在无人驾驶项目中,
实现交通标志识别是一项重要工作。本文以德国交通标志数据集为训练对象,
采用深度神经网络LeNet架构处理图像,实现交通标志识别。具体处理过程包括包括:
数据导入
探索和可视化数据集
数据预处理
构建、训练和测试模型架构
采用该模型对新图片进行预测
分析新图片的softmax概率
1.数据导入
下载数据 "traffic-signs-data.zip"
读取文件" train.p" and "test.p"
import pickle
training_file = '../traffic-signs-data/train.p'
testing_file = '../traffic-signs-data/test.p'
with open(training_file, mode='rb') as f:train = pickle.load(f)
with open(testing_file, mode='rb') as f:test = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_test, y_test = test['features'], test['labels']
2.探索和可视化数据集
分析数据集中训练集数量,测试集数量,图片特征以及分类数量。
n_train = X_train.shape[0]
# TODO: Number of testing examples.
n_test = X_test.shape[0]
# TODO: What's the shape of an traffic sign image?
image_shape = X_train.shape[1:]
# TODO: How many unique classes/labels there are in the dataset.
n_classes = len(set(y_train))
print("Number of training examples =", n_train)
print("Number of testing examples =", n_test)
print()
print("Image data shape =", image_shape)
print("Number of classes =", n_classes)
结果如下所示:
Number of training examples = 34799
Number of testing examples = 12630
Image data shape = (32, 32, 3)
Number of classes = 43
随机显示数据集的一张图片:
3.数据预处理
数据预处理过程中用到的技术包括图片灰度处理、数据归一化、数据增强、数据分割等。
1.图片灰度处理
在交通标志识别过程中,颜色并非图片等主要特征,将彩色图片转换为灰度图片依然可以识别,且单通道数图片迭代更快。图片灰度处理代码如下:
X_train_rgb = X_train
X_train_gry = np.sum(X_train/3, axis=3, keepdims=True)
X_test_rgb = X_test
X_test_gry = np.sum(X_test/3, axis=3, keepdims=True)
print('RGB shape:', X_train_rgb.shape)
print('Grayscale shape:', X_train_gry.shape)
2.数据归一化
归一化输入图片,将输入特征处理到相似的范围内,使得代价函数优化起来更简单更快捷,该项目中将训练集和测试集归一化到(-1,1)范围。具体代码如下:
X_train_normalized = (X_train - 128.)/128.
X_test_normalized = (X_test - 128.)/128.
3.数据增强
在交通标志识别训练过程中,对原始数据进行训练,结果显示训练集准确率挺高但是验证集的准确率偏低,表现为过拟合。出现过拟合时训练集准确率高表明算法充分学习到了原始数据的特征;验证集准确率偏低表明原始数据的特征不够充分,使算法在新验证集中泛化性表现较差。解决方式是对原始数据在数据预处理阶段进行数据增强,增加训练集数据。具体代码如下:
from scipy import ndimage
def expend_training_data(X_train, y_train):
"""
Augment training data
"""
expanded_images = np.zeros([X_train.shape[0] * 5, X_train.shape[1], X_train.shape[2]])
expanded_labels = np.zeros([X_train.shape[0] * 5])
counter = 0
for x, y in zip(X_train, y_train):
# register original data
expanded_images[counter, :, :] = x
expanded_labels[counter] = y
counter = counter + 1
# get a value for the background
# zero is the expected value, but median() is used to estimate background's value
bg_value = np.median(x) # this is regarded as background's value
for i in range(4):
# rotate the image with random degree
angle = np.random.randint(-15, 15, 1)
new_img = ndimage.rotate(x, angle, reshape=False, cval=bg_value)
# shift the image with random distance
shift = np.random.randint(-2, 2, 2)
new_img_ = ndimage.shift(new_img, shift, cval=bg_value)
# register new training data
expanded_images[counter, :, :] = new_img_
expanded_labels[counter] = y
counter = counter + 1
return expanded_images, expanded_labels
X_train_normalized = np.reshape(X_train_normalized,(-1, 32, 32))
agument_x, agument_y = expend_training_data(X_train_normalized[:], y_train[:])
agument_x = np.reshape(agument_x, (-1, 32, 32, 1))
print(agument_y.shape)
print(agument_x.shape)
print('agument_y mean:', np.mean(agument_y))
print('agument_x mean:',np.mean(agument_x))
#print(y_train.shape)
4.数据分割
将扩增之后的数据重新分割为训练集和验证集,分割比例极代码如下:
from sklearn.model_selection import train_test_split
X_train, X_validation, y_train, y_validation = train_test_split(agument_x, agument_y,test_size=0.10,random_state=42)
4.定义LeNet函数
交通标志识别项目中,其图形特征明显,识别任务比较简单,分类输出数固定,对于该类任务采用该架构较简单的LeNet(X)就可以实现。所以项目算法架构采用LeNet(X),算法架构如下图所示:
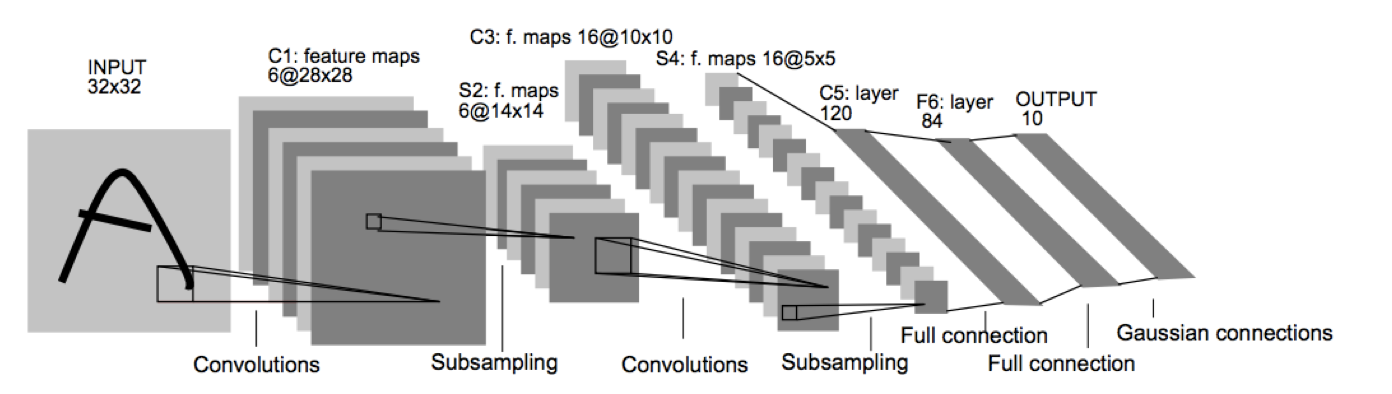
LeNet(X)是交通标志识别中非常经典的算法结构。但是要实现交通标志识别还需要对该算法的初始结构进行调整。比如输出层的分类数调整为43;Subsampling layers 转为max pooling layers;增加Dropout 层,初始设置keep_prob=0.9;激活函数采用RELU。
改进后的架构流程如下表所示:
| Layer | Description |
|---|
| Input | 32x32x1 gry image |
| Convolution 5x5 | 1x1 stride, VALID padding, outputs 28x28x6 |
| RELU | Activation |
| Max pooling | 2x2 stride, outputs 14x14x6 |
| Convolution 5x5 | 1x1 stride, VALID padding, outputs 10x10x16 |
| RELU | Activation |
| Max pooling | 2x2 stride, outputs 5x5x16 |
| Flatten | Outputs 400 |
| Fully connected | Outputs 120 |
| RELU | Activation |
| Dropout | Keep_prob=0.5 |
| Fully connected | Outputs 84 |
| RELU | Activation |
| Dropout | Keep_prob = 0.5 |
| Fully connected | Outputs = 43 |
具体代码如下:
from tensorflow.contrib.layers import flatten
def LeNet(x):
# Arguments used for tf.truncated_normal, randomly defines variables for the weights and biases for each layer
mu = 0
sigma = 0.1
# SOLUTION: Layer 1: Convolutional. Input = 32x32x1. Output = 28x28x6.
conv1_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 1, 6), mean = mu, stddev = sigma))
conv1_b = tf.Variable(tf.zeros(6))
conv1 = tf.nn.conv2d(x, conv1_W, strides=[1, 1, 1, 1], padding='VALID') + conv1_b
# SOLUTION: Activation.
conv1 = tf.nn.relu(conv1)
#conv1 = tf.nn.dropout(tf.nn.relu(conv1), keep_prob)
# SOLUTION: Pooling. Input = 28x28x6. Output = 14x14x6.
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# SOLUTION: Layer 2: Convolutional. Output = 10x10x16.
conv2_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 6, 16), mean = mu, stddev = sigma))
conv2_b = tf.Variable(tf.zeros(16))
conv2 = tf.nn.conv2d(conv1, conv2_W, strides=[1, 1, 1, 1], padding='VALID') + conv2_b
# SOLUTION: Activation.
conv2 = tf.nn.relu(conv2)
#conv2 = tf.nn.dropout(tf.nn.relu(conv2), keep_prob)
# SOLUTION: Pooling. Input = 10x10x16. Output = 5x5x16.
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# SOLUTION: Flatten. Input = 5x5x16. Output = 400.
fc0 = flatten(conv2)
# SOLUTION: Layer 3: Fully Connected. Input = 400. Output = 120.
fc1_W = tf.Variable(tf.truncated_normal(shape=(400, 120), mean = mu, stddev = sigma))
fc1_b = tf.Variable(tf.zeros(120))
fc1 = tf.matmul(fc0, fc1_W) + fc1_b
# SOLUTION: Activation.
#fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(tf.nn.relu(fc1), keep_prob)
# SOLUTION: Layer 4: Fully Connected. Input = 120. Output = 84.
fc2_W = tf.Variable(tf.truncated_normal(shape=(120, 84), mean = mu, stddev = sigma))
fc2_b = tf.Variable(tf.zeros(84))
fc2 = tf.matmul(fc1, fc2_W) + fc2_b
# SOLUTION: Activation.
#fc2 = tf.nn.relu(fc2)
fc2 = tf.nn.dropout(tf.nn.relu(fc2), keep_prob)
# SOLUTION: Layer 5: Fully Connected. Input = 84. Output = 43.
fc3_W = tf.Variable(tf.truncated_normal(shape=(84, 43), mean = mu, stddev = sigma))
fc3_b = tf.Variable(tf.zeros(43))
logits = tf.matmul(fc2, fc3_W) + fc3_b
return logits
5.训练流程及设置超参数
计算交叉熵,测量对数几率的分类结果和真实标签之间的差距。
计算训练集交叉熵平均值作为训练集的整体损失函数。训练过程使用Adam算法优化梯度下降,并最小化损失函数。超参数设置如下:
EPOCHS =10, BATCH_SIZE=128,sigma = 0.1,learning rate =0.001
具体代码如下:
logits = LeNet(x)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=one_hot_y,logits=logits)
loss_operation = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(learning_rate = rate)
training_operation = optimizer.minimize(loss_operation)
6.评估模型
在交通标志识别过程中,采用改进算法对数据增强数据进行训练,同时对算法Ddropout层调整参数,设置keep_prob=0.5,增加算法正则化效果。
算法的最终输出结果如下:
training set accuracy : 0.982
validation set accuracy : 0.976
test set accuracy : 0.945
7.测试新图片
下载8张德国交通标志图片,如图中所示:
将图片与训练集进行相同的处理,包括灰度化,归一化等。
8.分析新图片的softmax概率
对训练后的模型进行测试,输出各个图片识别softmax概率的前三位。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)