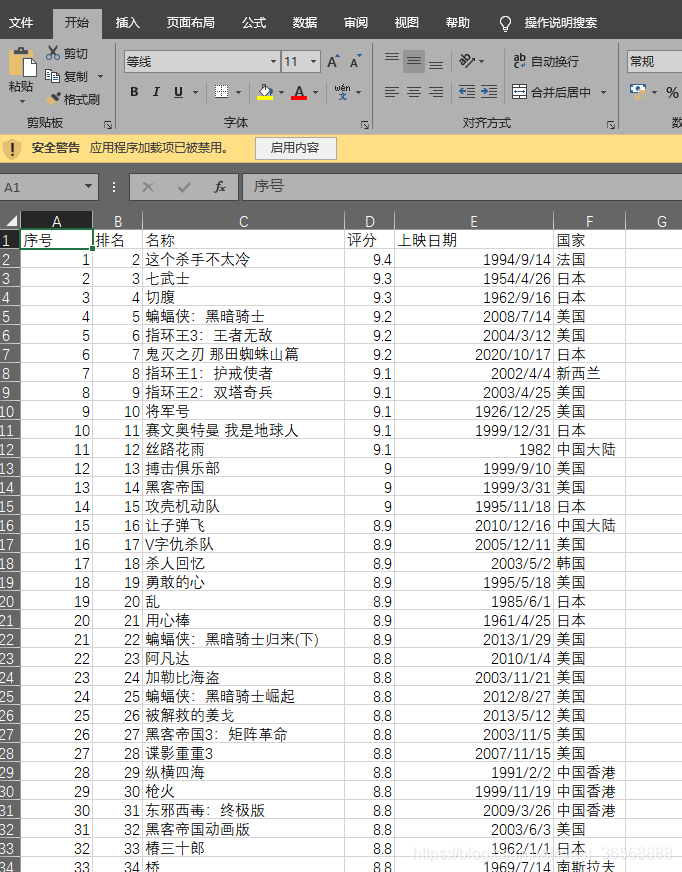
如果在完善下程序,分析页面后发现type是对应的电影类型,5:动作;11:剧情。可以把type全部试出来,然后放入字典里,实现指定抓取某一类型的电影。笔者完成的是动作电影的抓取。
代码分析
使用到的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,可支持xlxs格式文件。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这一部分是定义头,访问接口,以及参数,变化的参数采用终端输入。
response = requests.get(url=url, params=param,headers = headers)
用get命令访问,有的网页采用的可能是post,需要与网页实际的请求方式保持一致。浏览器地址栏里只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这一部分实现,读取返回的json格式数据,转换后的数据实际上是字典。
操作excel5部曲
1、建立APP
2、建立books
3、建立sheet页
4、数据写入
5、保存关闭
sht.range(‘A1’).value=‘序号’
表示向A1单元格写入序号,如果需要向B10写入,就将上面的A1改为B10,操作起来十分方便。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)