????????????????????????????????
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到
AI 前沿项目工具及新技术
的推送
发送
资料
可领取
深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景
、
中间件系列笔记
和
编程高频电子书
!
文章导读地址:
点击查看文章导读!
????????????????????????????????
Redis 生产环境最佳实践

为什么要写这篇文章呢?
因为我发现大多数朋友,在学习完 Redis 之后,发现还是对如何在项目中进行使用不太清楚,只了解简单的将数据按照 k-v 的方式放在缓存中,对于生产环境中许多场景的解决方案都不了解,下边将从各个场景来讲解 Redis 在生产环境中如何使用,这里主要讲解思路以及流程,具体的代码就不列出来了,只要知道思路,无论是通过已有代码还是网络资源都还是很好实现的!而且在面试中,面试官也更看重你解决问题的思路。因此,本文将详细介绍 Redis 在生产环境中的最佳实践,帮助大家更好地理解并应用它们!
Redis 生产环境解决方案
读多写少数据缓存方案
首先,对于用户数据,到底需不需要缓存呢?
这里举个例子,就比如在某红书中,对于热门用户,他的信息肯定是会被很多人看到的,像用户的数据特点就是:
读多写少
,读操作很多的数据是非常适合放到缓存中去的,那么如何缓存呢?
-
缓存的时间设置:可以设置为 2 个小时 + 随机几小时(添加随机几小时的原因是避免大量缓存同时过期,导致请求全部打到数据库中)
-
缓存的 key 设置:根据
member_user:[userId]
作为 key 即可,value 存储需要查询的用户信息的 json 串
-
数据放入缓存的时机:在获取用户信息的时候,先去缓存中取,如果没有,再去数据库中查,查出来之后放入到缓存
这里是对
缓存 + 数据库
进行双写
但是在多线程并发的情况下,可能会造成
缓存数据库双写不一致
的情况,如下:
-
当读线程去缓存中读取数据,此时缓存中数据正好过期,那么该线程就去读数据库中的数据
-
此时写线程开始执行,修改用户信息,并且写入数据库,再写入缓存
-
此时读线程再接着执行,将之前在数据库中读取的旧数据写入缓存,覆盖了写线程更新后的数据
那么如何解决
缓存数据库双写不一致
呢?
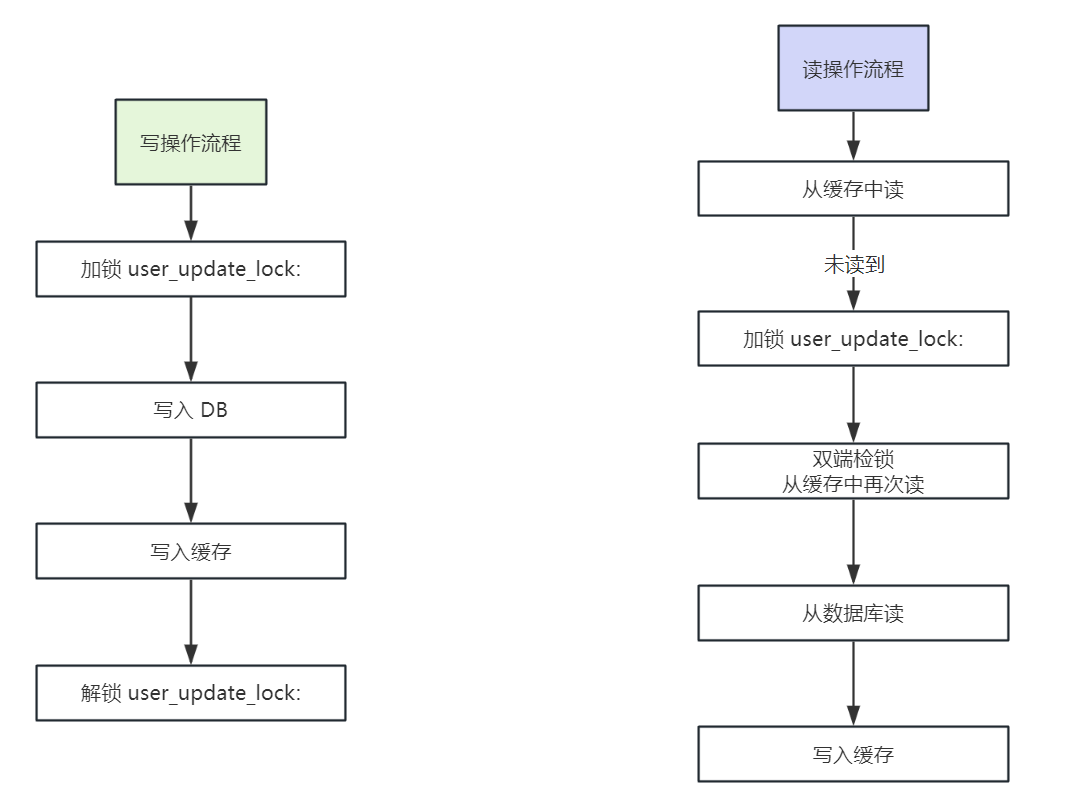
加锁,将读操作和写操作执行之前,加上同一把锁,让读写操作串行化即可:
user_info_lock
整体的流程如下:
高并发场景下优化
在高并发场景中,我们如果使用上边的这种方案会出现
大量线程阻塞
的问题,具体如下:
-
如果某一个用户突然火了,这时会有大量用户来请求这个用户的数据
-
如果恰巧这个用户的数据不在缓存中,那么会有大量的读操作线程阻塞在加锁
user_update_lock
这个步骤中等待拿锁
那么此时多线程大量的并发操作就成为了
串行拿锁
了,大大影响系统的性能,怎么解决呢?
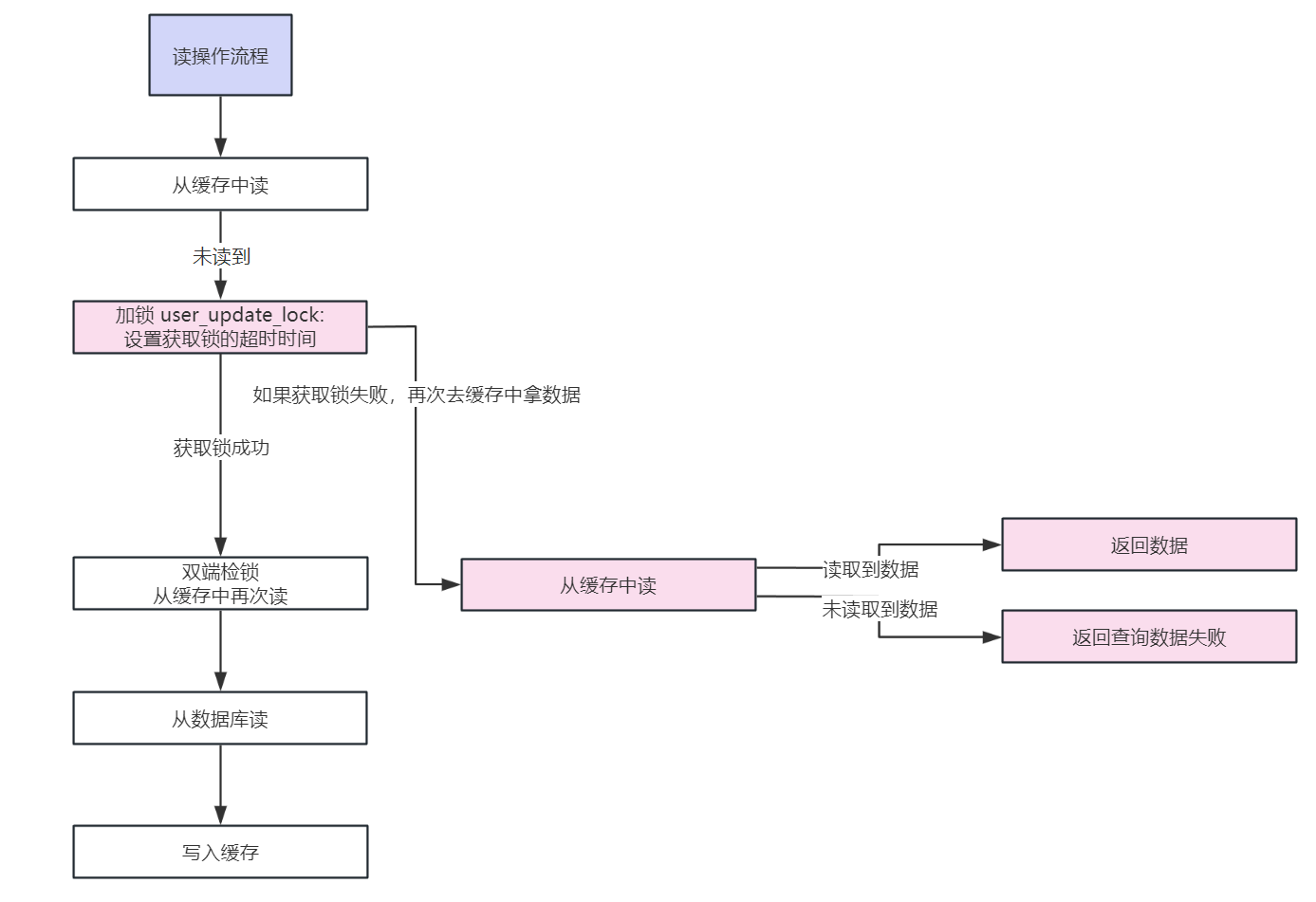
将
等待加锁的操作添加一个超时时间
即可,可以设置个 200ms,这样大量的线程如果在 200ms 都拿不到锁,就直接获取锁失败,不会再串行阻塞获取锁,
串行转并行
,如下图(粉色部分为优化):
分页数据缓存构建方案
在现在系统中,大部分数据都是通过
分页
进行查询的,那么针对于分页的数据,肯定就需要构建分页缓存,这里就需要考虑两个点:
-
分页缓存的构建时机?
-
分页缓存 key 和 value 如何设计?
先假设一种业务场景,这样下边说的时候也比较清楚一些,还是以某红书为例,要访问一个用户主页的作品,要对用户主页的作品进行分页缓存的构建
先来说一下缓存构建的时机,有两个:
-
当其他用户来查询用户 A 的主页时,先查数据库,查到之后,再进行
缓存的构建操作
-
当用户 A 新增分享的时候,用户 A 主页的数据发生变化,此时进行
缓存的重建操作
但是会出现
缓存数据库不一致
的情况,如下:
-
另一个用户 B 此时正好来查询用户 A 的分享列表,用户 B 线程先去缓存中查询,发现没有,再去数据库中查询用户 A 的分享列表,此时 B 拿到了 A 新增分享之前的旧数据
-
此时如果用户 A 新增分享并落库,并且去缓存中对用户 A 的列表缓存进行重建,那么此时缓存列表中是用户 A 的最新数据
-
但是此时用户 B 的线程在数据库中已经查到了用户 A 的旧数据,用户 B 的线程继续执行,将用户 A 的旧数据给放入到列表缓存中,覆盖掉了用户 A 更新的缓存,那么此时就会导致
缓存数据库不一致
如何解决呢?当然是
加锁
,在两个构建缓存的地方加锁,保证串行化即可,如下图
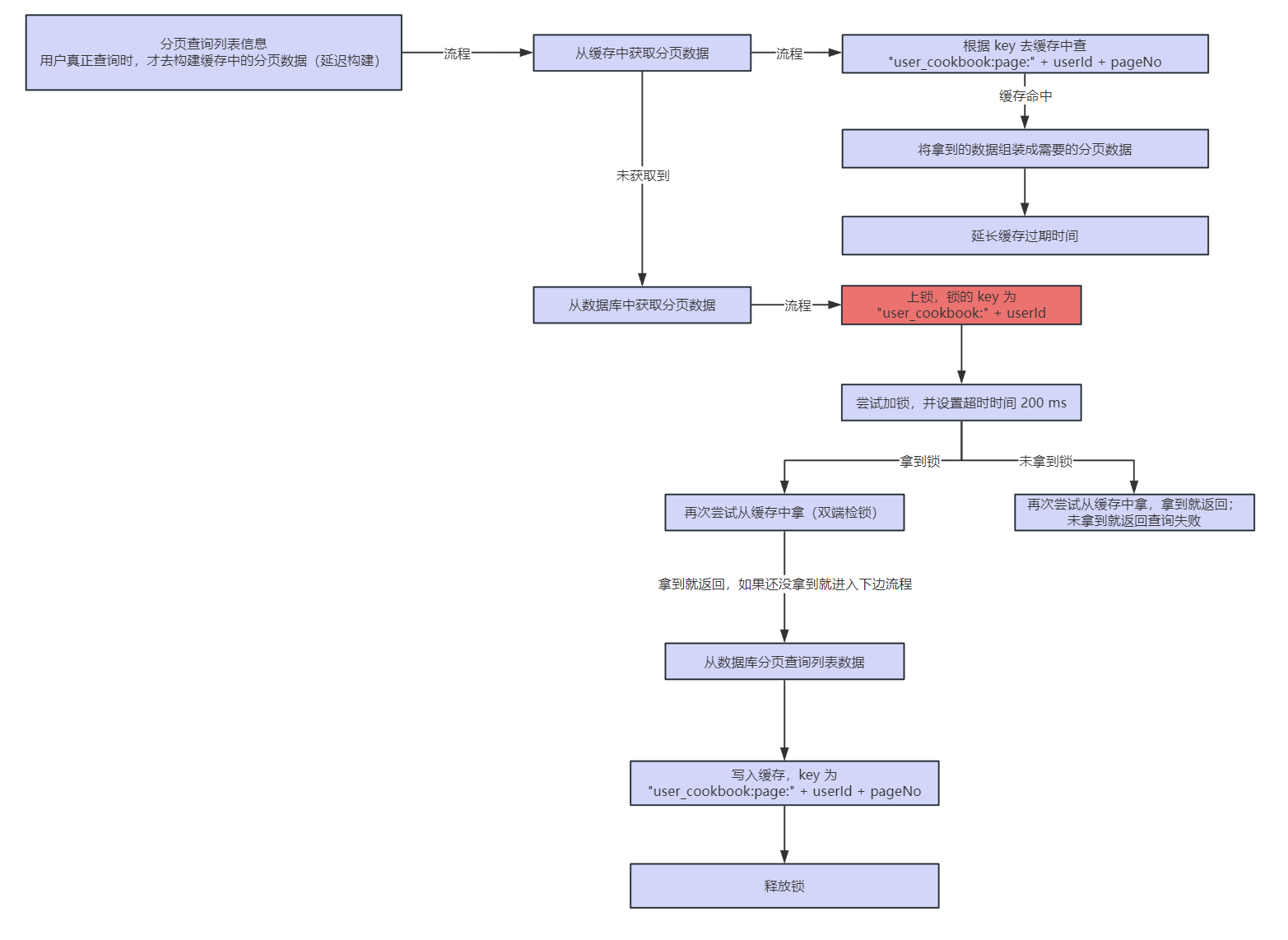
查询用户列表时,分页缓存的构建流程:
用户新增或修改内容时,对分页缓存重建流程:
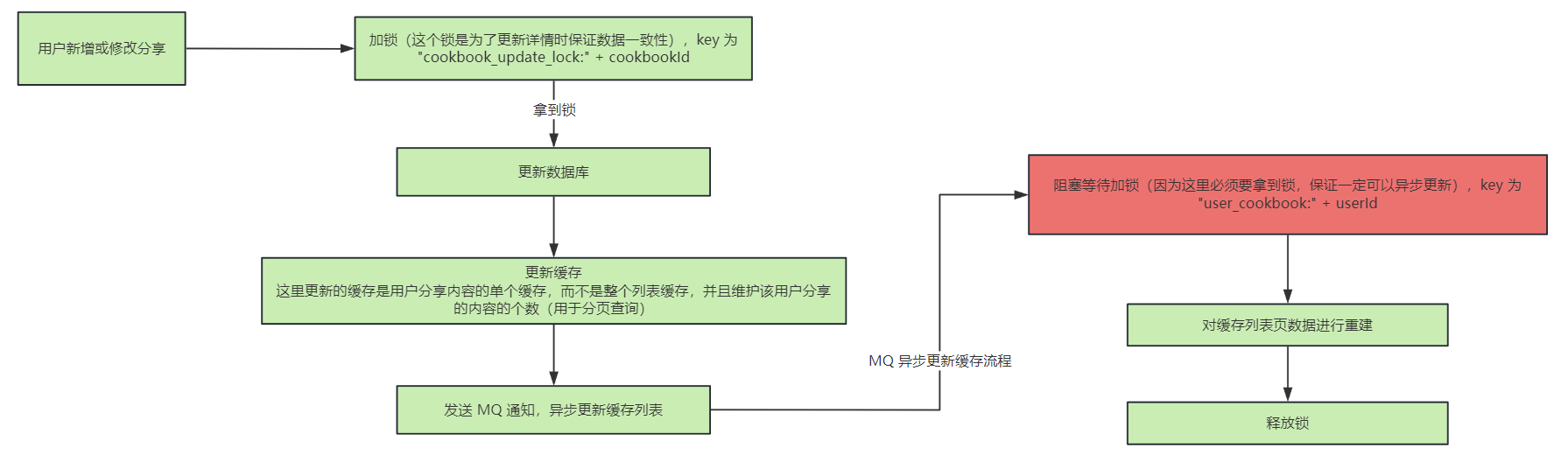
那么同样,在获取锁的时候需要加阻塞等待获取锁的
超时时间
,大量用户线程阻塞在获取锁的地方,有了获取锁的超时时间
接下来说一下分页缓存中 key 和 value 如何设计:
首先,分页数据是由 pageNo 和 pageSize 控制的,可以将 pageSize 大小给固定,这样直接根据 pageNo 就可以查询出某一页的分页数据了,key 设计为:
user_homedata:page:{userId}:{pageNo}
在数据库中查询出来分页数据之后,将分页数据转为 JSON 串之后,传入 Redis 缓存中即可
缓存穿透解决方案
如果大量恶意请求查询数据库中不存在的数据,那么缓存中肯定是没有的,就会导致大量请求打到数据库中,造成缓存穿透
解决方案就是在查询到数据库中不存在的数据之后,在 Redis 中也缓存起来,缓存为一个字符串:
"{}"
即可,这样重复查询不存在的数据就不会打到数据库中了
空缓存的
过期时间
可以设置的短一些,避免大量的空缓存占用缓存空间
写多读少、写多读多数据缓存方案
什么时候出现
写多读少
或者
写多读多
的场景呢?
就比如说电商场景中的
购物车
功能,面临着
高并发读
和
高并发写
解决方案:在购物车中,就以
Redis 作为主存储,通过 MQ 异步将数据落库持久化
,来提升系统性能!
那么在购物车中,需要缓存哪些数据呢?
-
用户购物车已有商品的数量:使用 hash 结构存储,可以在用户添加商品到购物车中时,判断购物车中的商品是否达到购物车的上限
-
商品的详情信息:使用 hash 结构存储
-
购物车中商品的顺序:使用 zset 存储,存储商品的 id,根据商品加入到购物车的时间进行排序
那么在缓存中查询购物车中的商品时,会先在 Redis 中查询购物车中商品的顺序,根据顺序查出一系列商品 id,再根据商品 id 查询到商品的详情信息
下边看一下这 3 个数据在 Redis 中的存储结构:
用户购物车已有商品的数量:
# 使用 hash 结构存储,有 3 个部分,key、field、value
key shopping_cart_hash:{userId}
field skuId # 商品id
value 商品详情 json 串
# 整体的存储结构为:
shopping_cart_extra_hash:{userId} {
{skuId}: "商品详情json串",
{skuId}: "商品详情json串"
}
购物车中商品的详情信息:
# 使用 hash 存储
key -> shopping_cart_extra_hash:{userId}
field -> skuId
value -> 商品详情
# 存储结构为:
shopping_cart_extra_hash:{userId} {
{skuId}: "商品详情json串",
{skuId}: "商品详情json串"
}
购物车中商品的顺序:
# 存储结构为 zset,通过 score 排序
key shopping_cart_zset:{userId}
value skuId
score System.currentTimeMillis() # 分数使用当前系统的时间戳即可,按照加入购物车的时间对商品进行排序
这几个缓存数据可视化存储结构我也给画了出来,见下图:

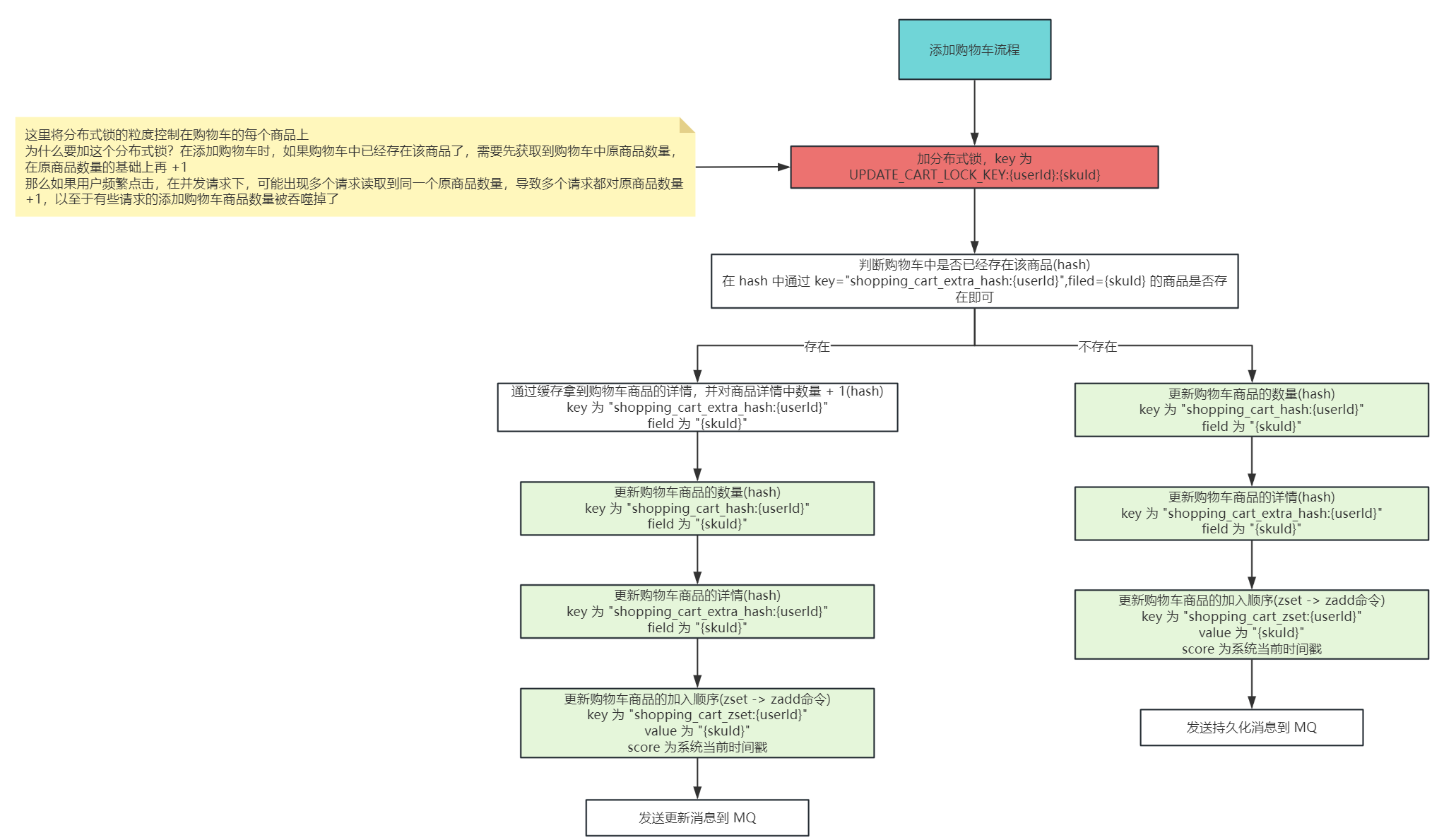
分布式锁控制
这里在添加购物车的时候,注意添加分布式锁控制并发安全,避免同一个用户点了多次,但是没有加锁,导致丢失了几次该商品的添加
这里分布式锁的 key 设计为:
UPDATE_CART_LOCK_KEY:{userId}:{skuId}
,通过 userId 和 skuId 来控制同一把锁,将
锁的粒度控制在商品级别
,尽可能加大并发度
添加购物车商品时,在 Redis 中更新完毕,就通过 MQ 发送异步消息,将数据进行
落库操作
,整体流程如下图:
高并发读写性能优化方案
先说一下业务场景,在库存模块中,需要进行
入库
和
出库
操作,并且在高峰期的时候,会有大量用户对库存进行高并发的读和写操作
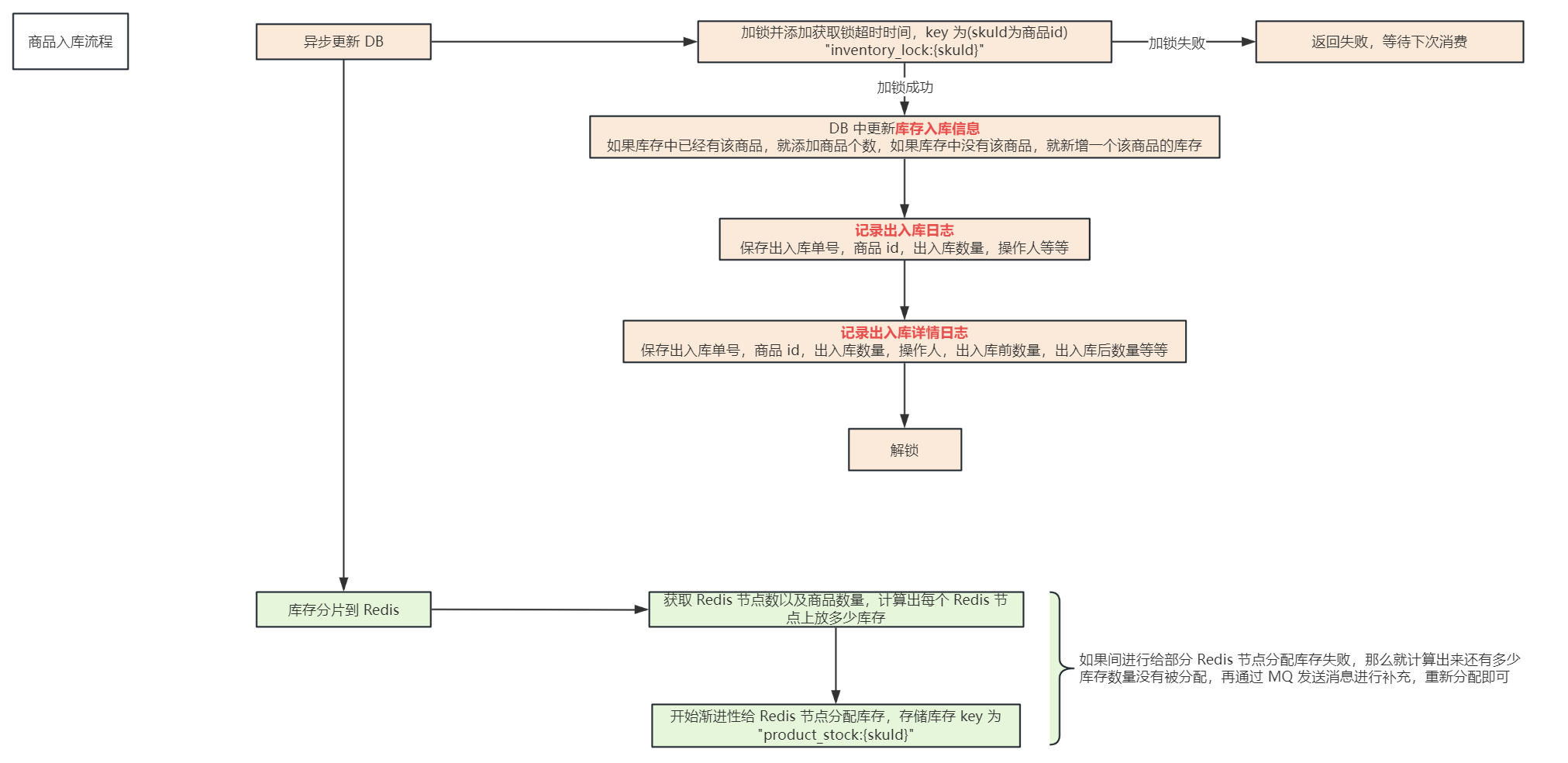
性能优化解决方案:库存
分片存储
,并且
渐进性写入
下边来说一下,如何进行具体的分片存储:
比如说某一个商品有 100 件库存,Redis 集群有 5 个节点,先将 100 个商品拆分为 5个分片(每个分片存储 20 个商品),再将 5 个分片分散到 Redis 集群的各个节点中,每个节点 1 个分片,那么也就是每个 Redis 节点存储 20 个商品库存
分片存储后,对于这个商品的
高并发
操作,就会被分散地打到多个 Redis 节点中,在分片存储的时候,一般将分片数量和 Redis 节点数设置的一样
在分片写入库存的时候,采用
渐进性写入
,比如说新入库一个商品有 300 个,有 3 个 Redis 节点,那么我们分成 3 个分片的话,1 个 Redis 节点放 1 个分片,1 个分片存储 100 个商品,那么如果我们直接写入缓存,先写入第一个 Redis 节点 100 个库存,再写入第二个 Redis 节点 100 个库存,如果这时写入第三个 Redis 节点 100 个库存的时候失败了,那么就导致操作库存的请求压力全部在前两个 Redis 节点中,采用
渐进性写入
的话,流程为:我们已经直到每个 Redis 节点放 100 个库存了,那么我们定义一个轮次的变量,为 10,表示我们去将库存写入缓存中需要写入 10 轮,那么每轮就写入 10 个库存即可,这样写入 10 轮之后,每个 Redis 节点中也就有 100 个库存了,这样的好处在于,即使有部分库存写入失败的话,对于请求的压力也不会全部在其他节点上,因为写入失败的库存很小,很快时间就可以消耗完毕
基于
分片
的添加库存流程如下:
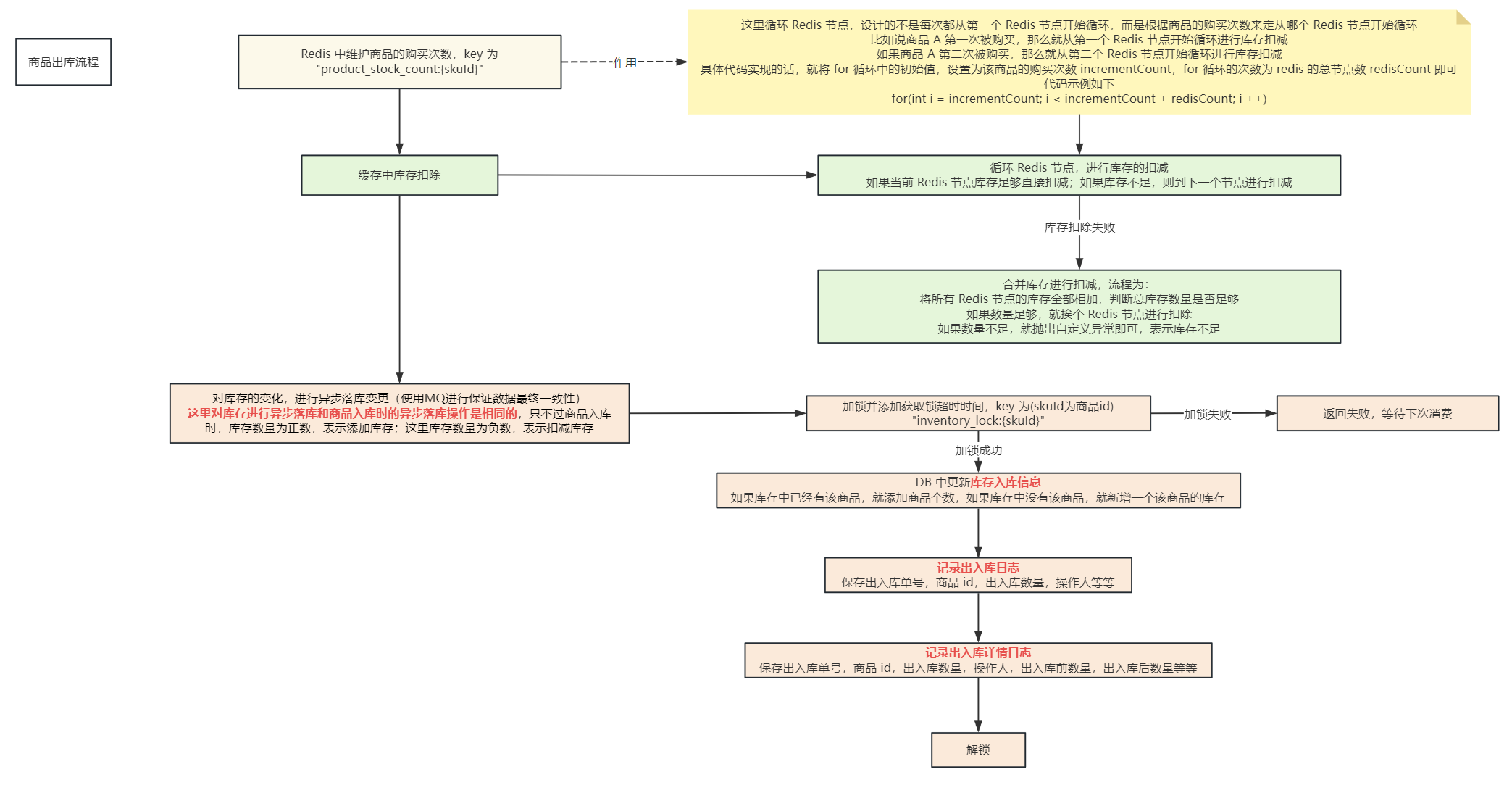
那么既然添加库存时使用
分片存储
了,在扣减库存的时候,也必须轮询 Redis 节点进行扣减库存,如果当前 Redis 节点上的库存不够扣除,那么就去遍历下一个 Redis 节点查看库存是否足够,如果遍历完所有 Redis 节点都不够,那么就统计所有 Redis 节点上的库存总和是否足够,如果足够,则一个一个进行扣除,这时候还存在
扣除异常回滚
的情况,如果某一个 Redis 节点上扣除失败了,需要进行回滚,再将之前扣除的 Redis 节点上的库存给加回来,扣除库存的流程如下:
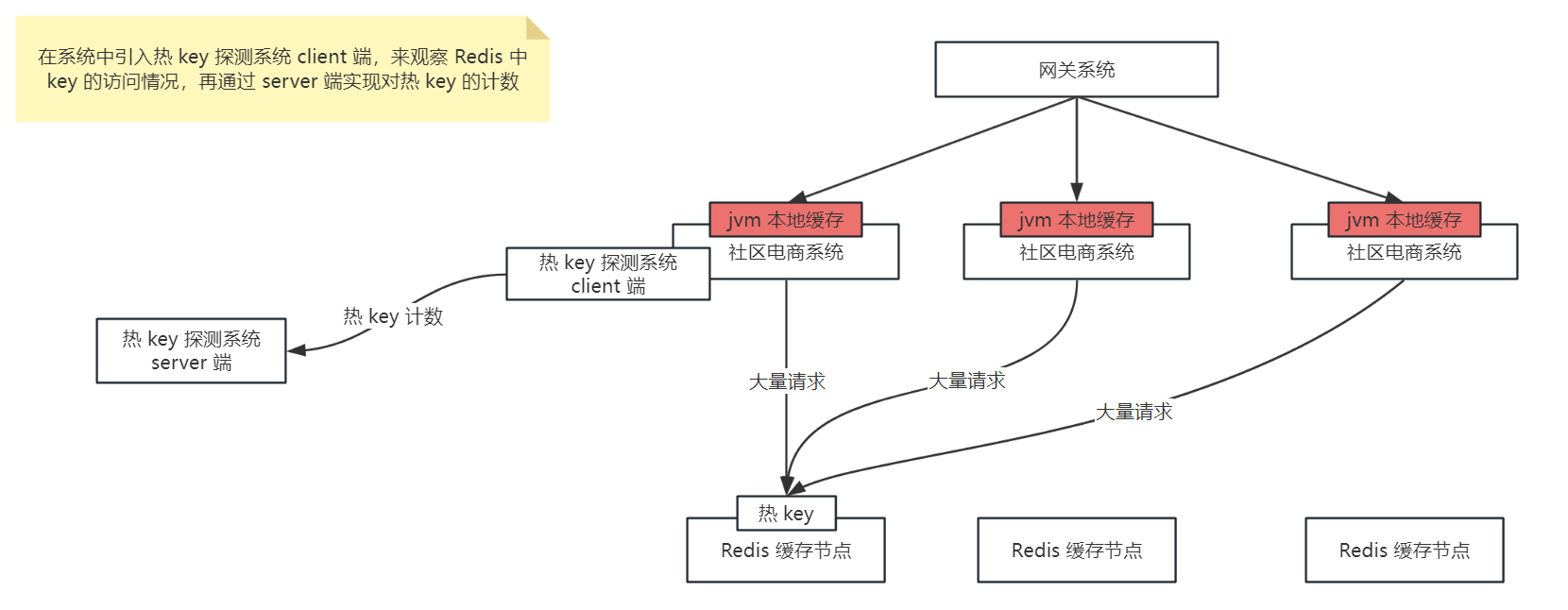
热 key 处理
热 key 问题就是某一瞬间可能某条内容特别火爆,大量的请求去访问这个数据,那么这样的 key 就是热 key,往往这样的 key 也是存储在了一个 redis 节点中,对该节点压力很大
那么对于热 key 的处理就是通过热 key 探测系统对热 key 进行计数,一旦发现了热 key,就将热 key 在 jvm 本地缓存中再存储一份,那么当再有大量请求来读取时,就直接在应用的 jvm 缓存中读取到直接返回了,不会再将压力给到同一个 redis 节点中了,如下图:
京东开源了
高性能热 key 探测中间件:JD-hotkey
,可以实时探测出系统的热数据,生产环境中可以基于
JD-hotkey
来解决热 key 的问题
大 key 处理
大 key 问题是指在 Redis 中某一个 key 所存储的 value 值特别大,几个 mb 或者几十 mb,那么如果频繁读取大 key,就会导致大量占用网络带宽,影响其他网络请求
对于大 key 会进行特殊的切片处理,并且要对大 key 进行监控,如果说发现超过 1mb 的大 key,则进行报警,并且自动处理,将这个大 key 拆成多个 k-v 进行存储,比如将
big-key
拆分为 —>
big-key01,big-key02 ...
,
那么大 key 的解决方案如下:
-
通过 crontab 定时调度 shell 脚本,每天凌晨通过 rdbtools 工具解析 Redis 的 rdb 文件,过滤 rdb 文件中的大 key 导出为 csv 文件,然后使用 SQL 导入 csv 文件存储到 MySQL 中的表
redis_large_key_log
中
-
使用 canal 监听 MySQL 的
redis_large_key_log
表的 binlog 日志,将增量数据发送到 RocketMQ 中(这里该表的增量数据就是解析出来的大 key,将大 key 的数据发送到 MQ 中,由 MQ 消费者来决定如何对这些大 key 进行处理)
-
在 MQ 的消费端可以通过一个大 key 的处理服务来对大 key 进行切分,分为多个 k-v 存储在 Redis 中
那么在读取大 key 的时候,需要判断该 key 是否是大 key,如果是的话,需要对多个 k-v 的结果进行拼接并返回
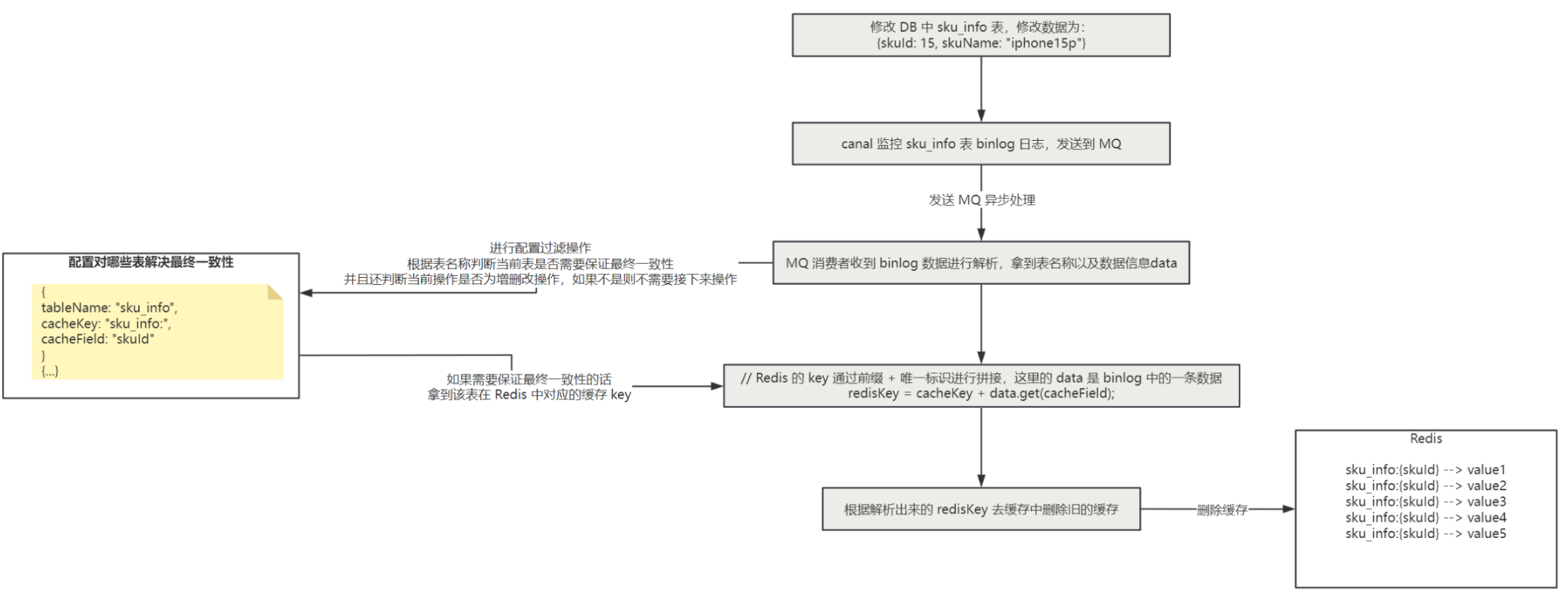
数据库与缓存最终一致性的解决方案
如果不采用更新数据时双写来保证数据库与缓存的一致性的话,可以通过
canal + RocketMQ
来实现数据库与缓存的最终一致性,对于数据直接更新 DB,通过 canal 监控 MySQL 的 binlog 日志,并且发送到 RocketMQ 中,MQ 的消费者对数据进行消费并解析 binlog,过滤掉非增删改的 binlog,那么解析 binlog 数据之后,就可以知道对 MySQL 中的哪张表进行
增删改
操作了,那么接下来我们只需要拿到这张表在 Redis 中存储的 key,再从 Redis 中删除旧的缓存即可,那么怎么取到这张表在 Redis 中存储的 key 呢?
可以我们自己来进行配置,比如说监控
sku_info
表的 binlog,那么在 MQ 的消费端解析 binlog 之后,就知道是对
sku_info
表进行了增删改的操作,那么假如 Redis 中存储了 sku 的详情信息,key 为
sku_info:{skuId}
,那么我们就可以在一个地方对这个信息进行配置:
// 配置下边这三个信息
tableName = "sku_info"; // 表示对哪个表进行最终一致性
cacheKey = "sku_info:"; // 表示缓存前缀
cacheField = "skuId"; // 缓存前缀后拼接的唯一标识
// data 是解析 binlog 日志后拿到的 key-value 值,data.get("skuId") 就是获取这一条数据的 skuId 属性值
// 如下就是最后拿到的 Redis 的 key
redisKey = cacheKey + data.get(cacheField)
那么整体的流程图如下:
Redis 集群故障探测
在生产环境中,如果 Redis 集群崩溃了,那么会导致大量的请求打到数据库中,会导致整个系统都崩溃,所以系统需要可以识别缓存故障,限流保护数据库,并且启动接口的降级机制
降级方案设计
我们在系统中操作 Redis 一般都是通过工具类来进行操作的,假设工具类有两个
RedisCache
和
RedisLock
,那么通过 AOP 对这两个工具类的所有方法
做一个切面
,如果在这两个类中执行 Redis 操作时,Redis 挂掉了,就会抛出异常(Redis 连接失败),那么我们在切面的处理方法上捕捉异常,再记录下来,判断是 Redis 集群挂了还是展示网络波动
判断是集群挂掉还是网络波动的话,我们可以配置规则,比如 30 秒内出现了 3 次 Redis 连接失败,就认为 Redis 挂掉了(可以使用 Hotkey 配置规则),那么如何自动恢复呢?可以设置 hotkey 中的缓存过期时间,设置为 60 秒,那么缓存过期之后,会再次尝试去操作 Redis,如果 Redis 恢复了就可以正常使用了,如果还没有恢复,会继续向 hotkey 中 set 数据