观前提示:本文涉及的代码演示部分,为了文章的观赏性,许多代码演示中有意忽略了导包、异常处理…
所谓 IO,I(input) O(output),即输入输出。
File类
文件是电脑的一种存储形式,文件有不同的格式(.txt .doc .ppt .mp4 .jpg .rar …),文件夹即目录路径
File 是一个类,在java.io包中,File 是文件或目录路径名的抽象表示形式,与真实硬盘中的文件或文件夹,不是一个东西File 在内存中的一个对象 --> 硬盘上的文件或文件夹,与电脑上的文件或文件夹(目录)产生一一对应的映射关系- 构造方法

import java.io.File;
File f = new File("文件或文件夹路径");
- file对象 不是真正的文件,是堆内存中创建出来的一个对象空间
- 参数
路径 是看创建的对象能否与硬盘中的真实文件产生映射关系
- Java中使用文件流,通过 File 建立的映射关系,去读取文件的内容
文件(目录)的属性
File可以操控一个文件或文件夹的属性
一
boolean x = f.canExecute();
boolean x = f.canRead();
boolean x = f.canWrite();
二
boolean x = f.isHidden();
boolean x = f.isFile();
boolean x = f.isDirectory();
boolean x = f.isAbsolute();
完整的描述文件位置的路径就是绝对路径,通常是从盘符开始到目标位置的路径。
三
long value = f.getFreeSpace();
long value = f.getUsableSpace();
long value = f.getTotalSpace();
long value = f.length();
long value = f.lastModified();
boolean x = f.setLastModified(long time);
补充:返回的是毫秒值,需要一定的转化,输出为年月日时分秒的形式
File f= new File("文件");
long time = f.lastModified();
Date date = new Date(time);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd kk:mm:ss");
System.out.println(sdf.format(date));
四
String value = f.getAbsolutePath();
String name = f.getName();
文件(目录)的创建
boolean x = f.createNewFile();
boolean x = f.mkdir();
- 新建文件夹(目录)
- 父文件夹必须真实存在!
- 没有异常需要进行处理,因为硬盘上实际上是没有文件夹的
boolean value = f.mkdirs();
文件(目录)的删除
boolean x = f.delete();
- 删除文件 或者 空目录
- 而且这种删除方式是彻底删掉了,回收站都没有
文件(目录)的父与子
父
String value = f.getParent(); 获取当前 f 的父亲对象的名字File file = f.getParentFile(); 获取当前 f 的父亲对象
父文件夹的遍历
File file = new File("路径");
File pfile = file.getParentFile();
while(pfile != null){
System.out.println(pfile.getAbsolutePath());
pfile = pfile.getParentFile();
}
子
String[] values = f.list(); 获取当前文件夹对像 f 的所有子对象名字File[] files = f.listFiles(); 获取当前文件夹对像 f 的所有子对象
调用上面两个方法后的结果,体现的意义:
- 如果数组为
null,则证明当前的 f 是一个文件; - 如果数组不为
null,证明当前的 f 是一个文件夹; - 如果数组的长度不为
0,证明当前的 f 是一个不为空的文件夹(目录中有元素)
文件夹的遍历删除
遍历文件夹
public void showFile(File file){
File[] files = file.listFiles();
if(files != null && files.length != 0){
for(File f:files){
this.showFile(f);
}
}
System.out.println(file.getAbsolutePath());
}
删除非空文件夹
public void deleteFile(File file){
File[] files = file.listFiles();
if(files != null && files.length != 0){
for(File f:files){
this.deleteFile(f);
}
}
file.delete();
}
字节型文件流
一般使用较多的是高级流,虽然字节型文件流和字符型文件流是低级流,但是高级流还是通过低级流操作文件的,大部分方法的使用是一致的
File对象
- 可以和本地硬盘文件有映射关系
- 可以查看文件(和目录)的属性
- 可以创建新的文件,目录
- 可以查看父元素目录
- 文件夹遍历,删除
但是File对象不可以操作文件中的内容-----这个要通过I/O流的方式来完成
文件流按照读取或写入的单位大小来区分:
- 字节型文件流(1字节)
FileInputStream / FileOutputStream - 字符型文件流(2字节—1字符)
FileReader / FileWriter
我们为什么要把信息存在文件中?
容器:
-
变量 (只能存一个)
-
数组 (存储好多个 数据类型统一)
-
集合 (存储好多个 存储后个数还能改变 泛型—数据类型统一)
-
================================================
如上三个都是Java中的类型(对象存储在内存中,而这个内存是Java虚拟机开辟的,当程序执行完毕,虚拟机停止的时候,内存空间就回收了)
如上三种存储方式,存储的信息都是临时性的
-
文件 (存储好多信息 )
文件是存储在硬盘上的----永久性保存
文件毕竟不在内存中,需要通过IO操作文件
-
数据库 JDBC
FileInputStream
java.io包,继承自InputStream类(字节型输入流的父类)- 构造方法

- 常用方法(
fis为FileInputStream对象):
int code = fis.read(); 每次从流管道中读取一个字节(返回这个字节的Unicode码)int count = fis.read(byte[] b); 每次从流管道中读取若干个字节,存入数组中,返回有效元素个数int count = fis.avaliable(); 返回流管道中还有多少缓存的字节数long v = fis.skip(long n); 跳过n-1个字节再读取第n个字节,返回参数fis.close(); 将流通道关闭—必须要做,最好放在finally中,注意代码的健壮性,判断严谨
常用方法一:read()
File file = new File("文件路径");
FileInputStream fis = new FileInputStream(file);
int i = fis.read();
while(i != -1){
System.out.print(i + " ");
System.out.println((char)code);
i = fis.read();
}
补充:
常用方法二:read(byte[] b)
FileInputStream fis = new FileInputStream("文件路径");
byte[] b = new byte[5];
int count = fis.read(b);
while(count != -1){
String value = new String(b,0,count);
System.out.print(value);
count = fis.read(b);
}
【举个例子】假设是读取下面这个文件,若是使用错误写法 String value = new String(b);

这个文件中有21个字节(第一行为7个+/r+/n 为9个;第二行为7个+/r+/n 为9个;第三行就3个)
但是实际上,我们只创建了一个数组b用来当作小推车
第一次数组b存储a b c d e
第二次数组b把原来的都覆盖了,再存储f g \r \n h
第三次数组b把原来的都覆盖了,再存储i j k l m
第四次数组b把原来的都覆盖了,再存储n \r \n o p
第五次数组b只覆盖了第一个(后四个内容不变),数组b实际上变为q \r \n o p
所以输出时,会多了一些不需要的内容,解决办法一般有两种:
- 每次读取都用新的byte数组,但是这样很浪费空间,不可取
- 正确的解决办法,就是对String进行操作,让String读到几个,就构建几个,改为:
String value = new String(b,0,count);
常用方法三:available()
int count = fis.avaliable();
这个方法和流的概念有关,流是一个管道:

这个图不太严谨(管其实连着的是File对象,而不是真实的硬盘中的文件,硬盘中的文件和File对象有映射关系;而上图将File给抽象掉了)
补充:这个方法读取本地的数据不会有什么问题,但是当去读取网络中的数据时,可能会有问题
常用方法四:skip(long n)
long v = fis.skip(long n);
- 跳过n-1个字节,读取第n个字节,返回参数
- 实际上就是移动文件指针
这个方法一般没什么用,不过在多线程中利用几个线程同时读取文件,让他们分工读取字节,skip就有用了
常用方法五: close()
流是一个管道,通信完成后,管道是必须要关闭的
关闭的是流通道,不是File对象
为了程序设计的健壮性,close()的放置位置是有讲究的:一般放在finally中
FileOutputStream
java.io包,父类OutputStream所有字节型输出流的父类- 构造方法

如果要输出的文件不存在,会在硬盘中创建此文件
File file = new File("文件路径");
FileOutputStream fos = new FileOutputStream(file);
File file = new File("文件路径");
FileOutputStream fos = new FileOutputStream(file, true);
- 常用方法:
fos.write(int code); 将给定的code对应的字符向流管道中写入fos.write(byte[] b); 将数组中的全部字节向流管道写入fos.flush(); 将流管道中的数据写到文件中,这个方法默认调用fos.close(); 关闭流管道
常用方法六:write()

向流管道中写东西,会通过File对象映射到硬盘中的文件中,最后会写到文件中
【1】虽然write(int x)中的参数要求是int型,那么直接把char类型的传到参数中行吗?
答案当然是肯定的(char可以自动类型转换为int型)
【2】要把"1+1=2"写入文件中有什么办法?
- 调用五次
write()方法
fos.write(49); fos.write('+'); fos.write(49);
fos.write('=');
fos.write(50);
- 通过构建byte数组
byte[] b = new byte[]{'1','+','1','=','2'};
fos.write(b);
- String转byte数组
String str = "1+1=2";
byte[] b = str.getBytes();
fos.write(b);
实现文件的复制
public void copyFile(File file,String path){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(file);
File newFile = new File(path + "//" + file.getName());
fos = new FileOutputStream(newFile);
byte[] b = new byte[1024];
int count = fis.read(b);
while(count != -1) {
fos.write(b, 0, count);
fos.flush();
count = fis.read(b);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fis!=null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if(fos!=null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
实现文件的加密
文件的加密其实也不难,就是在文件的复制的基础进行一定的改动即可,其余代码与上述代码相同!
while(count != -1) {
byte temp = b[0];
b[0] = b[1];
b[1] = temp;
fos.write(b,0,count);
fos.flush();
count = fis.read(b);
}
由于加密代码使用的为对称加密,只需要改一下参数再运行一遍即可解密了
实现文件夹的复制
可以复制文件,空文件夹,非空文件夹
public void superCopyFile(File file,String newPath){
String oldFilePath = file.getAbsolutePath();
int idx1 = oldFilePath.lastIndexOf('\\');
int idx2 = oldFilePath.lastIndexOf('/');
int idx = idx1 > idx2 ? idx1 :idx2;
String newFilePath = newPath + oldFilePath.substring(idx, oldFilePath.length());
File newFile = new File(newFilePath);
File[] files = file.listFiles();
if(files != null){
newFile.mkdir();
System.out.println(newFile.getName() + " 文件夹复制完毕");
if(files.length != 0){
for(File f:files){
this.superCopyFile(f,newFilePath);
}
}
}else{
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(file);
fos = new FileOutputStream(newFile);
byte[] b = new byte[1024];
int count = fis.read(b);
while(count!=-1){
fos.write(b,0,count);
fos.flush();
count = fis.read(b);
}
System.out.println(newFile.getName() + " 文件复制完毕");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fis!=null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if(fos!=null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
文件夹的剪切 = 文件夹的复制 + 文件夹的遍历删除
字符型文件流
其实字符型文件流的玩法和字节型文件流是一样的,除了读取的单位不同
FileReader
java.io包,继承自InputStreamReader- 构造方法

- 常用方法
read()、read(char[])、close()
FileWriter
java.io包,继承自OutputStreamReader- 构造方法

- 常用方法:
write(int)、write(char[])、write(String)、close()
字符编码
还有在使用字符型文件流的时候,很容易出现字符编码的问题
不同国家的数字和符号是一样的,但不同国家有不同的文字(中文、英文、法文、韩文、日文。。。)
与此相似,在计算机最早产生时,它是按照英文字母,单个字符设计的
字母 数字 符号 ----- 1字节( 8bit,范围256 )
如果计算机想要处理除了上述字母符号以外的其他字符----比如中文(2字节),就需要将中文进行字符编码-------拆分和组合
字符编码:拆分组合的规则
常见的字符编码:
- ASCII(American Standard Code for Information Intercha)
- ISO-8859-1
- 以上两个编码是单字节的,只能处理英文字母、数字和符号;而下面的编码都是可以处理中文的
- GB2312、GB18030、GBK、BIG5
- Unicode、UTF-8、UTF-16
平台(操作系统)默认字符集:
- windows的默认字符集是GBK
- Linux和macOS的默认字符集是UTF-8
集成开发环境(IDE)的默认字符集:
- IntelliJ IDEA 的默认字符集是UTF-8
- Eclipse 的默认字符集是GBK
HTML---->浏览器解析文字使用的字符集(用charset来设置,一般都是UTF-8或者GBK)
注意在用记事本存储文字,流操作纯文本形式的时候,字符的形式采用统一的编码方式(比如:UTF-8)
byte数组组合成字符串,用String的这个构造方法
new String(byte[],"UTF-8")
字符串拆分成byte数组:
String s = "陌生人,祝愿你";
byte[] b = s.getBytes("UTF-8");
缓冲流
缓冲流是通过字节型文件流或者字符型文件流构造的,方法基本一致,但是效率更棒,所以这个流用的多,而且缓冲流中的BufferedReader和BufferedWriter多了两个很有趣而且实用的方法,可以对文件一行一行的进行操作
文件流中的低级流
- FileInputStream / FileOutputStream
- FileReader / FileWriter
缓冲流:
在管道内增加缓存的数据,让我们使用流读取文字更加的流畅
缓冲流(高级流)的创建是通过低级流(上面四个)来完成的,真实进行操作的还是低级流(缓冲流构建的时候没有boolean类型的参数)
- BufferedInputStream/BufferedOutputStream
- BuffferedReader/BufferedWriter
- 这四个缓冲流使用起来和最上面的四个文件流完全一样,但是缓冲流的性能更加棒
BufferedInputStream / BufferedOutputStream
用起来和文件流完全一样
BufferedInputStream 对象的创建过程
File file = new File("文件路径");
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
方法
BufferedOutputStream 对象的创建过程
File file = new File("文件路径");
FileOutputStream fos = new FileOutputStream(file, true);
BufferedOutputStream bos = new BufferedOutputStream(fos);
方法
BuffferedReader
BufferedReader的创建过程也是通过低级流FileReader:
File file = new File("文件路径");
FileReader fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
BufferReader的方法也和Filereader基本差不多,但是多了一个很有意思的方法readLine(),可以读取一行
BufferedWriter
BufferedWriter的创建过程也是通过低级流FileWriter:
File file = new File("文件路径");
FileWriter fr = new FileWriter(file, true);
BufferedWriter br = new BufferedWriter(fr);
BufferedWriter 的方法也和FileWriter 基本差不多,但是多了一个很有意思的方法newLine(),可以写入行分隔符(姑且理解为\n)

缓冲流中,write方法之后,必须要写flush方法
自此,文件流写完了
- 字节型
FileInputStream / FileOutputStream - 字符型
FileReader / FileWriter
- 字节型
BufferedInputStream / BufferedOutputStream(最有用) - 字符型
BufferedReader / BufferedWriter(最有用)
还有数组流(不太常用)
- byte数组
ByteArrayInputStream / ByteArrayOutputStream - char数组
CharArrayReader / CharArrayWriter
还有数据流(没啥用)
DataInputStream 读取一个字节,可以通过调用不同的读取方法,返回这个字节的不同的基本类型DataOutputStream
还有字符串流(没啥用)
对象流(挺有用的)
ObjectInputStreamObjectOutputStream
一般对文件的操作,缓冲流的使用就足够了,而且可以保存对象的属性;但是如果想把一个对象的属性,甚至是方法都保存到文件中,缓冲流就爱莫能助了
对象流
ObjectInputStreamObjectOutputStream
- 为什么要有文件?
文件永久性的保存信息(将很多的数据直接存入文件------数据持久化) - 如果按照一行为单位在文件中写信息:
优点:好处在于每一行记录都是相关的
优点:信息可以读取出来 直接看懂文件
缺点:但是不安全 性能可能有问题(通常采用分布式的方式,将文件拆分成碎片)
缺点:如果要记录的对象不止有属性,还有一些方法呢,这样就没法记录了 - 读取出来的信息 String 最后还是要转化成对象
将对象直接记录在文件中 永久保存 这就是对象的持久化(对象的序列化)
- 对象的序列化
将一个完整的对象,拆分成字节碎片,记录在文件中 - 对象的反序列化
将文件中的记录的对象碎片,反过来组合成一个完整的对象
对象的序列化
- 如果想要将对象序列化到文件中
- 需要让对象实现
Serializable接口 - 是一个示意性接口
Person p = new Person();
FileOutputStream fos = new FileOutputStream("文件路径");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(p);
oos.flush();
对象的反序列化
- 为了让对象可以反序列化
- jdk8版本,对象必须存在一个属性
private long serialVersionUID = 任意L;,才可以进行反序列化 - 关于jdk版本变迁的这方面变化,我也不太清楚。反正我确定jdk11之后,不写这个属性也可以反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("对象序列化时写入的文件路径"));
Person p = (Person)ois.readObject();
System.out.println(p);
p.eat();
- 对象流可以将一个对象碎片化后记录在文件中,
- 还可以存放多个对象到同一个文件中(会出现EOFException,说明没有对象)
- 不过,通常我们不会这么干,而是将所有记录的对象存在一个集合里,然后再序列化
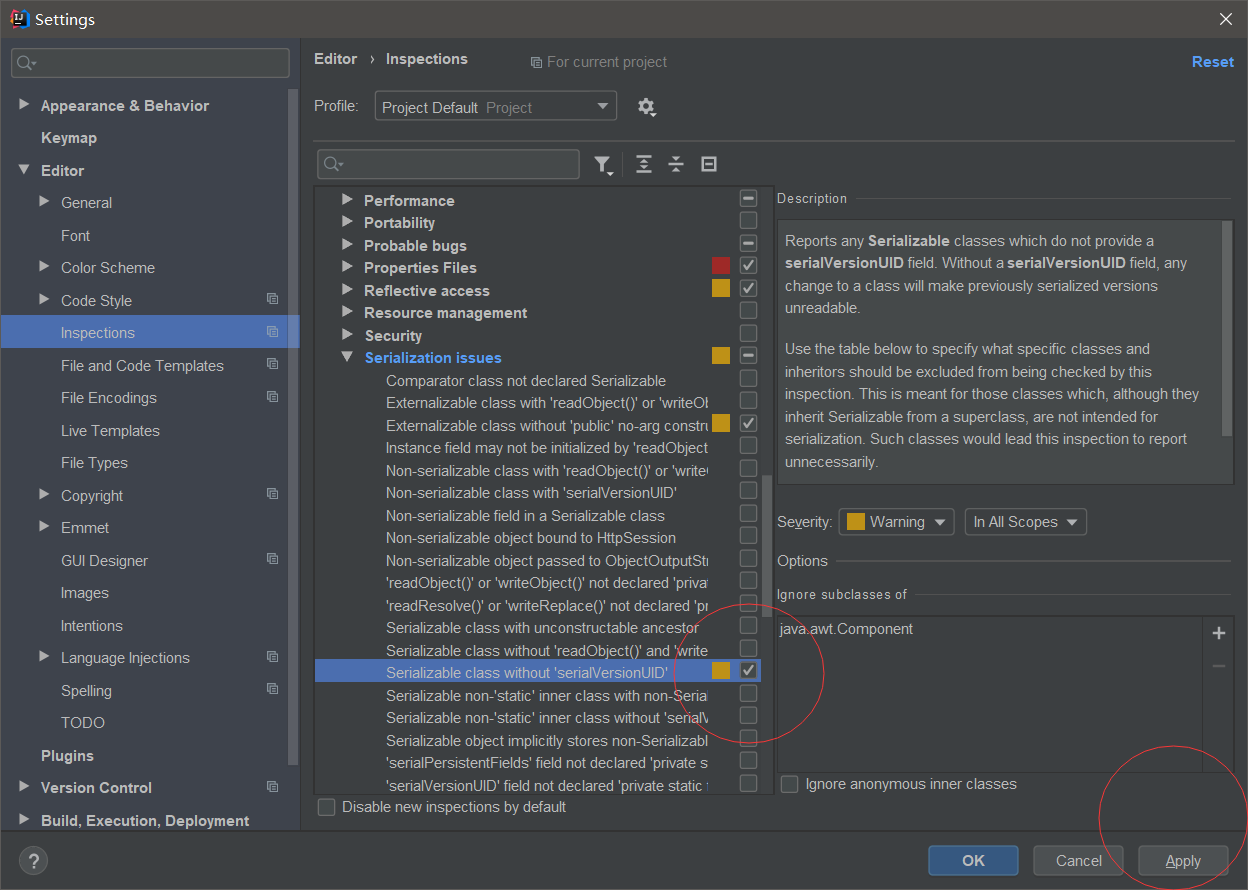
在Idea中,可以设置自动添加序列化版本ID:idea -> File -> Settings -> Editor -> Inspections -> Java -> Serialization issues
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)