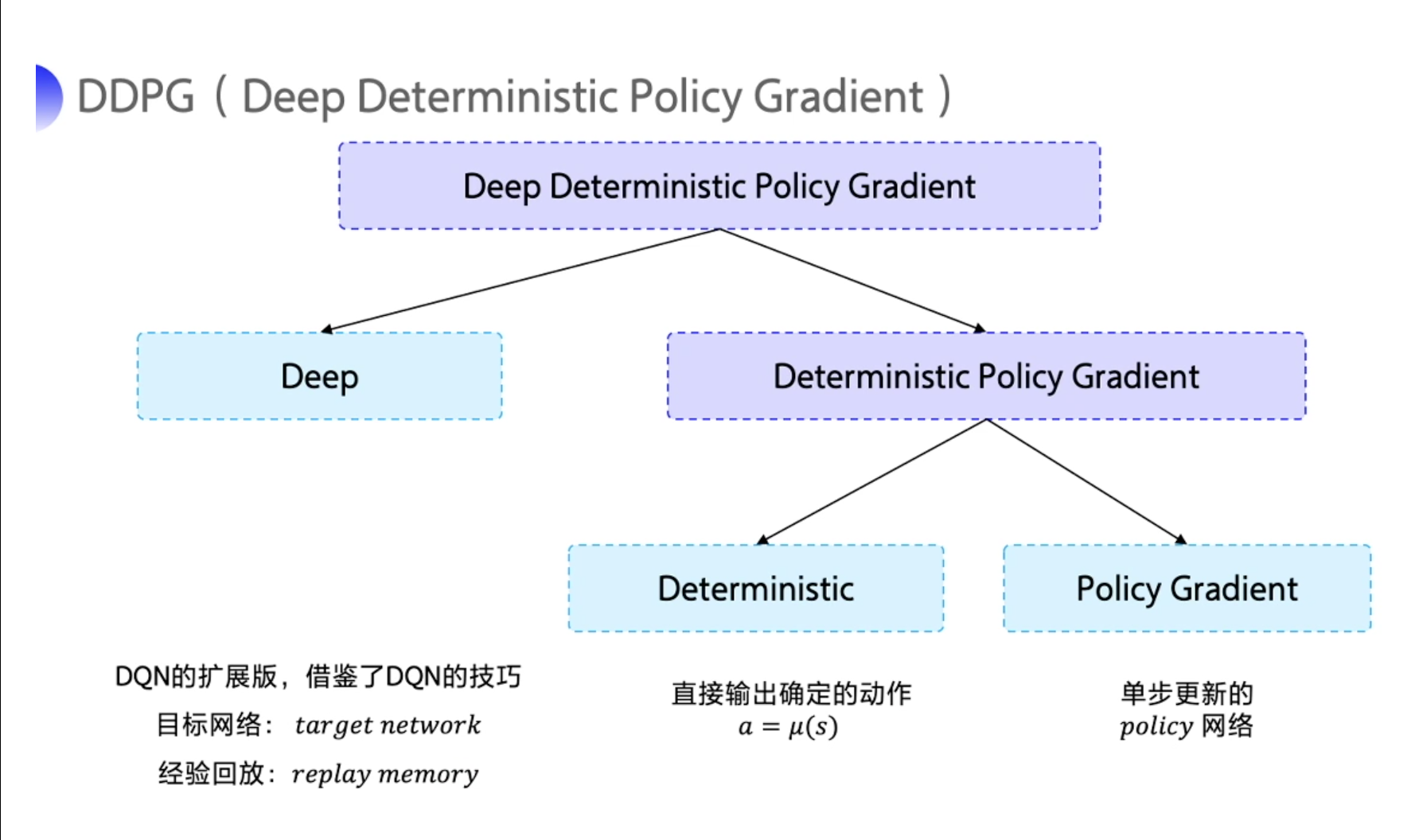
在深度确定性策略梯度算法中, Actor 是一个确定性策略函数, 表示为
π
(
s
)
\pi(s)
π(s), 待学习参数表 示为
θ
π
\theta^{\pi}
θπ 。每个动作直接由
A
t
=
π
(
S
t
∣
θ
t
π
)
A_{t}=\pi\left(S_{t} \mid \theta_{t}^{\pi}\right)
At=π(St∣θtπ) 计算, 不需要从随机策略中采样。
策略网络的 loss function 是一个复合函数。我们把
a
=
μ
θ
(
s
)
a = \mu_\theta(s)
a=μθ(s) 代进去,最终策略网络要优化的是策略网络的参数
θ
\theta
θ 。Q 网络要优化的是
Q
w
(
s
,
a
)
Q_w(s,a)
Qw(s,a) 和 Q_target 之间的一个均方差。
但是 Q 网络的优化存在一个和 DQN 一模一样的问题就是它后面的 Q_target 是不稳定的。此外,后面的
Q
w
ˉ
(
s
′
,
a
′
)
Q_{\bar{w}}\left(s^{\prime}, a^{\prime}\right)
Qwˉ(s′,a′)也是不稳定的,因为
Q
w
ˉ
(
s
′
,
a
′
)
Q_{\bar{w}}\left(s^{\prime}, a^{\prime}\right)
Qwˉ(s′,a′) 也是一个预估的值。
target_Q 网络就为了来计算 Q_target 里面的
Q
w
ˉ
(
s
′
,
a
′
)
Q_{\bar{w}}\left(s^{\prime}, a^{\prime}\right)
Qwˉ(s′,a′)。
Q
w
ˉ
(
s
′
,
a
′
)
Q_{\bar{w}}\left(s^{\prime}, a^{\prime}\right)
Qwˉ(s′,a′) 里面的需要的 next action
a
′
a'
a′ 就是通过 target_P 网络来去输出,即
a
′
=
μ
θ
ˉ
(
s
′
)
a^{\prime}=\mu_{\bar{\theta}}\left(s^{\prime}\right)
a′=μθˉ(s′)。
为了区分前面的 Q 网络和策略网络以及后面的 target_Q 网络和 target_P 策略网络,前面的网络的参数是
w
w
w,后面的网络的参数是
w
ˉ
\bar{w}
wˉ。
这里, 一个关键问题是如何平衡这种确定性策略的探索和利用 (Exploration and Exploitation)。 深度确定性策略梯度算法通过在训练过程中添加随机噪声解决该问题。每个输出动作添加噪声
N
N
N, 此时有动作为
A
t
=
π
(
S
t
∣
θ
t
π
)
+
N
t
A_{t}=\pi\left(S_{t} \mid \theta_{t}^{\pi}\right)+N_{t}
At=π(St∣θtπ)+Nt 。其中
N
N
N 可以根据具体任务进行选择, 原论文中使用 Ornstein-Uhlenbeck 过程(O-U 过程)添加噪声项。
动作价值函数
Q
(
s
,
a
∣
θ
Q
)
Q\left(s, a \mid \theta^{Q}\right)
Q(s,a∣θQ) 和深度
Q
\mathrm{Q}
Q 网络算法一样, 通过贝尔 曼方程(Bellman Equations)进行更新。
在状态
S
t
S_{t}
St 下, 通过策略
π
\pi
π 执行动作
A
t
=
π
(
S
t
∣
θ
t
π
)
A_{t}=\pi\left(S_{t} \mid \theta_{t}^{\pi}\right)
At=π(St∣θtπ), 得到下一个状态
S
t
+
1
S_{t+1}
St+1 和奖励值
R
t
R_{t}
Rt 。我 们有 :
Q
π
(
S
t
,
A
t
)
=
E
[
r
(
S
t
,
A
t
)
+
γ
Q
π
(
S
t
+
1
,
π
(
S
t
+
1
)
)
]
Q^{\pi}\left(S_{t}, A_{t}\right)=\mathbb{E}\left[r\left(S_{t}, A_{t}\right)+\gamma Q^{\pi}\left(S_{t+1}, \pi\left(S_{t+1}\right)\right)\right]
Qπ(St,At)=E[r(St,At)+γQπ(St+1,π(St+1))] 然后计算
Q
Q
Q 值:
Y
i
=
R
i
+
γ
Q
π
(
S
t
+
1
,
π
(
S
t
+
1
)
)
Y_{i}=R_{i}+\gamma Q^{\pi}\left(S_{t+1}, \pi\left(S_{t+1}\right)\right)
Yi=Ri+γQπ(St+1,π(St+1)) 使用梯度下降算法最小化损失函数:
L
=
1
N
∑
i
(
Y
i
−
Q
(
S
i
,
A
i
∣
θ
Q
)
)
2
.
L=\frac{1}{N} \sum_{i}\left(Y_{i}-Q\left(S_{i}, A_{i} \mid \theta^{Q}\right)\right)^{2} .
L=N1i∑(Yi−Q(Si,Ai∣θQ))2.
通过将链式法则应用于期望回报函数
J
J
J 来更新策略函数
π
\pi
π 。这里,
J
=
E
R
i
,
S
i
∼
E
,
A
i
∼
π
[
R
t
]
J=\mathbb{E}_{R_{i}, S_{i} \sim E, A_{i} \sim \pi}\left[R_{t}\right]
J=ERi,Si∼E,Ai∼π[Rt] (
E
E
E 表示环境),
R
t
=
∑
i
=
t
T
γ
(
i
−
t
)
r
(
S
i
,
A
i
)
R_{t}=\sum_{i=t}^{\mathrm{T}} \gamma^{(i-t)} r\left(S_{i}, A_{i}\right)
Rt=∑i=tTγ(i−t)r(Si,Ai) 。我们有:
∇
θ
π
J
≈
E
S
t
∼
ρ
β
[
∇
θ
π
Q
(
s
,
a
∣
θ
Q
)
∣
s
=
S
t
,
a
=
π
(
S
t
∣
θ
π
)
]
,
=
E
S
t
∼
ρ
β
[
∇
a
Q
(
s
,
a
∣
θ
Q
)
∣
s
=
S
t
,
a
=
π
(
S
t
)
∇
θ
π
π
(
s
∣
θ
π
)
∣
s
=
S
t
]
.
\begin{aligned} \nabla_{\theta^{\pi}} J & \approx \mathbb{E}_{S_{t} \sim \rho^{\beta}}\left[\left.\nabla_{\theta^{\pi}} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=S_{t}, a=\pi\left(S_{t} \mid \theta^{\pi}\right)}\right], \\ &=\mathbb{E}_{S_{t} \sim \rho^{\beta}}\left[\left.\left.\nabla_{a} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=S_{t}, a=\pi\left(S_{t}\right)} \nabla_{\theta_{\pi}} \pi\left(s \mid \theta^{\pi}\right)\right|_{s=S_{t}}\right] . \end{aligned}
∇θπJ≈ESt∼ρβ[∇θπQ(s,a∣θQ)∣∣s=St,a=π(St∣θπ)],=ESt∼ρβ[∇aQ(s,a∣θQ)∣∣s=St,a=π(St)∇θππ(s∣θπ)∣∣s=St]. 通过批量样本(Batches)的方式更新:
∇
θ
π
J
≈
1
N
∑
i
∇
a
Q
(
s
,
a
∣
θ
Q
)
∣
s
=
S
i
,
a
=
π
(
S
i
)
∇
θ
π
π
(
s
∣
θ
π
)
∣
S
i
\left.\left.\nabla_{\theta^{\pi}} J \approx \frac{1}{N} \sum_{i} \nabla_{a} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=S_{i}, a=\pi\left(S_{i}\right)} \nabla_{\theta^{\pi}} \pi\left(s \mid \theta^{\pi}\right)\right|_{S_{i}}
∇θπJ≈N1i∑∇aQ(s,a∣θQ)∣∣s=Si,a=π(Si)∇θππ(s∣θπ)∣∣Si 此外, 深度确定性策略梯度算法采用了类似深度
Q
\mathrm{Q}
Q 网络算法的目标网络, 但这里通过指数平滑方法而不是直接替换参数来更新目标网络:
θ
Q
′
←
ρ
θ
Q
+
(
1
−
ρ
)
θ
Q
′
θ
π
′
←
ρ
θ
π
+
(
1
−
ρ
)
θ
π
′
\begin{aligned} \theta^{Q^{\prime}} & \leftarrow \rho \theta^{Q}+(1-\rho) \theta^{Q^{\prime}} \\ \theta^{\pi^{\prime}} & \leftarrow \rho \theta^{\pi}+(1-\rho) \theta^{\pi^{\prime}} \end{aligned}
θQ′θπ′←ρθQ+(1−ρ)θQ′←ρθπ+(1−ρ)θπ′ 由于参数
ρ
≪
1
\rho \ll 1
ρ≪1, 目标网络的更新缓慢且平稳, 这种方式提高了学习的稳定性。
y
(
r
,
s
′
,
d
)
=
r
+
γ
(
1
−
d
)
min
i
=
1
,
2
Q
ϕ
i
,
t
a
r
g
(
s
′
,
a
T
D
3
(
s
′
)
)
y\left(r, s^{\prime}, d\right)=r+\gamma(1-d) \min _{i=1,2} Q_{\phi_{i, t a r g}}\left(s^{\prime}, a_{T D 3}\left(s^{\prime}\right)\right)
y(r,s′,d)=r+γ(1−d)i=1,2minQϕi,targ(s′,aTD3(s′))
目标策略平滑化的工作原理如下:
a
T
D
3
(
s
′
)
=
clip
(
μ
θ
,
t
a
r
g
(
s
′
)
+
clip
(
ϵ
,
−
c
,
c
)
,
a
low
,
a
high
)
a_{T D 3}\left(s^{\prime}\right)=\operatorname{clip}\left(\mu_{\theta, t a r g}\left(s^{\prime}\right)+\operatorname{clip}(\epsilon,-c, c), a_{\text {low }}, a_{\text {high }}\right)
aTD3(s′)=clip(μθ,targ(s′)+clip(ϵ,−c,c),alow ,ahigh ) 其中
ϵ
\epsilon
ϵ 本质上是一个噪声,是从正态分布中取样得到的,即
ϵ
∼
N
(
0
,
σ
)
\epsilon \sim N(0,\sigma)
ϵ∼N(0,σ)。 目标策略平滑化是一种正则化方法。
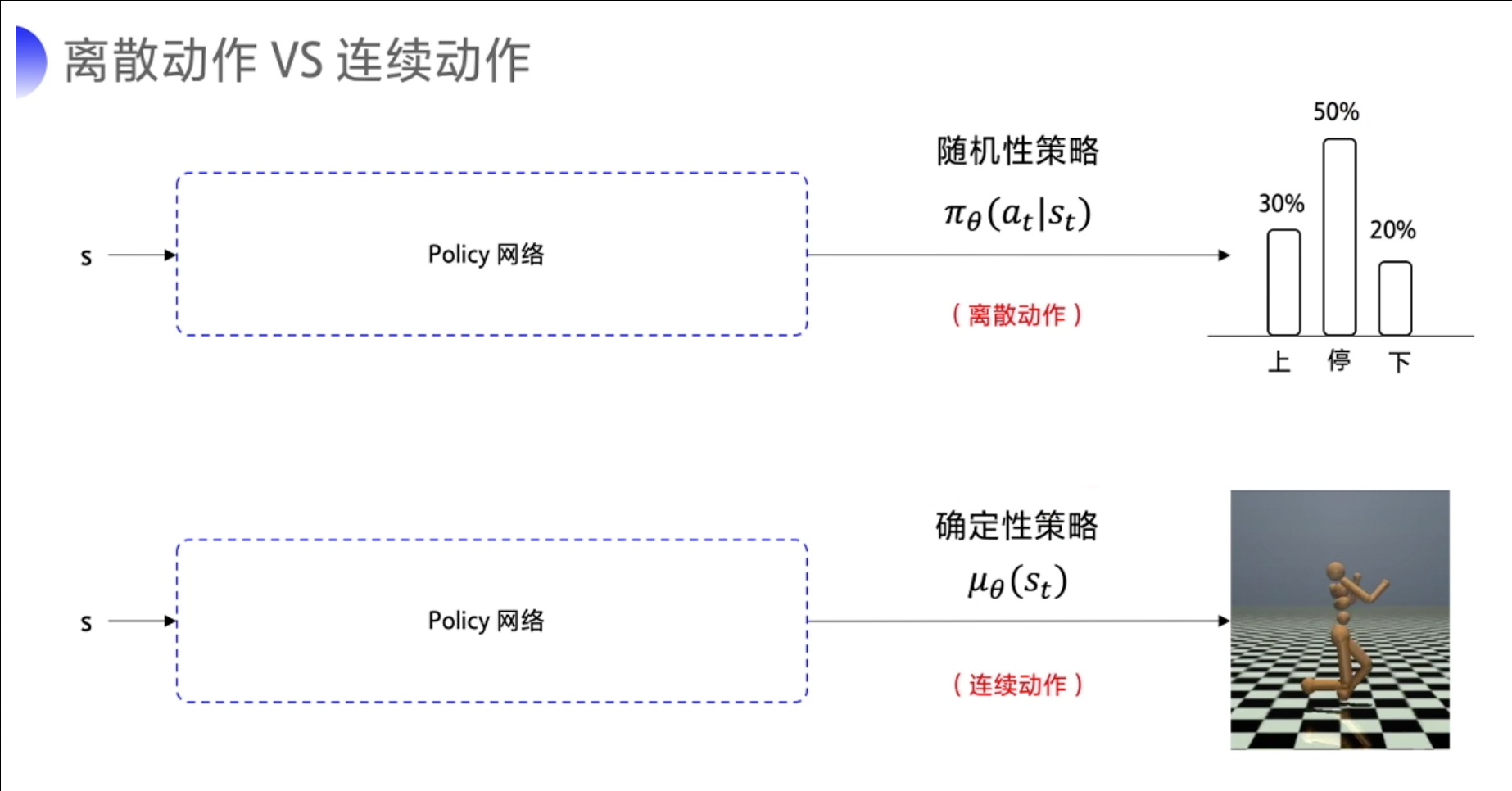
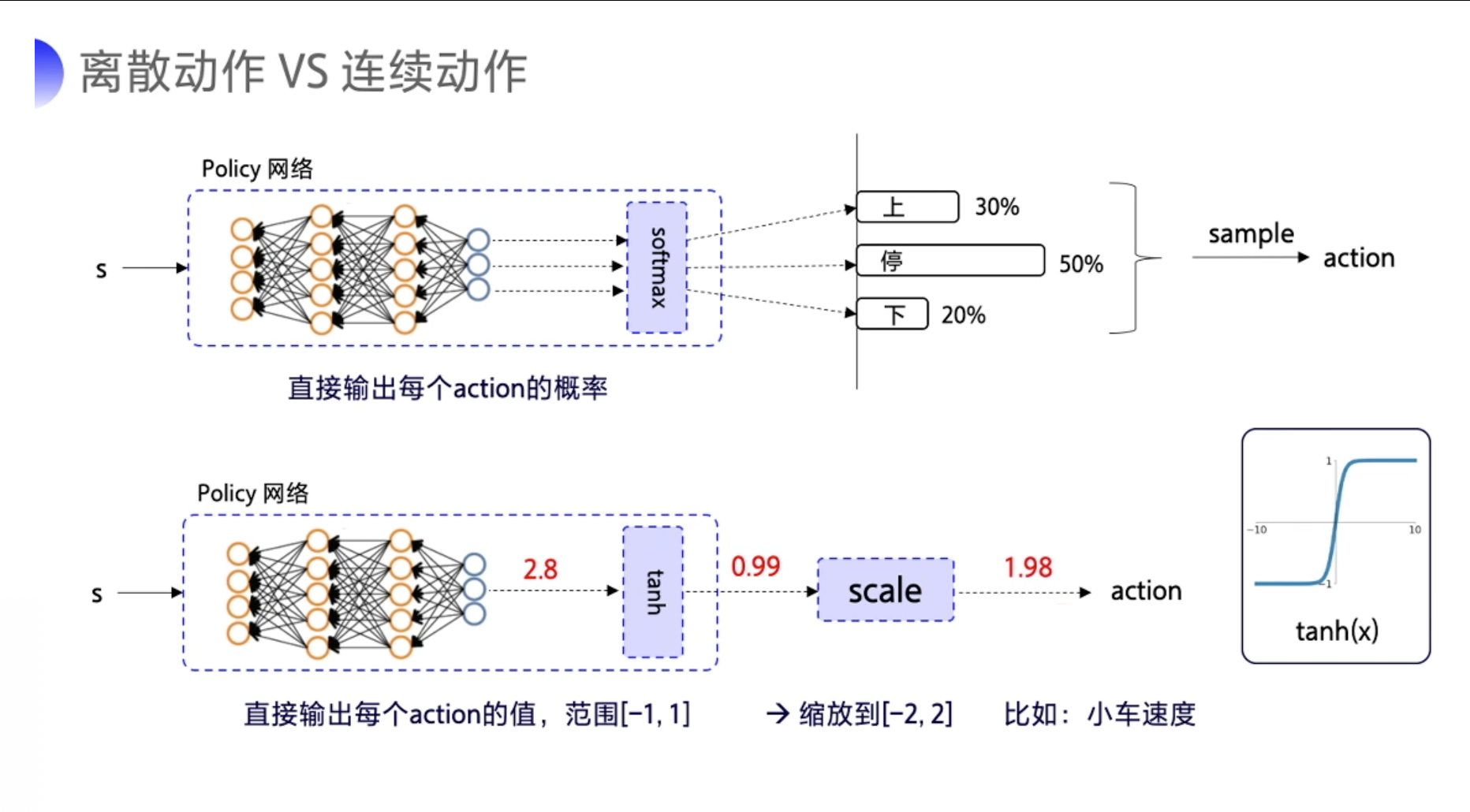
答:首先需要说明的是,对于连续的动作控制空间,Q-learning、DQN等算法是没有办法处理的,所以我们需要使用神经网络进行处理,因为其可以既输出概率值
π
θ
(
a
t
∣
s
t
)
\pi_\theta(a_t|s_t)
πθ(at∣st) ,也可以输出确定的策略
μ
θ
(
s
t
)
\mu_{\theta}(s_t)
μθ(st) 。 要输出离散动作的话,最后的output的激活函数使用 softmax 就可以实现。其可以保证输出是的动作概率,而且所有的动作概率加和为 1。 要输出连续的动作的话,可以在输出层这里加一层 tanh激活函数。其作用可以把输出限制到 [-1,1] 之间。我们拿到这个输出后,就可以根据实际动作的一个范围再做一下缩放,然后再输出给环境。