环境信息:
master1 、master2 、node1 、 node2 k8s 1.22 、 docker 、calico、 node2上有kuboard
问题描述:
dig通过coredns的svc IP,解析pod的fqdn出现connection timed out; no servers could be reached

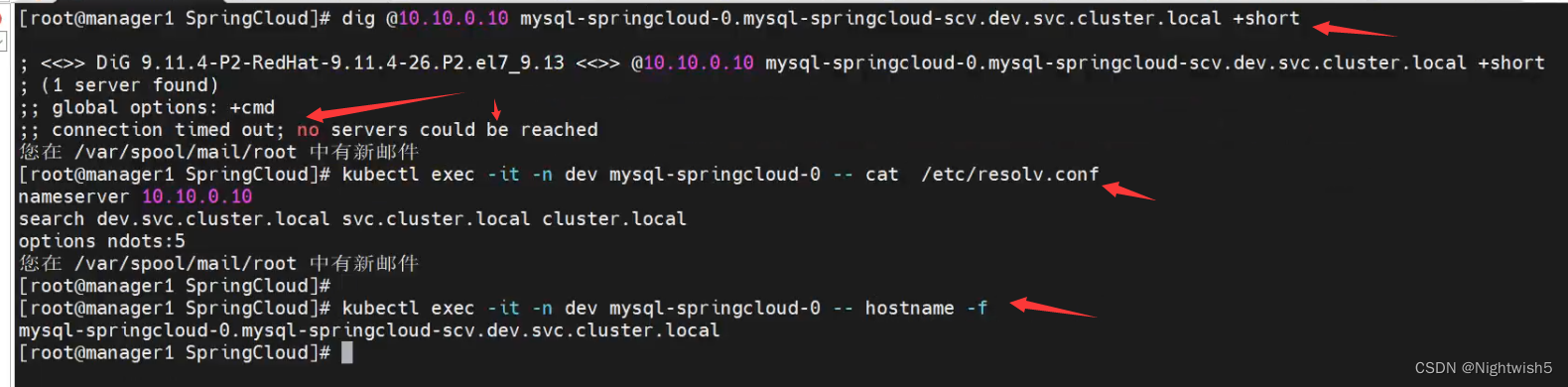
最终处理方法:
删掉node2上的kuboard创建的网络。
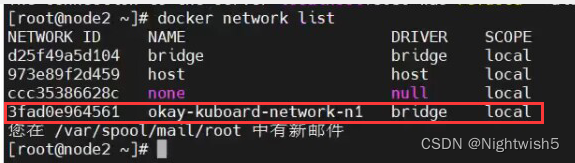

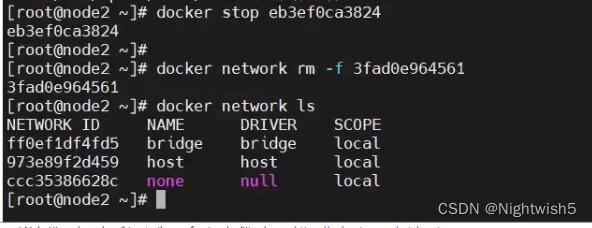
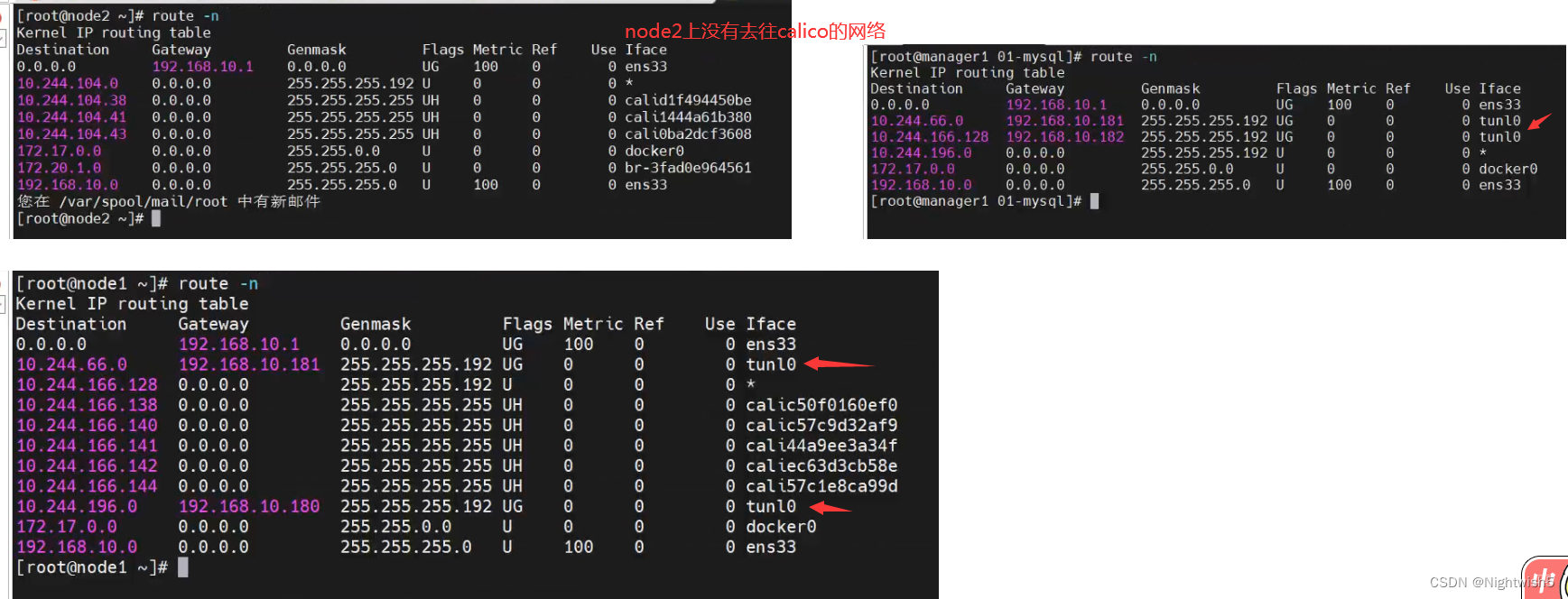
正常的状态: node2也有去往calico的路由信息了
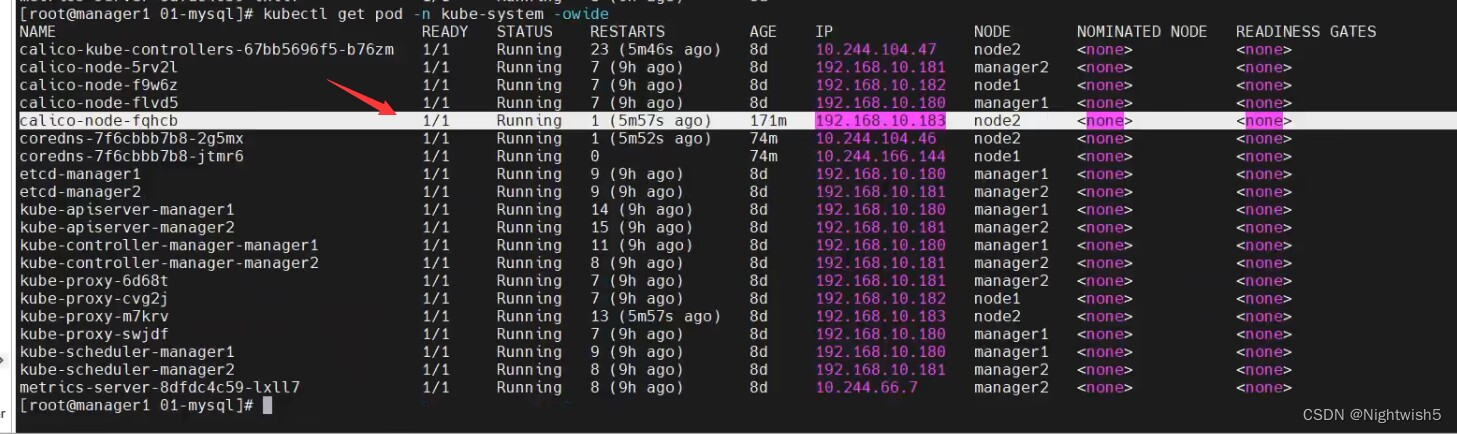
造成“故障”的操作为:
至于为啥会故障/冲突,似懂非懂。 (在创建了docker网络的情况下。容器不会走docker0的?!) ,node2有两个bridge
排查方法(***):
总结下排查方法/思路

根据报错的提示,开始认为是coreDNS出了问题,最终是node2节点上calico插件出了问题。下面通过种种现象来复盘
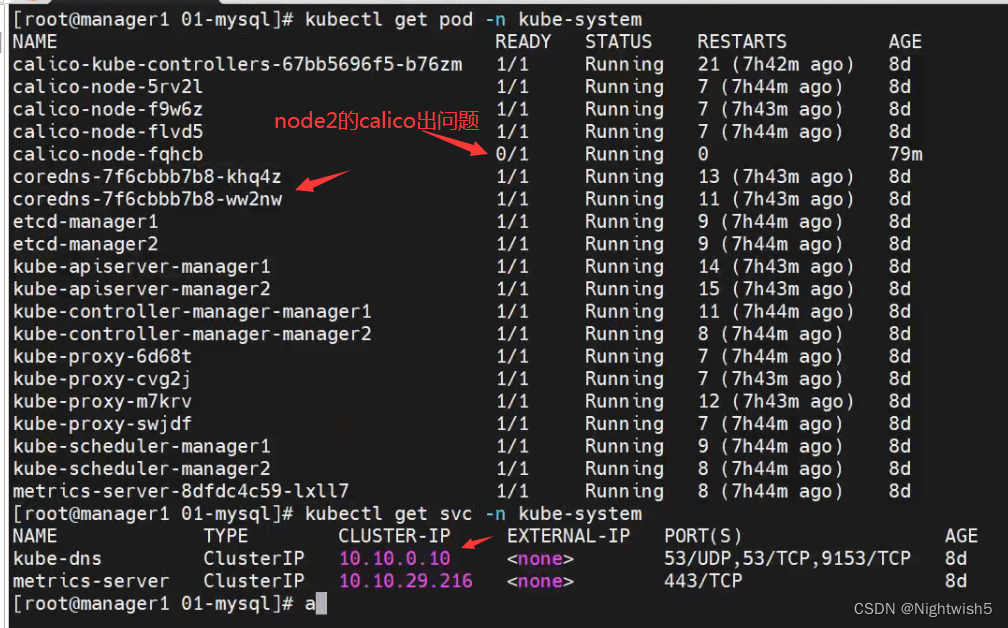
0、看日志 cat /var/log/messages 和systemctl status kubelet
查看 /var/log/messages 和systemctl status kubelet -l
kubectl logs
kubectl describe
但本次报错信息有丶抽象。

注意:coreDNS需要修改configmap,打开log模块,加上log{} ,才会显示出具体日志。
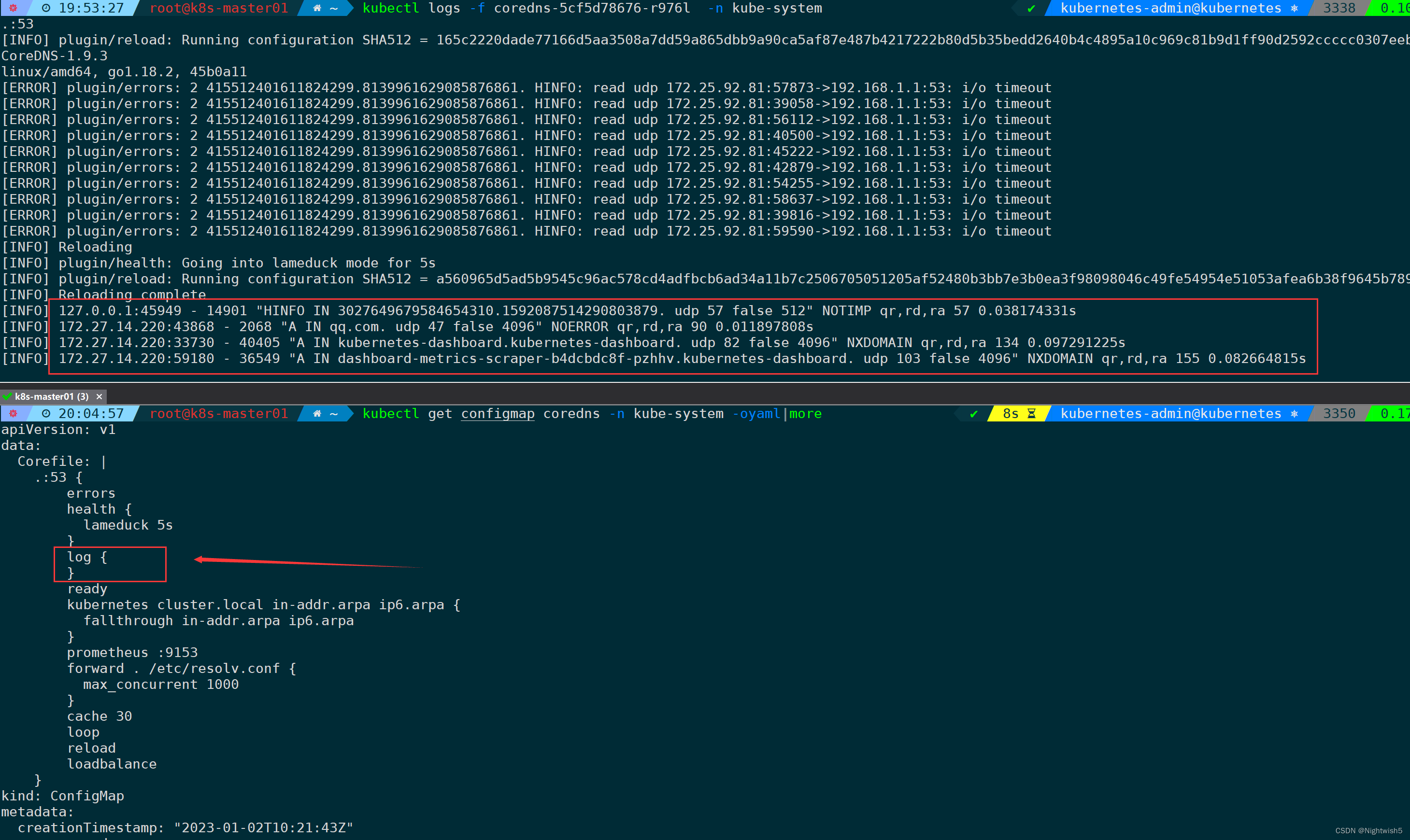
1、对比法rount -n
对比不同节点的rount -n 内容,对比找不同。
2、 从内到外法
在node2使用ping和dig。 发现coreDNS服务是OK,所以兜兜转转后,还是calico的问题。
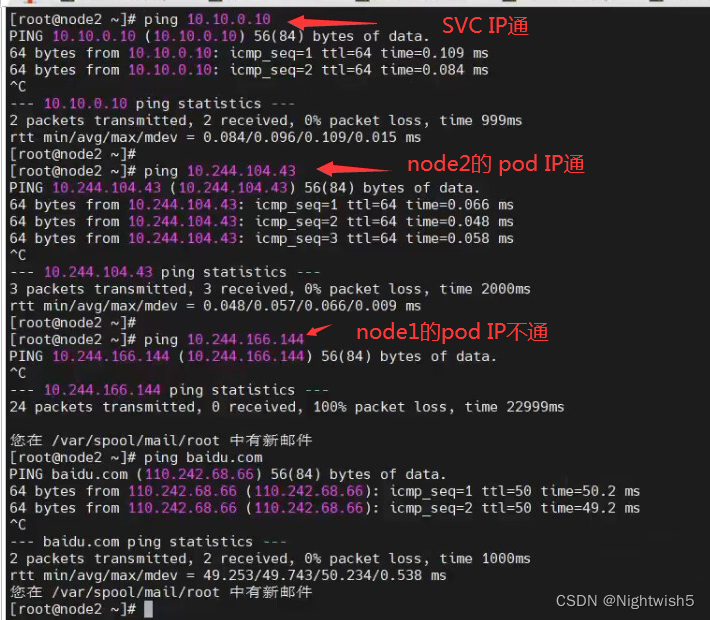
3 、ping coreDNS的POD IP 和使用dig coreDNS的POD IP
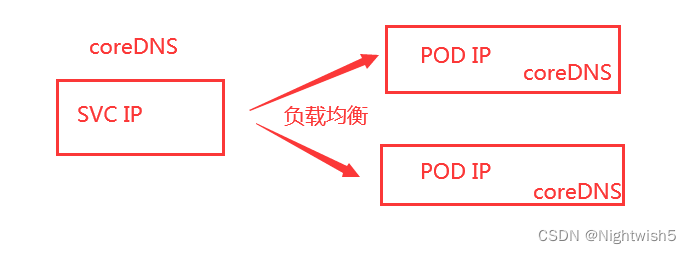
svc到负载的每个pod ip
ping coredns的POD IP
正常的情况是都能ping通的(master、node1 、node2)
3.1、master节点操作 ping
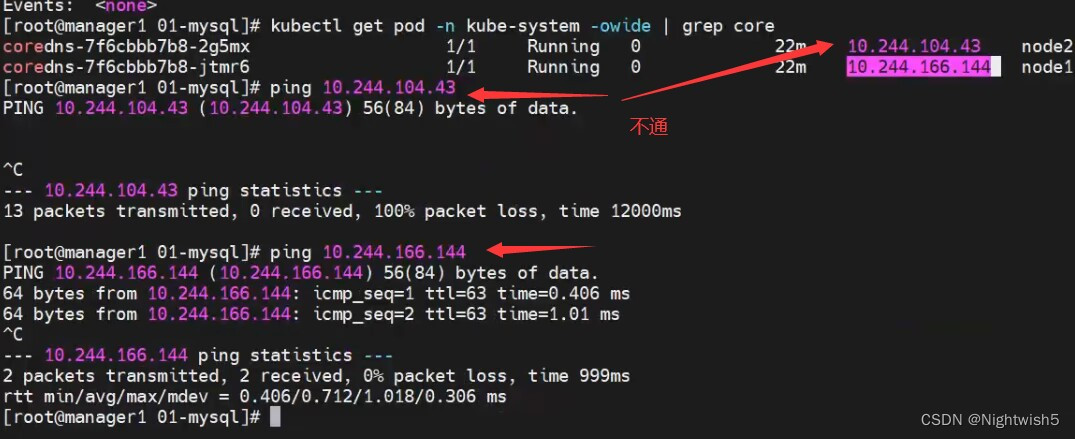
node1的coreDNS日志:

node2的coreDNS还是没日志
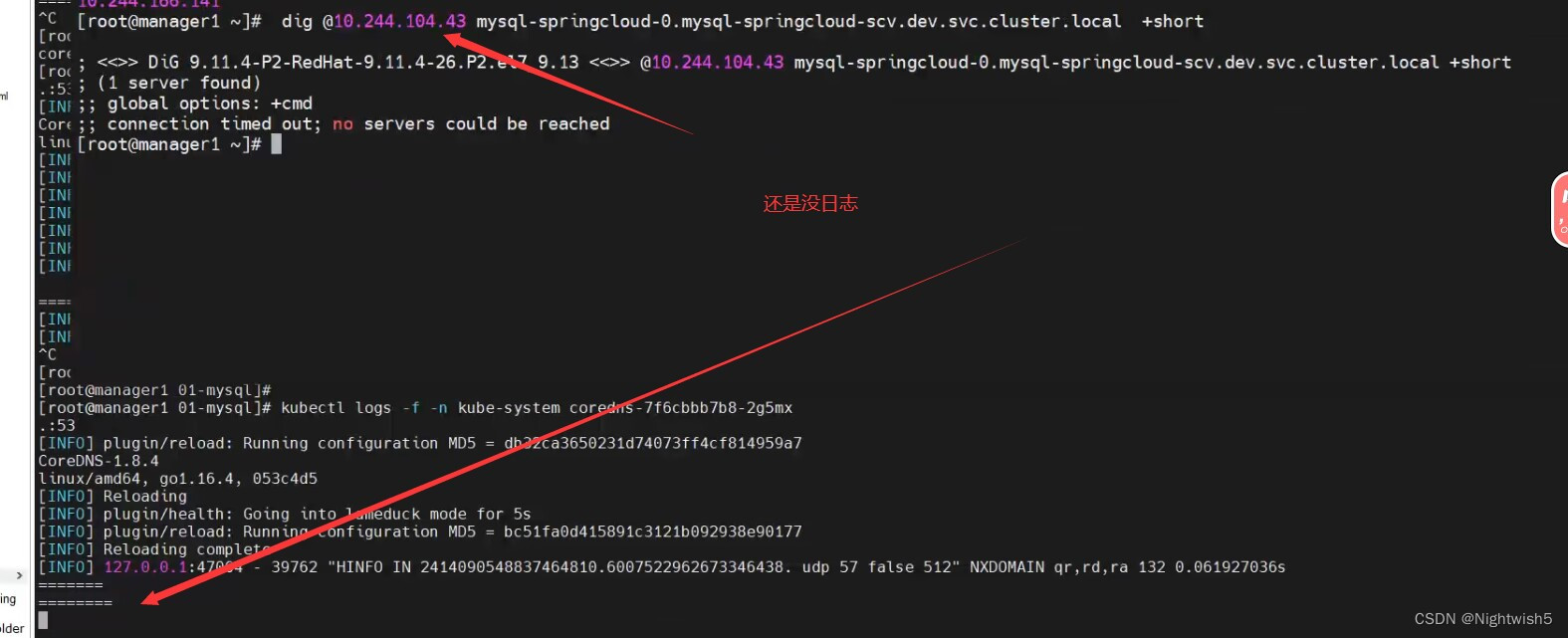
3.2、使用dig coreDNS的POD IP
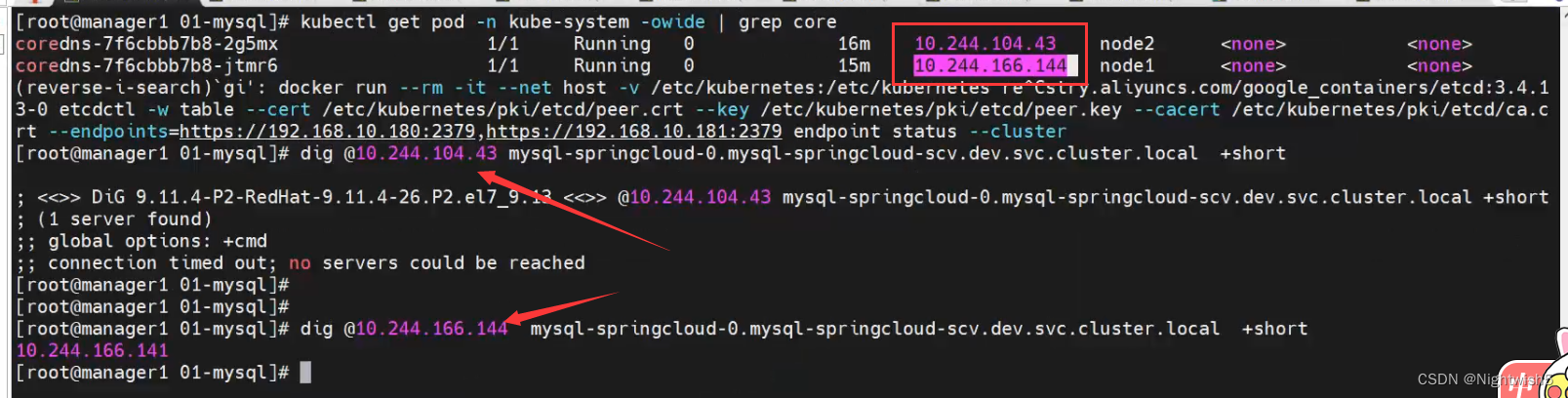
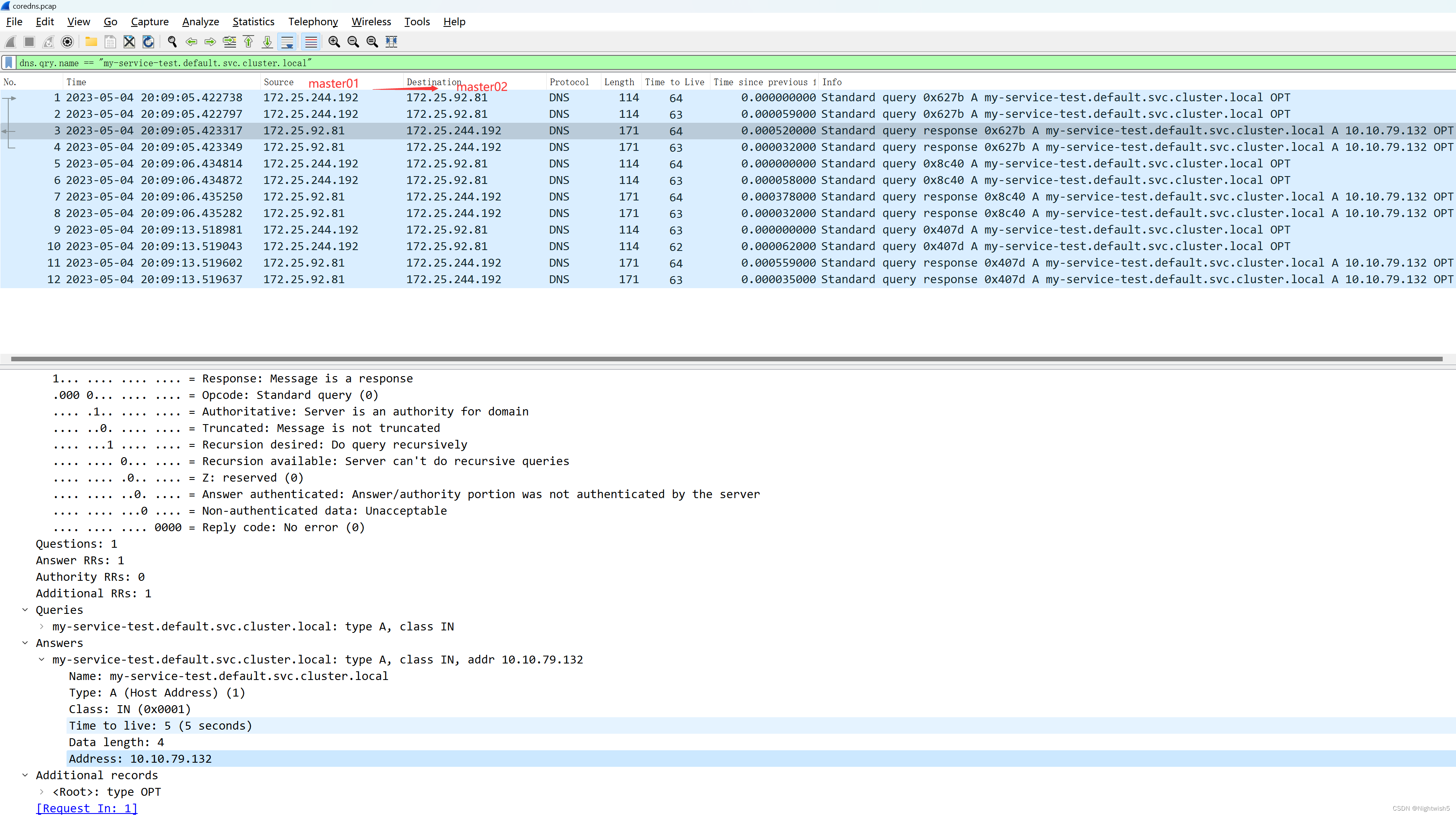
4、tcpdump抓包排查法 (node2操作)
没日志,而且ping不通,说明请求压根没到,在node02 tcpdump试试
tcpdump -i any -nn -s 0 icmp or port 53 -v
小结
k8s网络方面故障,看docker network 、 calico 、 coreDNS 、 rount -n
感谢PD, oldxu群里面的高手们。如果不是本人,可能看文章感觉有丶乱,
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)