一、Tesseract—OCR简介
将图片翻译成文字一般称为光学文字识别(Optical Character Recognition,OCR)。可以实现OCR的底层并不多,目前很多库都是实用共同的几个底层OCR库,或者是在上面进行定制。
Tesseract是一个OCR库,目前由Google赞助。Tesseract是目前公认最优秀、最精确的开源OCR系统
二、下载
https://digi.bib.uni-mannheim.de/tesseract/
1.尽量不要下载dev(开发中的版本),alpha(内部测试版,一般不向外部发布,会有很多Bug),beta(公测版本,即针对所有用户公开的测试版本)等版本。
2.建议下载最新稳定版本:
tesseract-ocr-w64-setup-v5.0.1.20220118.exe
下面进行傻瓜式安装
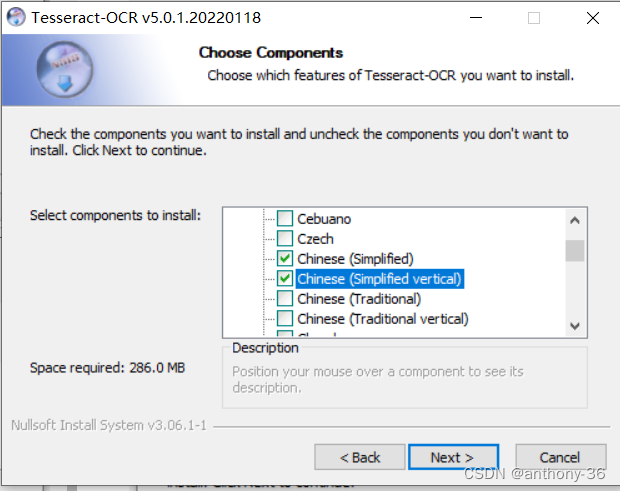
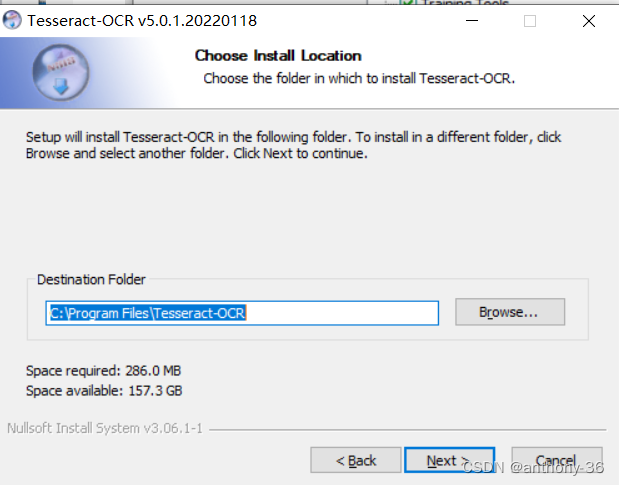
三、下载pytesseract库
在anaconda里面进行安装,然后直接使用anaconda环境就可以。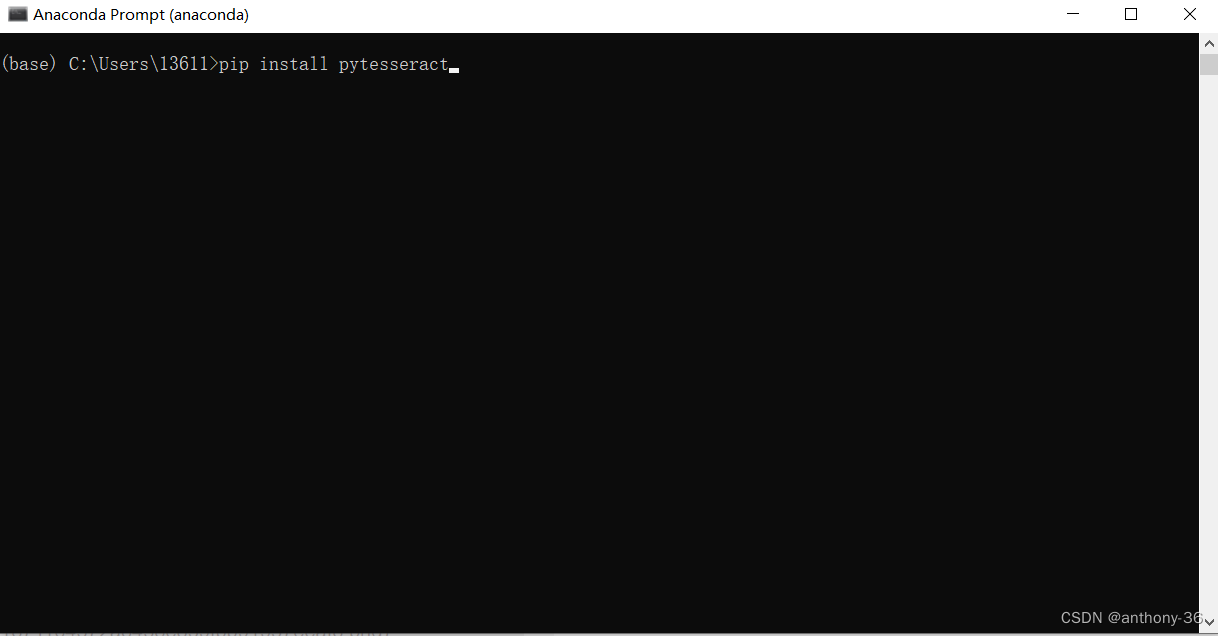
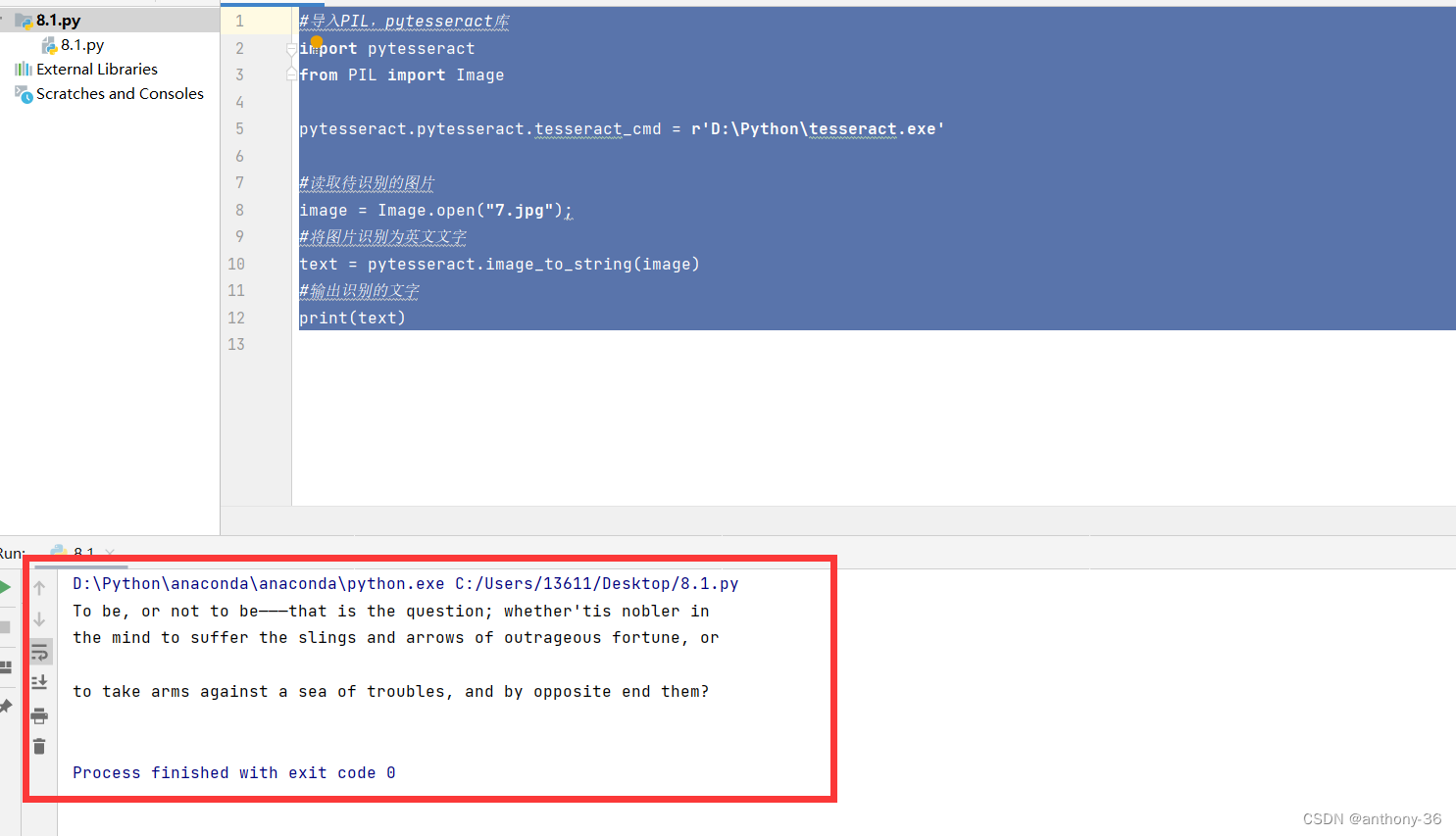
四、识别英文
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'D:\Python\tesseract.exe'
image = Image.open("7.jpg");
text = pytesseract.image_to_string(image)
print(text)
下面是“7.jpg”文件

下面是运行结果
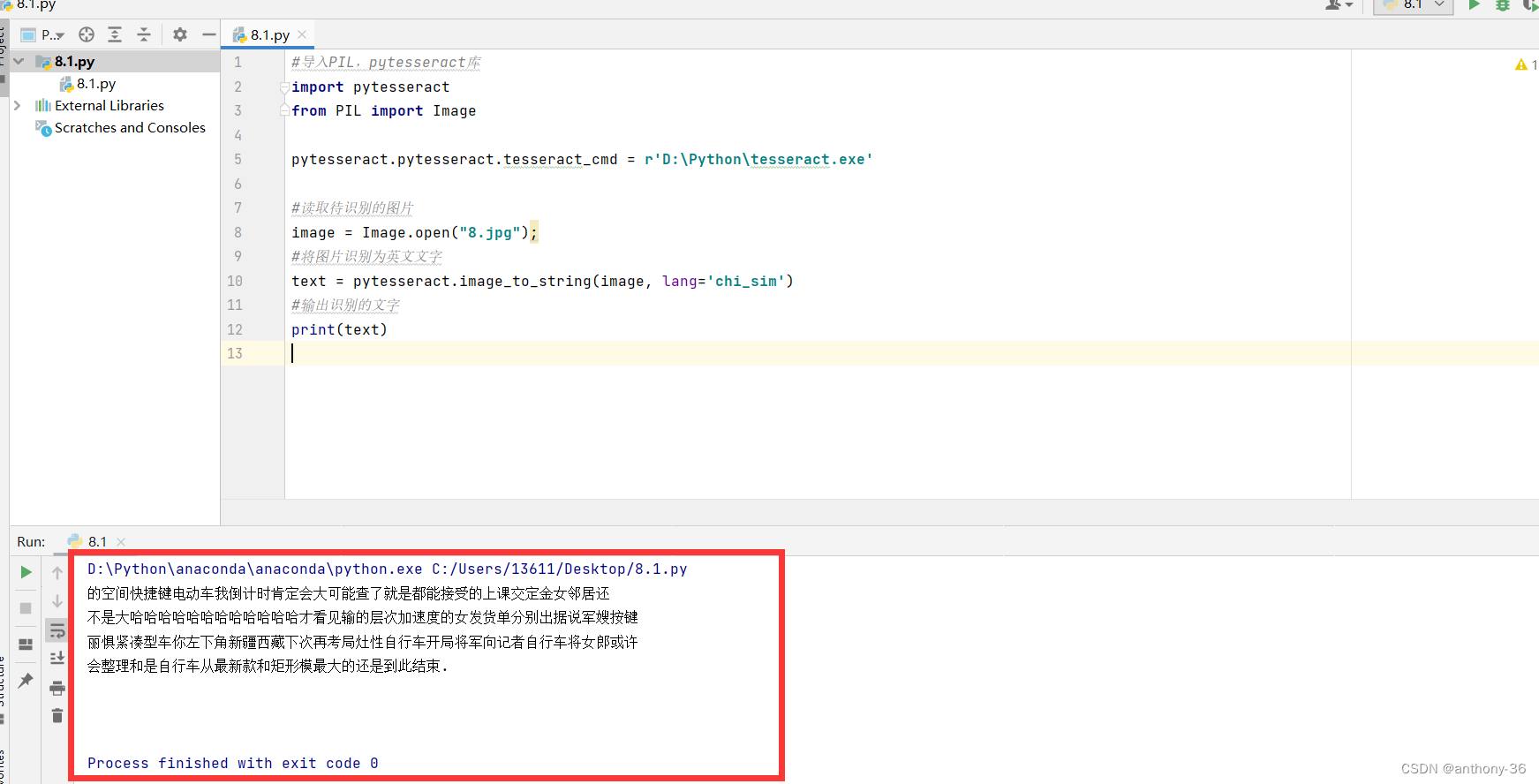
五、识别中文
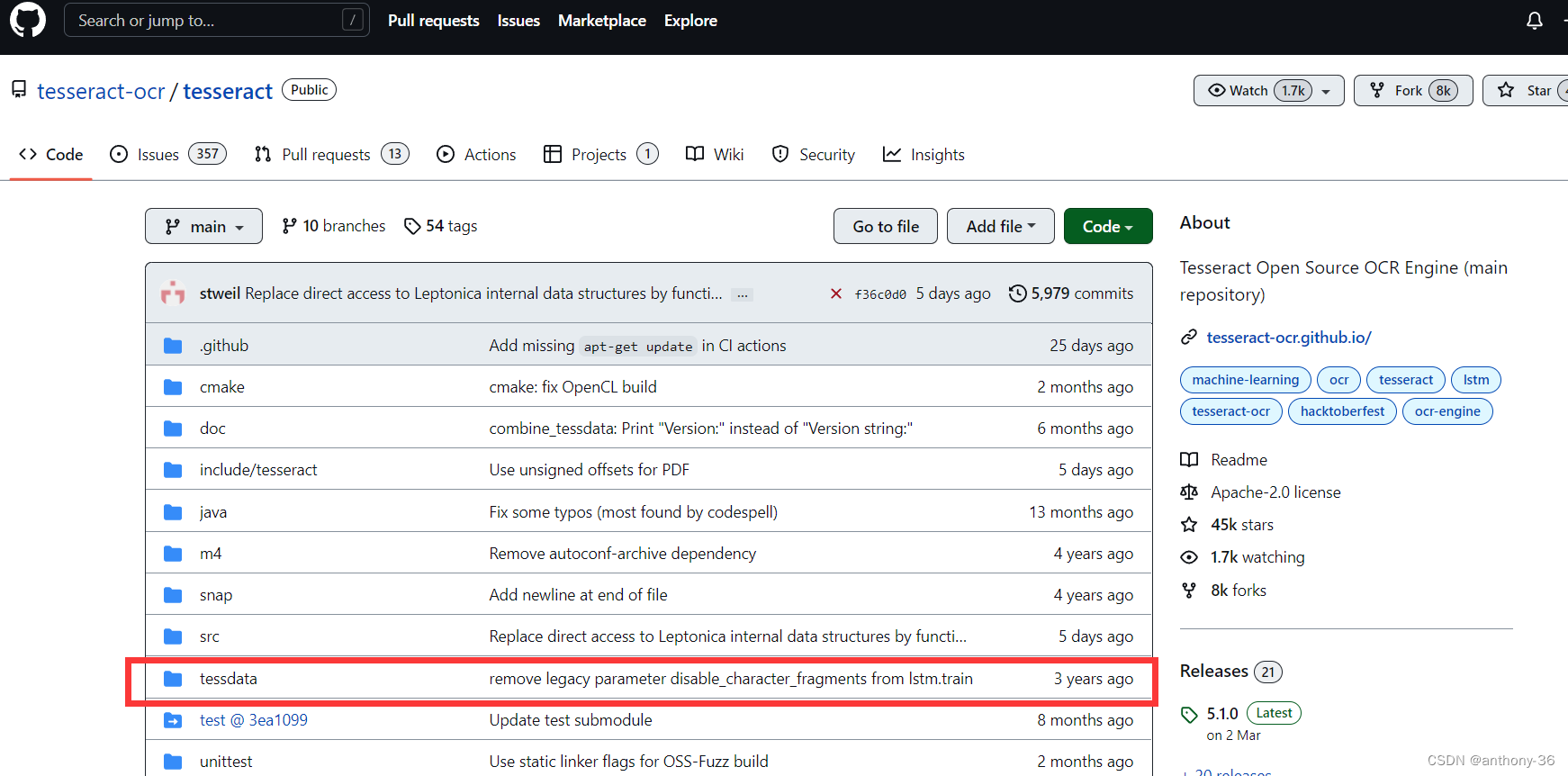
tesseract默认安装可能不带中文简体识别包,需要额外下载。
在github中直接搜索tesseract,下载tessdata文件到Tesseract安装文件中,
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'D:\Python\tesseract.exe'
image = Image.open("8.jpg");
text = pytesseract.image_to_string(image, lang='chi_sim')
print(text)
下面是“8.jpg”文件

下面是识别结果
六、如何识别单个字符
运行过上面代码的同学,如果把输入图像换为单个字母或者文字的图像就会输出失败,例如下面的图片,这里是因为OCR是用作识别多文字的情景,使用单个文字会被认为是图片,就会自动跳过。

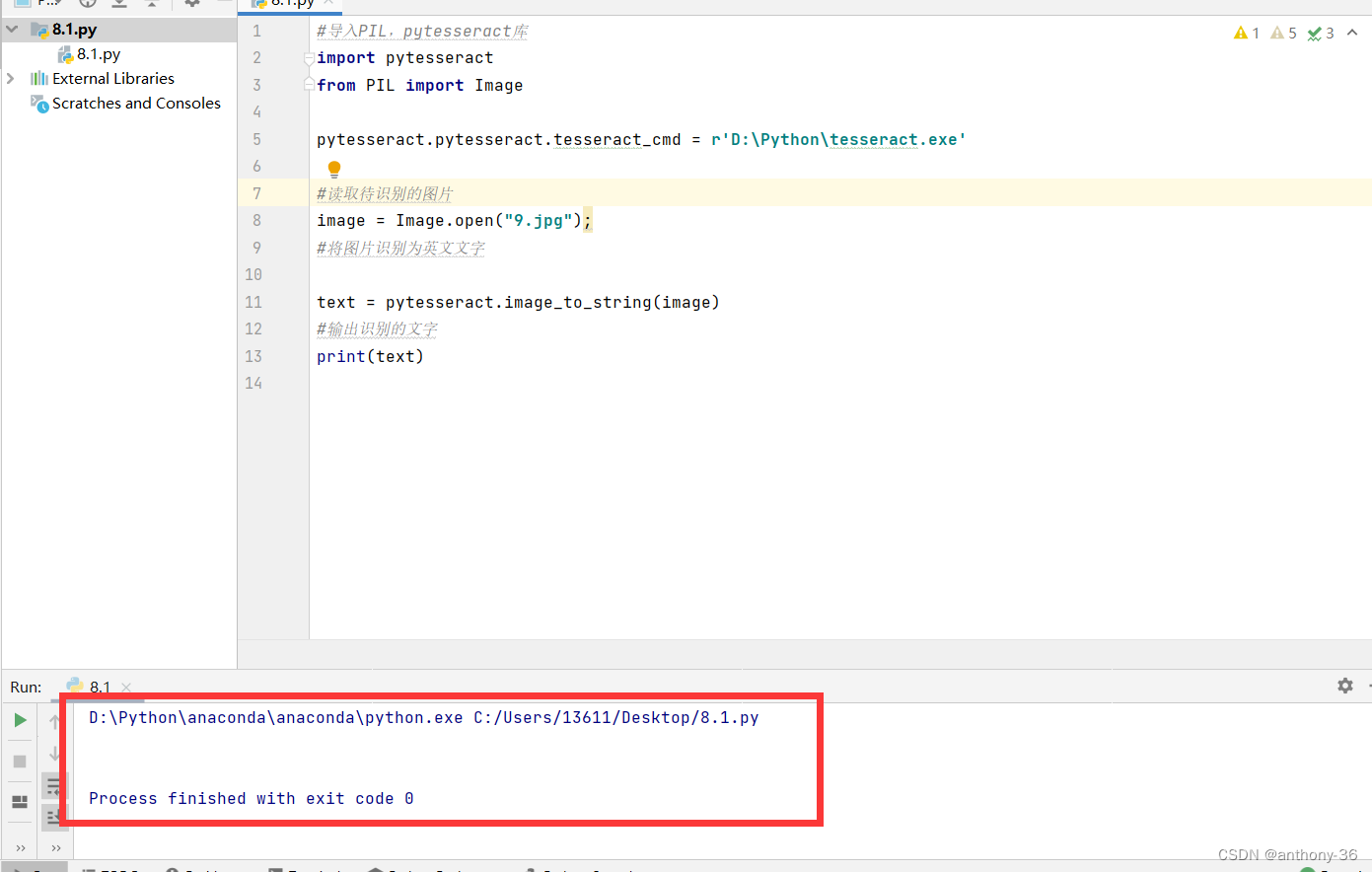
这里怎么解决呢
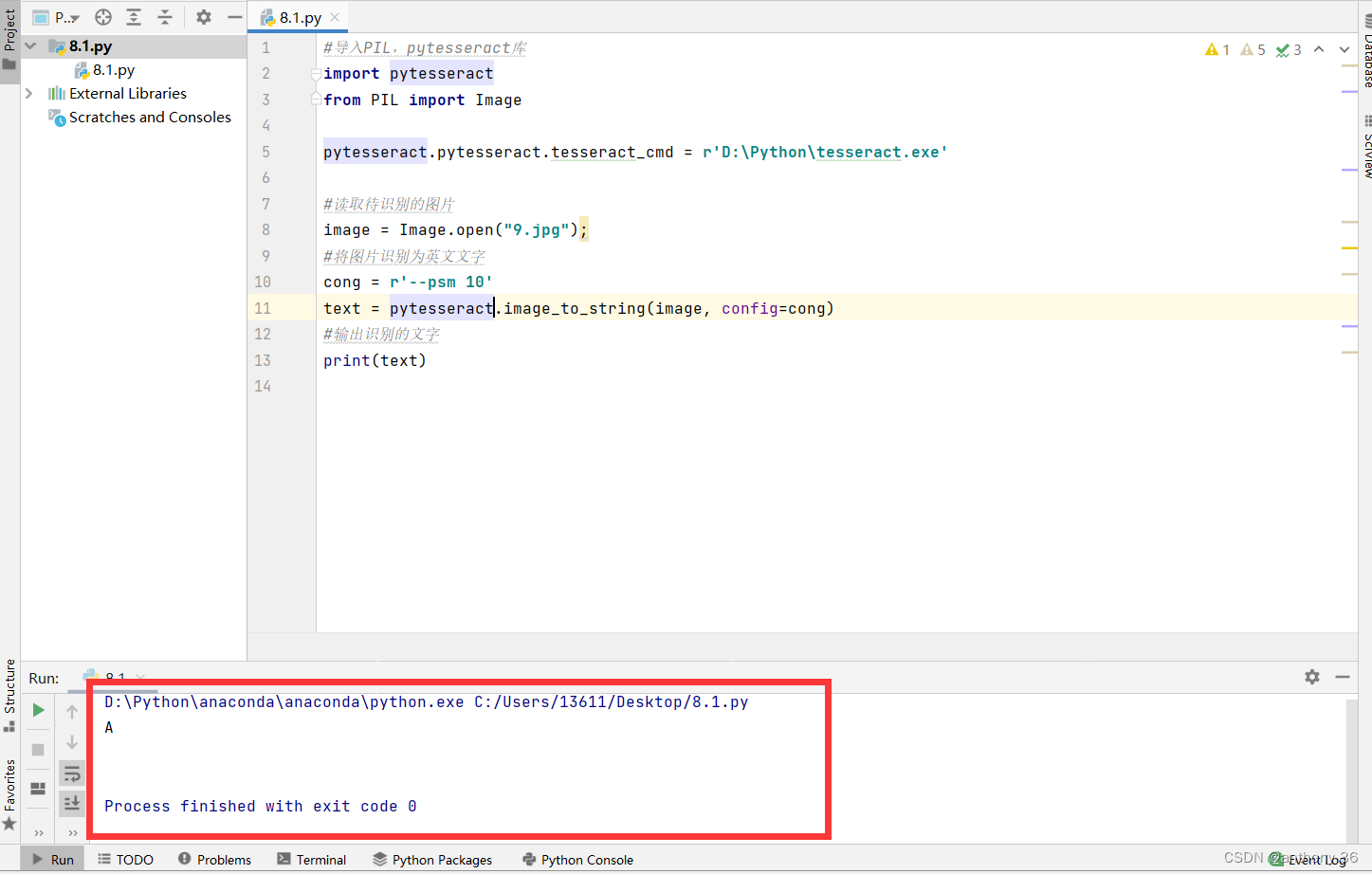
改为如下代码
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'D:\Python\tesseract.exe'
image = Image.open("9.jpg");
cong = r'--psm 10'
text = pytesseract.image_to_string(image, config=cong)
print(text)
添加
cong = r’–psm 10’
text = pytesseract.image_to_string(image, config=cong)
就可以输出了
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)