树莓派3B+ 人脸识别(OpenCV)
相信大家都看了前面的OpenCV安装和人脸检测教程,已经跃跃欲试,想要进行人脸识别了,现在我们正式进入重头戏——人脸识别 的教程。
注意:该教程面向python2.7+OpenCV2.4.9(官方源)
其它版本需进行一些小的修改,文中会具体注明。
1.生成人脸识别数据
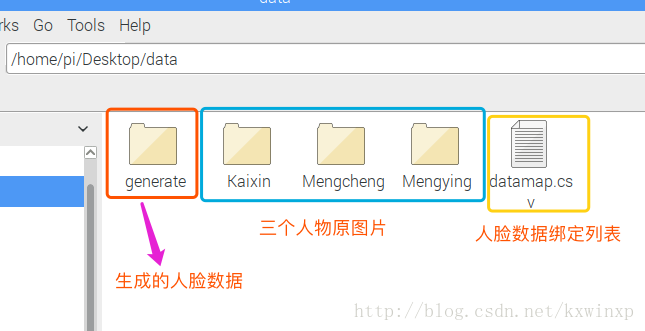
目录结构
./data 数据根目录
./data/generate 自动生成的人脸数据
./data/datamap.csv 人脸数据对应数据
./data/Mengcheng 人物一文件夹
./data/Kaixin 人物二文件夹
./data/Mengying 人物三文件夹
(这里三个人物可自行修改,文件夹为人物名,里面存放图片)
// python脚本,请保存为genrate.py
import cv2
import os
import sys
face_cascade=cv2.CascadeClassifier('/usr/share/opencv/haarcascades/haarcascade_frontalface_default.xml')
def makedir(path):
path=path.strip().rstrip('/')
if os.path.exists(path) is False:
os.makedirs( path );
def generate(root_argv,dirname):
subject_dir_path = os.path.join(root_argv, dirname)
print 'seek:'+subject_dir_path
count=0
for filename in os.listdir(subject_dir_path):
if filename == ".directory":
continue
imgPath = os.path.join(subject_dir_path, filename)
try:
print 'read:'+imgPath
img = cv2.imread(imgPath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
outdir=os.path.join(root_argv,'generate',dirname)
makedir(outdir)
faces=face_cascade.detectMultiScale(gray,1.3,5)
for x,y,w,h in faces:
f=cv2.resize(gray[y:y+h,x:x+w],(200,200))
outPath=os.path.join(root_argv,'generate',dirname,'%s.pgm' % str(count))
print 'write:'+ outPath
cv2.imwrite(outPath, f)
count+=1
except:
pass
if __name__ == '__main__':
if len(sys.argv)==1:
print ("USAGE: generate.py <人脸图片存放路径>")
exit(0)
root_argv=sys.argv[1]
for dirname in os.listdir(root_argv):
file_path = os.path.join(root_argv, dirname)
if os.path.isdir(file_path):
if dirname == 'generate':
continue
generate(root_argv,dirname)
在控制台执行python generate.py ./data即可自动生成人脸识别数据
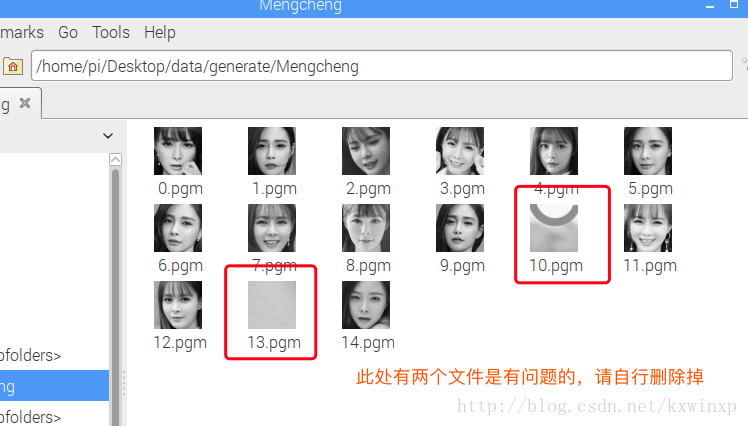
生成后,请自行打开./data/generate/下生成人脸数据是否正常,如果不正常的,请清理掉,防止后续有干扰。如图:
2.生成人脸数据对应表
人脸数据生成了,还得有一个人物<->名称映射表,让机器知道人脸数据对应那个人物。
// python脚本,请保存为create_csv.py
import sys
import os.path
if __name__ == '__main__':
if len(sys.argv) != 2:
print "usage: create_csv.py <生成的人脸数据路径>"
sys.exit(0)
BASE_PATH=sys.argv[1]
SEPARATOR=";"
label = 0
for dirpath, dirnames, filenames in os.walk(BASE_PATH):
for subdirname in dirnames:
subject_path = os.path.join(dirpath, subdirname)
for filename in os.listdir(subject_path):
image_filename = subject_path + "/"+ filename
abs_path = "%s/%s" % (subject_path, filename)
print("%s%s%d"%(abs_path,SEPARATOR, label))
label = label + 1
然后执行python create_csv.py ./data/generate/ > ./data/datamap.csv
打开生成的datamap.csv文件,检查对应关系(如图所示):
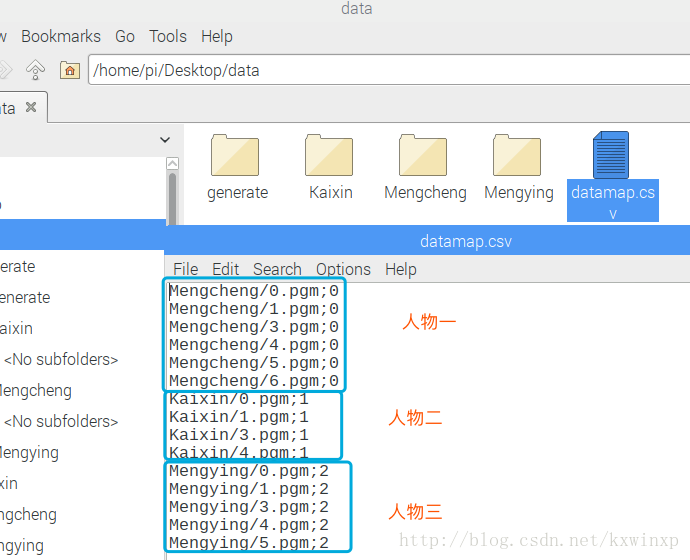
这样,人脸数据就准备好了。
3.人脸识别
使用样图,使用树莓派摄像头获取图片。
// python脚本,请保存为facerec.py
import multiprocessing as mp
import cv2
import os
import sys
import time
import numpy as np
resX = 640
resY = 480
face_cascade = cv2.CascadeClassifier('/usr/share/opencv/lbpcascades/lbpcascade_frontalface.xml')
model = cv2.createFisherFaceRecognizer()
t_start = time.time()
fps = 0
def normalize(X, low, high, dtype=None):
"""Normalizes a given array in X to a value between low and high."""
X = np.asarray(X)
minX, maxX = np.min(X), np.max(X)
X = X - float(minX)
X = X / float((maxX - minX))
X = X * (high-low)
X = X + low
if dtype is None:
return np.asarray(X)
return np.asarray(X, dtype=dtype)
def load_images(path, sz=None):
c = 0
X,y = [], []
for dirname, dirnames, filenames in os.walk(path):
for subdirname in dirnames:
subject_path = os.path.join(dirname, subdirname)
for filename in os.listdir(subject_path):
try:
filepath = os.path.join(subject_path, filename)
if os.path.isdir(filepath):
continue
img = cv2.imread(os.path.join(subject_path, filename), cv2.IMREAD_GRAYSCALE)
if (img is None):
print ("image " + filepath + " is none")
else:
print (filepath)
if (sz is not None):
img = cv2.resize(img, (200, 200))
X.append(np.asarray(img, dtype=np.uint8))
y.append(c)
except:
print ("Unexpected error:", sys.exc_info()[0])
raise
print (c)
c = c+1
print (y)
return [X,y]
def get_faces( img ):
gray = cv2.cvtColor( img, cv2.COLOR_BGR2GRAY )
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
return faces, img, gray
def draw_frame( faces, img, gray ):
global xdeg
global ydeg
global fps
global time_t
for ( x, y, w, h ) in faces:
cv2.rectangle( img, ( x, y ),( x + w, y + h ), ( 200, 255, 0 ), 2 )
roi = gray[x:x+w, y:y+h]
try:
roi = cv2.resize(roi, (200, 200), interpolation=cv2.INTER_LINEAR)
params = model.predict(roi)
sign=("%s %.2f" % (names[params[0]], params[1]))
cv2.putText(img, sign, (x, y-2), cv2.FONT_HERSHEY_SIMPLEX, 0.5, ( 0, 0, 255 ), 2 )
if (params[0] == 0):
cv2.imwrite('face_rec.jpg', img)
except:
continue
fps = fps + 1
sfps = fps / (time.time() - t_start)
cv2.putText(img, "FPS : " + str( int( sfps ) ), ( 10, 15 ), cv2.FONT_HERSHEY_SIMPLEX, 0.5, ( 0, 0, 255 ), 2 )
cv2.imshow( "recognize-face", img )
if __name__ == '__main__':
camera = cv2.VideoCapture(0)
camera.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH,resX)
camera.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT,resY)
pool = mp.Pool( processes=4 )
names = ['Mengying', 'Kaixin', 'Mengcheng']
if len(sys.argv) < 2:
print ("USAGE: facerec.py <人脸数据存放路径> [<数据对应表>]")
sys.exit()
[X,y] = load_images(sys.argv[1])
y = np.asarray(y, dtype=np.int32)
if len(sys.argv) == 3:
out_dir = sys.argv[2]
model.train(np.asarray(X), np.asarray(y))
read, img = camera.read()
pr1 = pool.apply_async( get_faces, [ img ] )
read, img = camera.read()
pr2 = pool.apply_async( get_faces, [ img ] )
read, img = camera.read()
pr3 = pool.apply_async( get_faces, [ img ] )
read, img = camera.read()
pr4 = pool.apply_async( get_faces, [ img ] )
fcount = 1
while (True):
read, img = camera.read()
if fcount == 1:
pr1 = pool.apply_async( get_faces, [ img ] )
faces, img, gray=pr2.get()
draw_frame( faces, img, gray )
elif fcount == 2:
pr2 = pool.apply_async( get_faces, [ img ] )
faces, img, gray=pr3.get()
draw_frame( faces, img, gray )
elif fcount == 3:
pr3 = pool.apply_async( get_faces, [ img ] )
faces, img, gray=pr4.get()
draw_frame( faces, img, gray )
elif fcount == 4:
pr4 = pool.apply_async( get_faces, [ img ] )
faces, img, gray=pr1.get()
draw_frame( faces, img, gray )
fcount = 0
fcount += 1
if cv2.waitKey(1000 // 12) & 0xff == ord("q"):
break
camera.release()
cv2.destroyAllWindows()
注意:这里对于OpenCV3的版本需要修改如下内容:
cv2.createEigenFaceRecognizer()
—>cv2.face.createEigenFaceRecognizer()
cv2.rectangle()
—>img=cv2.rectangle()
然后执行python facerec.py ./data/generate ./data/datamap.csv,此时,摄像头会自动打开,在显示屏上可以看到画面,如图:
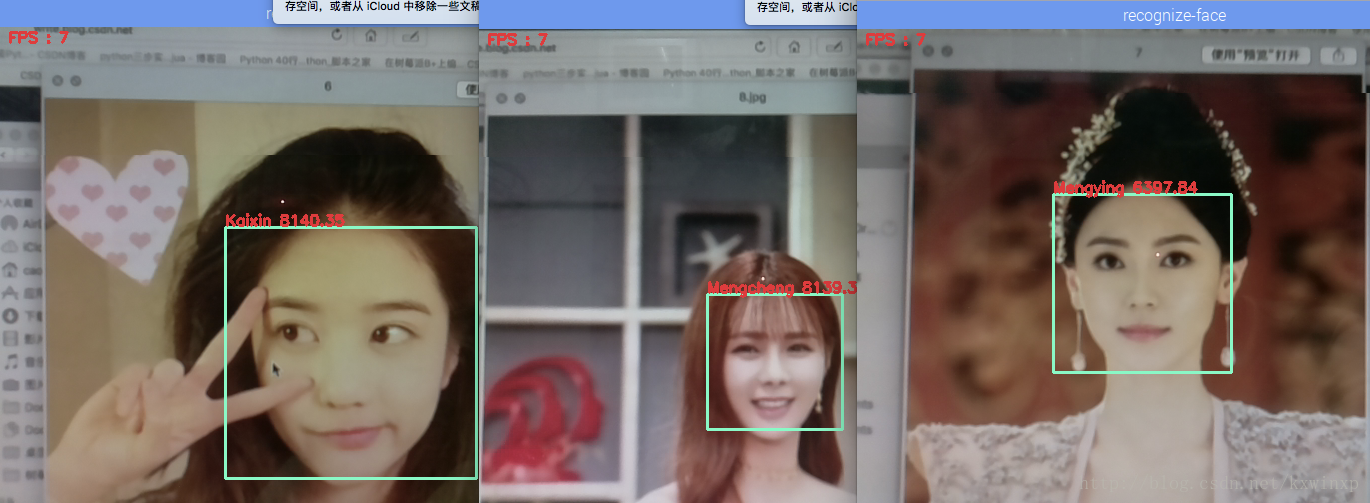
如果想测试得更理想,应选择脸型差别比较大的来测试,其次是素材高清一些,摄像头成像清晰一些。
4.扩展资料
对于OpenCV有三种人脸识别方法,它们分别基于三种不同的算法:Eigenfaces、Fisherfaces和Local Binary Pattern Histogram(LBPH)。
首先,所有的方法都有类似的过积,即都使用了分好类的训练数据集(人脸数据库,每 个人都有很多样本)来进行“训练”,对图像或视频中检测到的人脸进行分析,并从两方面来确定:是否识别到目标,目标真正被识别到的置信度的度量,这也称为置信度评分。
Eigenfaces是通过PCA来处理的。PCA是计算机视觉中提到最多的数学概。PCA的本质是识别某个训练集上(比如人脸数据库)的主成分,并计算出训练集(图像或帧中检测到的人脸)相对于数据库的发散程度,并输出一个值。该值越小,表明人脸数据库和检测到的人脸之间差别就越小;0值表示完全匹配。
Fisherfaces是从PCA衍生并发展起来的概念,它采用更复杂的逻辑。尽管计算更加密集,但比Eigenfaces更容易得到准确的效果。
LBPH粗略地(在非常高的层次上)将检测到的人脸分成小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。由于这种方法的灵活性.LBPH是唯一允许模型样本人脸和检测到的人脸在形状、大小上可以不同的人脸识别算法。个人认为这是最准确的算法,但是每个算法都有其长处和缺点。
5.扩展书籍
看较多网友对此文章有较多疑问,但我也没有较深入去研究具体原理。故无法对你们的提问作出准确的解答,在此推荐一本书给大家,相信能化解你们的疑问![本文章代码也有部分来自此书]
OpenCV 3计算机视觉 Python语言实现(第二版)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)