SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
一、数据集-KITTI
1.1 输入
- 单张图像:1242x375,格式.png


- calib,标定数据,格式txt,每张图像对应一个,必须
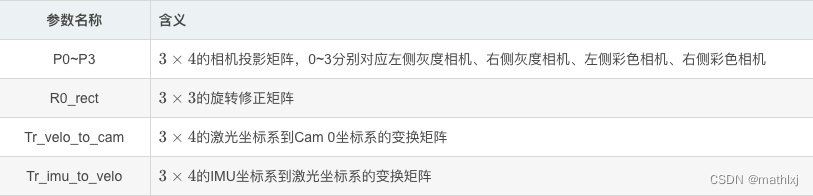
P0: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 0.000000000000e+00 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 -3.797842000000e+02 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 4.575831000000e+01 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 -3.454157000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 4.981016000000e-03
P3: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 -3.341081000000e+02 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 2.330660000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 3.201153000000e-03
R0_rect: 9.999128000000e-01 1.009263000000e-02 -8.511932000000e-03 -1.012729000000e-02 9.999406000000e-01 -4.037671000000e-03 8.470675000000e-03 4.123522000000e-03 9.999556000000e-01
Tr_velo_to_cam: 6.927964000000e-03 -9.999722000000e-01 -2.757829000000e-03 -2.457729000000e-02 -1.162982000000e-03 2.749836000000e-03 -9.999955000000e-01 -6.127237000000e-02 9.999753000000e-01 6.931141000000e-03 -1.143899000000e-03 -3.321029000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
- Velodyne: 64线3D激光雷达,格式.bin,模型没有用到。
1.2 label
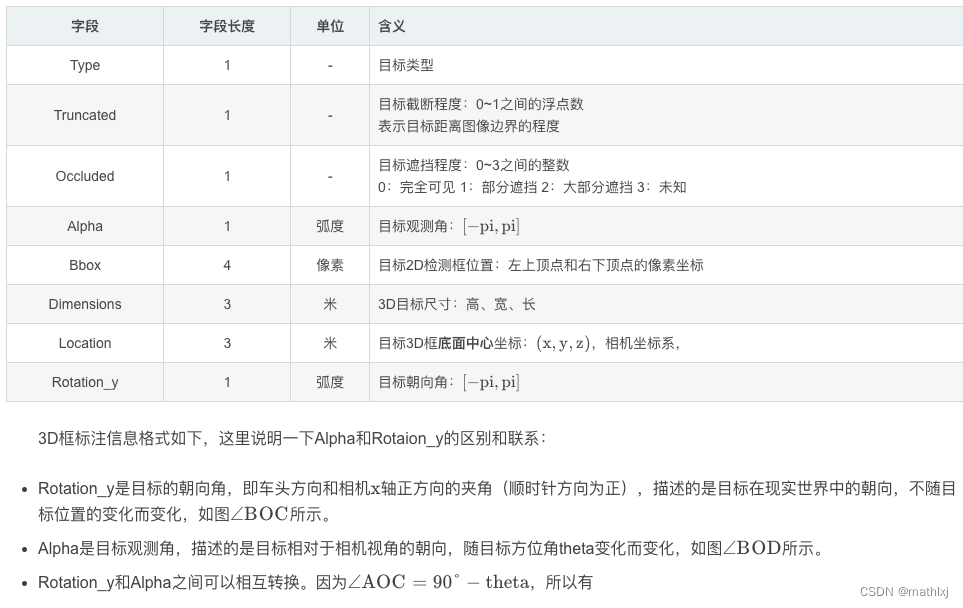
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
- 类别: ’Road’, ’City’, ’Residential’, ’Campus’ 和’Person’五类
二、安装
我们在Jeston Xavier上安装github代码.
由于Xavier无法安装MAGMA,需要将代码中求逆的操作改为在cpu上运行,该操作对推断用时增加10ms左右,影响不大。
三、推断速度
- Batch size = 1
- Backbone: dla34
- 环境:Python3
- 模型:官方预训练
- 配置如下
2022-12-02 17:39:14,267] smoke INFO: Namespace(ckpt=None, config_file='configs/smoke_gn_vector.yaml', dist_url='tcp://127.0.0.1:50152', eval_only=True, machine_rank=0, num_gpus=1, num_machines=1, opts=[])
[2022-12-02 17:39:14,268] smoke INFO: Loaded configuration file configs/smoke_gn_vector.yaml
[2022-12-02 17:39:14,268] smoke INFO:
MODEL:
WEIGHT: "catalog://ImageNetPretrained/DLA34"
INPUT:
FLIP_PROB_TRAIN: 0.5
SHIFT_SCALE_PROB_TRAIN: 0.3
DATASETS:
DETECT_CLASSES: ("Car", "Cyclist", "Pedestrian")
TRAIN: ("kitti_train",)
TEST: ("kitti_test",)
TRAIN_SPLIT: "trainval"
TEST_SPLIT: "test"
SOLVER:
BASE_LR: 2.5e-4
STEPS: (10000, 18000)
MAX_ITERATION: 25000
IMS_PER_BATCH: 1
[2022-12-02 17:39:14,270] smoke INFO: Running with config:
CUDNN_BENCHMARK: True
DATALOADER:
ASPECT_RATIO_GROUPING: False
NUM_WORKERS: 4
SIZE_DIVISIBILITY: 0
DATASETS:
DETECT_CLASSES: ('Car', 'Cyclist', 'Pedestrian')
MAX_OBJECTS: 30
TEST: ('kitti_test',)
TEST_SPLIT: test
TRAIN: ('kitti_train',)
TRAIN_SPLIT: trainval
INPUT:
FLIP_PROB_TRAIN: 0.5
HEIGHT_TEST: 384
HEIGHT_TRAIN: 384
PIXEL_MEAN: [0.485, 0.456, 0.406]
PIXEL_STD: [0.229, 0.224, 0.225]
SHIFT_SCALE_PROB_TRAIN: 0.3
SHIFT_SCALE_TRAIN: (0.2, 0.4)
TO_BGR: True
WIDTH_TEST: 1280
WIDTH_TRAIN: 1280
MODEL:
BACKBONE:
BACKBONE_OUT_CHANNELS: 64
CONV_BODY: DLA-34-DCN
DOWN_RATIO: 4
FREEZE_CONV_BODY_AT: 0
USE_NORMALIZATION: GN
DEVICE: cuda
GROUP_NORM:
DIM_PER_GP: -1
EPSILON: 1e-05
NUM_GROUPS: 32
SMOKE_HEAD:
DEPTH_REFERENCE: (28.01, 16.32)
DIMENSION_REFERENCE: ((3.88, 1.63, 1.53), (1.78, 1.7, 0.58), (0.88, 1.73, 0.67))
LOSS_ALPHA: 2
LOSS_BETA: 4
LOSS_TYPE: ('FocalLoss', 'DisL1')
LOSS_WEIGHT: (1.0, 10.0)
NUM_CHANNEL: 256
PREDICTOR: SMOKEPredictor
REGRESSION_CHANNEL: (1, 2, 3, 2)
REGRESSION_HEADS: 8
USE_NMS: False
USE_NORMALIZATION: GN
SMOKE_ON: True
WEIGHT: catalog://ImageNetPretrained/DLA34
OUTPUT_DIR: ./tools/logs
PATHS_CATALOG: /home/autoware/SMOKE/smoke/config/paths_catalog.py
SEED: -1
SOLVER:
BASE_LR: 0.00025
BIAS_LR_FACTOR: 2
CHECKPOINT_PERIOD: 20
EVALUATE_PERIOD: 20
IMS_PER_BATCH: 1
LOAD_OPTIMIZER_SCHEDULER: True
MASTER_BATCH: -1
MAX_ITERATION: 25000
OPTIMIZER: Adam
STEPS: (10000, 18000)
TEST:
DETECTIONS_PER_IMG: 50
DETECTIONS_THRESHOLD: 0.25
IMS_PER_BATCH: 1
PRED_2D: True
SINGLE_GPU_TEST: True
3.1 论文报告Titan Xp
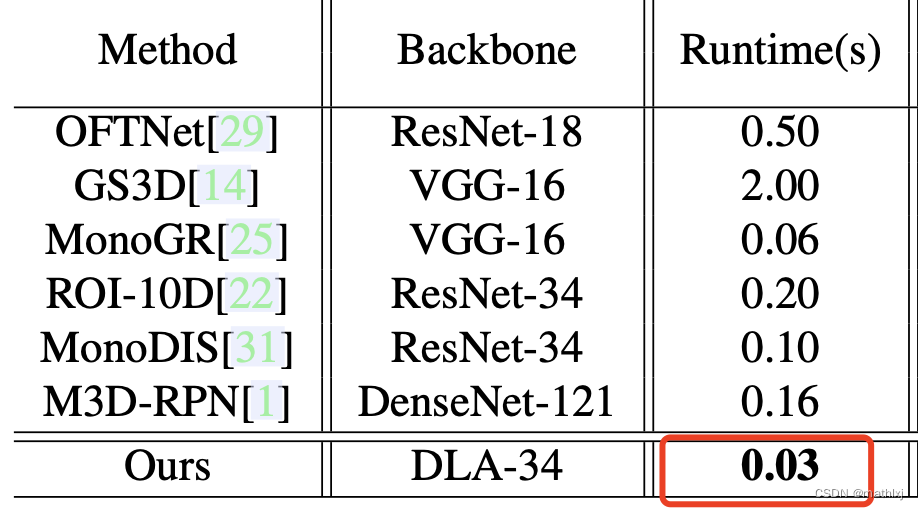
30ms/张在Titan Xp上。
3.2 Xavier实测
- 单张耗时: 300ms/张在Xavier上
根据CUDA核计算,Titan X大概是Xavier的7倍,测算还比较合理。


四、输出
模型实际输出log的例子
Cyclist 0 0 1.038100004196167 724.3541870117188 181.3260955810547 756.7017211914062 224.00320434570312 1.656000018119812 0.5224999785423279 1.617400050163269 5.4492998123168945 1.6898000240325928 28.31760025024414 1.2281999588012695 0.251800000667572
Pedestrian 0 0 0.9455000162124634 322.6777038574219 228.24049377441406 347.2066955566406 268.2008056640625 1.6103999614715576 0.6126000285148621 0.8202000260353088 -11.46679973602295 3.6767001152038574 30.125600814819336 0.5817999839782715 0.25110000371932983
虽然模型中没有显式建模2D bbox,2D bbox通过求将3D bbox映射到图像平面后最小外接矩形获得。
五、衡量指标
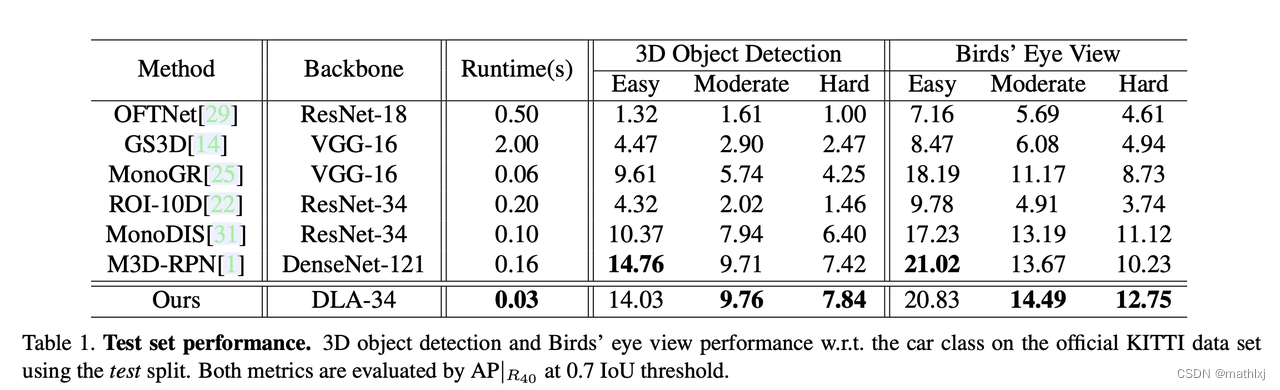
- AP@0.7: average precision (AP) with IoU.
分为: 3D object detection 和 BEV,都是用AP - 精度水平:2019年底KITTI单目3D检测第一名。
- 3D Object Detection Evaluation 2017
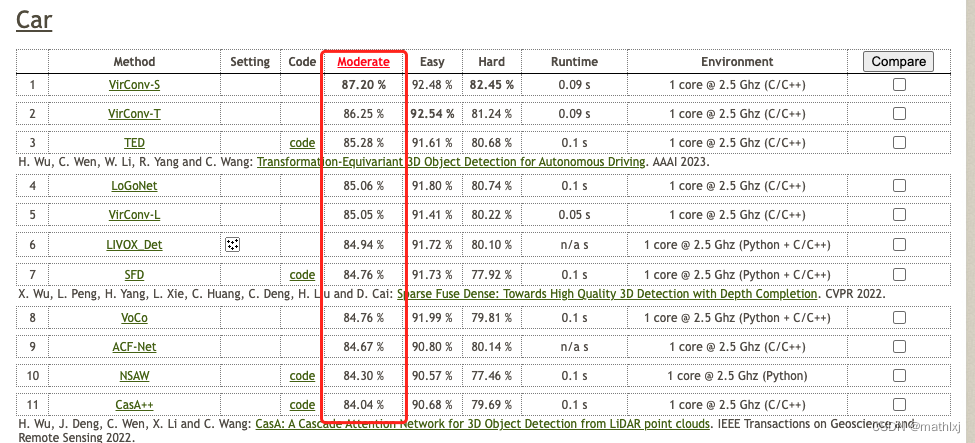
目前在所有方法(包含多目、使用雷达等)排名第417.

当前较高水平:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)