本文是对另一个博主的
睿智的目标检测30——Pytorch搭建YoloV4目标检测平台代码的学习,由于我是cv新手,很多东西不懂,看了论文和代码后还有很多不太了解的地方,所以想把整个YOLOv4代码都做一下笔记,希望能够真正掌握YOLOv4。
大部分内容都是引用这个博主的文章和YOLOv4原论文的。下面就不一一解释了。
YOLOV4简介
由于本文主要目的是看懂代码,而不是对模型的理论学习。所以不做过多的原理分析。详细的可以查看原论文或中文的分析。
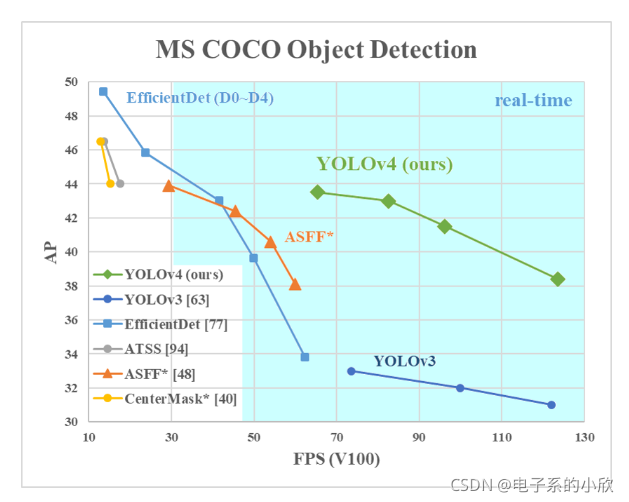
YOLOv4实际上和YOLOv3很像,是在YOLOv3做了很多修改后形成的模型。但是性能得到了很大的提升。看上图就知道了。
YOLOv3:
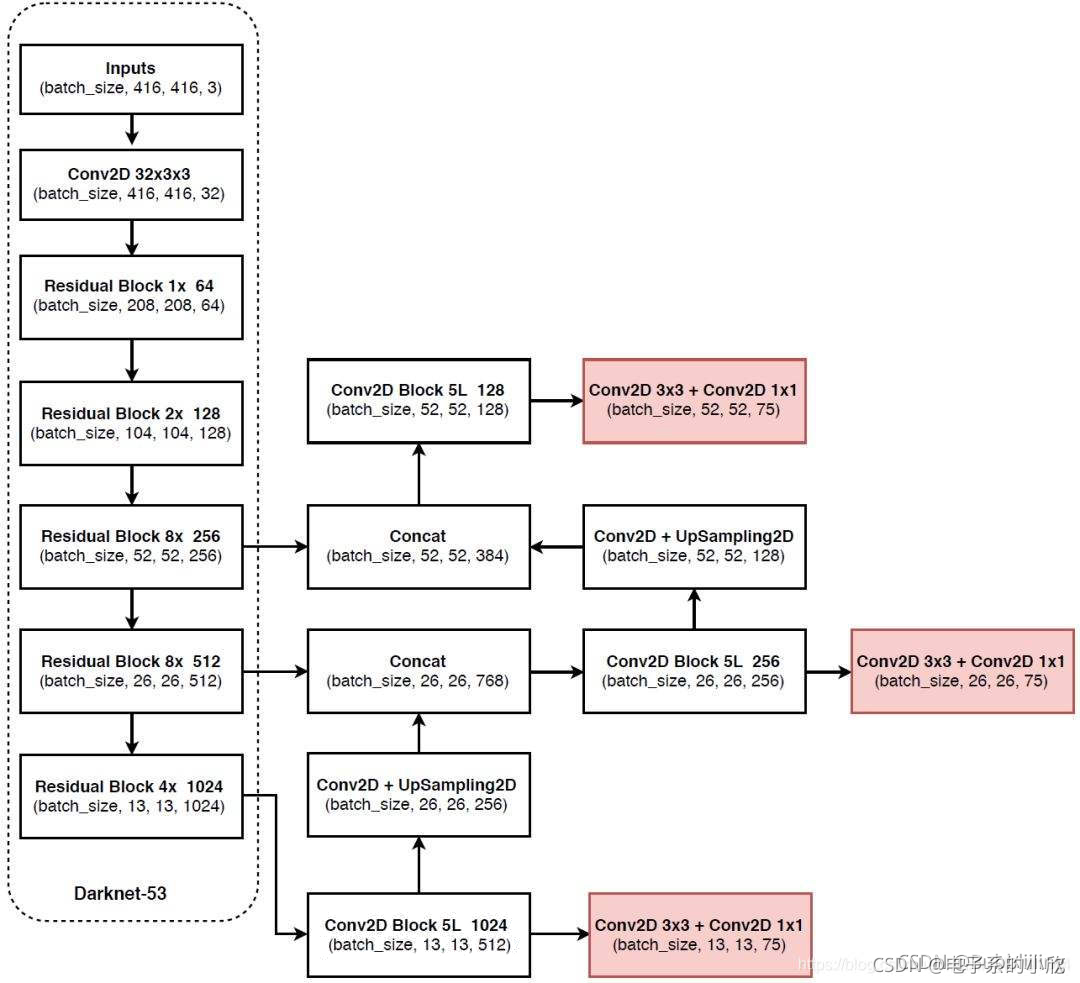
YOLOv4: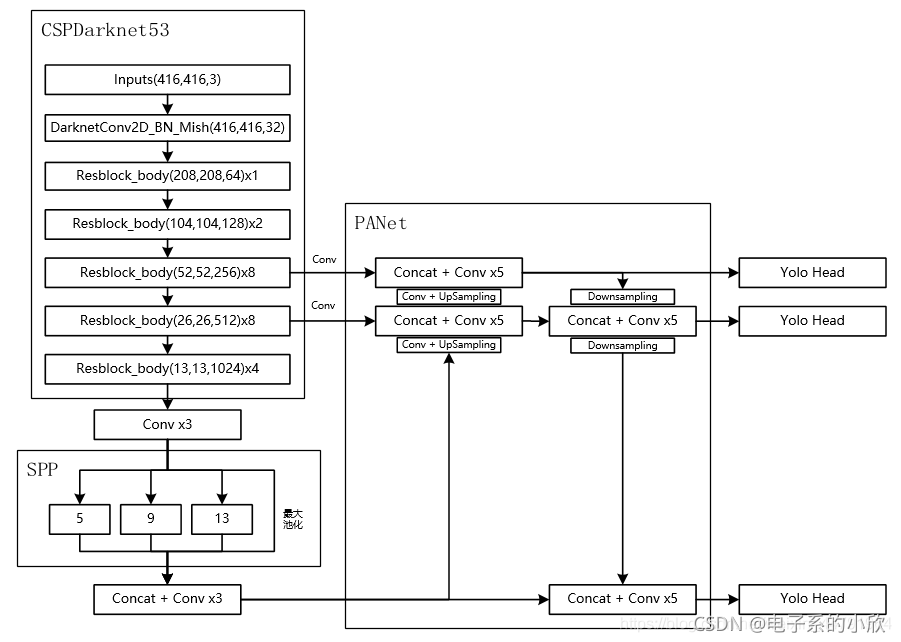
上面的两张图分别是YOLOv3网络结构图和YOLOv4网络结构图。对比可知道,主要的变化是:
-
骨干网络从Darknet53变成了CSPDarknet53
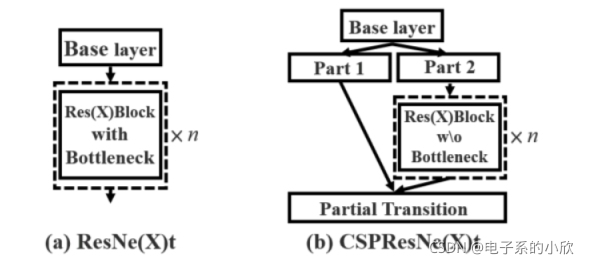
CSPNet如下图,将输入分成两块,一块做简单处理,另一块通过了很多残差快,最后进行堆叠处理。
-
使用Mish激活函数(YOLOv3使用的是Relu)
不多解释,Mish如下图。
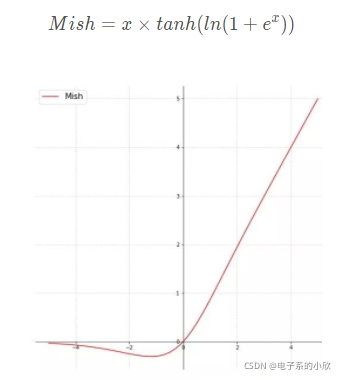
-
使用了SPPNet
SPP结构参杂在对CSPdarknet53的最后一个特征层的卷积里,在对SPdarknet53的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)。
-
使用了PANet
从PANet与FPN的区别在于下图的(b),有效特征层的提取不仅仅是骨干网络的最后几层及相应上采样的跳接,还将跳接后的特征层再做下采样,然后再把相同size的堆叠起来。(简单理解就是,本来是上采样然后堆叠,现在变成了上采样堆叠,然后再做一轮下采样,然后再堆叠。)
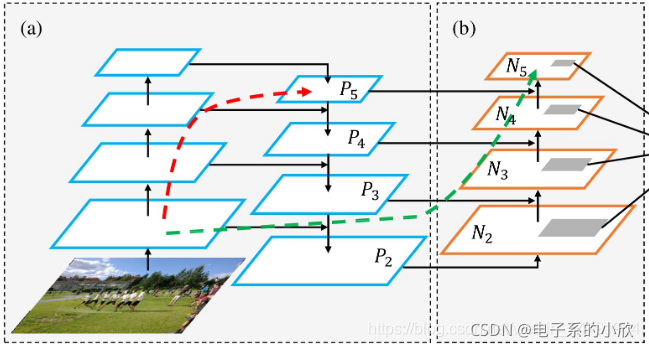
CSPdarknet.py学习
这是原代码链接:https://github.com/bubbliiiing/yolov4-pytorch/blob/45ec8d1b655e27f10865fd277c111e2c1e0338bb/nets/CSPdarknet.py#L63
这个文件实现的是主干网络CSPdarknet53,总共定义了5个类和1个函数,下图是调用关系。
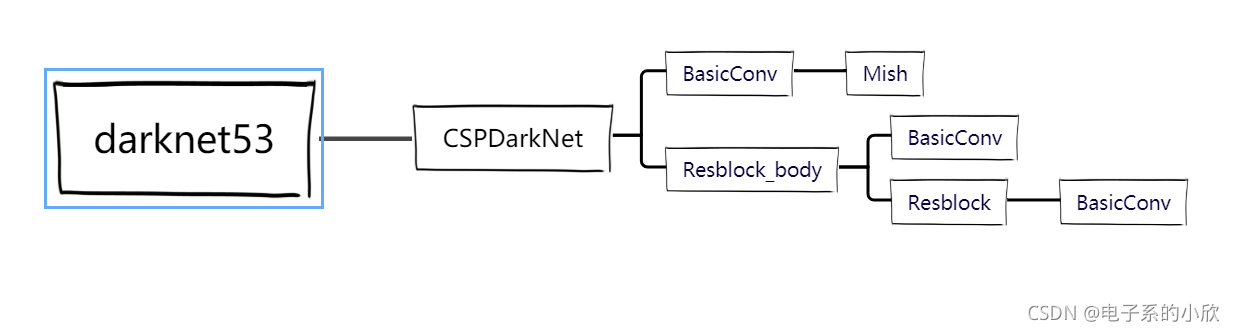
- Mish:实现Mish激活函数。(这个没什么难理解的,不做过多分析)
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))
- BasicConv:依次做了一次卷积,激活函数为Mish,通过设置padding使输出的h和w和输入一样。
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size//2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = Mish()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activation(x)
return x
- Resblock:这个是CSPdarknet53中的残差块基本单元。调用两次BasicConv做卷积,它的特点就是输出的通道数和输入一样。
class Resblock(nn.Module):
def __init__(self, channels, hidden_channels=None):
super(Resblock, self).__init__()
if hidden_channels is None:
hidden_channels = channels
self.block = nn.Sequential(
BasicConv(channels, hidden_channels, 1),
BasicConv(hidden_channels, channels, 3)
)
def forward(self, x):
return x + self.block(x)
- Resblock_body:这个就是CSPdarknet53中的残差块了。
先看它的四个输入参数in_channels, out_channels, num_blocks, first。前面两个是输入输出通道数。看第三个num_blocks,这个指的是什么?
看下图,这个CSPdarknet53的每个残差块是由多个残差单元Resblock组成的,具体多少个图片上已经标出来了。分别是1、2、8、8、4。
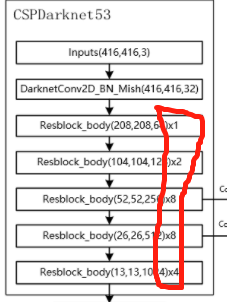
第四个参数first是因为第一个残差模块需要做一些不一样的操作,所以传入这个变量。不同在哪?
其实是中间层的通道数的不同,第一个残差模块的CSPNet两个部分堆叠后,通道数是2倍out_channels,在做1x1卷积时,需要修改参数,使得通道数减半。但是后面的四个残差块的CSPNet两个部分堆叠后,通道数等于out_channels,1x1卷积通道数不变。
之所以会有这个差异,是split_conv0和split_conv1的输出通道数在first中等于out_channels。不知为什么要这样处理,猜想是原码本身是这样的,所以博主也跟着这样。
这个类的具体操作:
1 先做一次卷积使宽w高h为原来的一半(这个可以看上图,每一个块的宽高都是上一个块的一半)。
2 然后是split_conv0和split_conv1,分别对应CSPNet中的part1和part2。实际就是调用BasicConv做一次卷积。
3 接着是blocks_conv,对应CSPNet中part2之后的残差结构。将split_conv1作为输入,然后根据num_blocks调用resblock。
4 最后是把split_conv0和blocks_conv堆叠起来再做一次卷积。
class Resblock_body(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, first):
super(Resblock_body, self).__init__()
self.downsample_conv = BasicConv(in_channels, out_channels, 3, stride=2)
if first:
self.split_conv0 = BasicConv(out_channels, out_channels, 1)
self.split_conv1 = BasicConv(out_channels, out_channels, 1)
self.blocks_conv = nn.Sequential(
Resblock(channels=out_channels, hidden_channels=out_channels//2),
BasicConv(out_channels, out_channels, 1)
)
self.concat_conv = BasicConv(out_channels*2, out_channels, 1)
else:
self.split_conv0 = BasicConv(out_channels, out_channels//2, 1)
self.split_conv1 = BasicConv(out_channels, out_channels//2, 1)
self.blocks_conv = nn.Sequential(
*[Resblock(out_channels//2) for _ in range(num_blocks)],
BasicConv(out_channels//2, out_channels//2, 1)
)
self.concat_conv = BasicConv(out_channels, out_channels, 1)
def forward(self, x):
x = self.downsample_conv(x)
x0 = self.split_conv0(x)
x1 = self.split_conv1(x)
x1 = self.blocks_conv(x1)
x = torch.cat([x1, x0], dim=1)
x = self.concat_conv(x)
return x
- CSPDarkNet:这个是CSPdarknet53主体。搭建出CSPdarknet53。没有什么不好理解的地方,不解释了。
class CSPDarkNet(nn.Module):
def __init__(self, layers):
super(CSPDarkNet, self).__init__()
self.inplanes = 32
self.conv1 = BasicConv(3, self.inplanes, kernel_size=3, stride=1)
self.feature_channels = [64, 128, 256, 512, 1024]
self.stages = nn.ModuleList([
Resblock_body(self.inplanes, self.feature_channels[0], layers[0], first=True),
Resblock_body(self.feature_channels[0], self.feature_channels[1], layers[1], first=False),
Resblock_body(self.feature_channels[1], self.feature_channels[2], layers[2], first=False),
Resblock_body(self.feature_channels[2], self.feature_channels[3], layers[3], first=False),
Resblock_body(self.feature_channels[3], self.feature_channels[4], layers[4], first=False)
])
self.num_features = 1
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.conv1(x)
x = self.stages[0](x)
x = self.stages[1](x)
out3 = self.stages[2](x)
out4 = self.stages[3](out3)
out5 = self.stages[4](out4)
return out3, out4, out5
- darknet53:这个可以看做是CSPDarkNet的封装函数吧,if语句是用来载入参数权重的。
def darknet53(pretrained, **kwargs):
model = CSPDarkNet([1, 2, 8, 8, 4])
if pretrained:
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request a pretrained path. got [{}]".format(pretrained))
return model
参考文献:
- 睿智的目标检测30——Pytorch搭建YoloV4目标检测平台
- TensorFlow2深度学习实战(十四):目标检测算法 YOLOv4 解析
- YOLOv4: Optimal Speed and Accuracy of Object Detection
- Batch Normalization原理与实战
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)