记录踩得坑以及部署环境流程。
搭建的是伪分布Hadoop
- 首先环境需要安装zookeeper。这个好装,不多说
- 其次比较复杂的是安装openssh。我的Linux系统是centos 7 mini版本。安装openssh之前的准备工作有很多。
需要安装的tar包有:
- libpcap-1.8.1.tar.gz
- zlib-1.2.8.tar.gz
- perl-5.22.4.tar.gz
- openssl-1.0.2j.tar.gz
- openssh-7.2p2.tar.gz
顺序是先perl,再zlib。之后就随意了。因为zlib中会依赖perl5
安装openssh主要目的是设置免密登录。方便hadoop搭建
- 安装hadoop。
需要配置Java环境变量,以及Hadoop的环境变量。Java_HOME有时候加载不到的问题可以百度,把hadoop-evn.cmd配置文件大约第25行改掉就可以了。
主要注意的是core-site.xml,hdfs-site.xml,yarn-site.xml这三个配置文件的配置
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://xxxx:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/u/hadoop-2.7.6/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>xxxxx:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xxxxxxx:50090</value>
</property>
<!-- 指定HDFS副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定NameNode的存储路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/u/hadoop-2.7.6/namenode</value>
</property>
<!--指定DataNode的存储路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/u/hadoop-2.7.6/datanode</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xxx.xxx.x.xxx</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
然后到hadoop-2.7.6/sbin/目录下面执行start-all.sh就可以一次性启动所有角色了。2.x启动成功后是这样的:
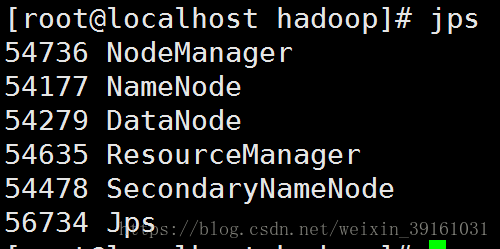
运行第一个WordCount程序
我看的书是Hadoop实战。里面的程序有点老,导致自己写的WordCount有很多方法ClassNotFound。但是hadoop是自带第一个wordcount程序的。可以看到它的源码。现在先使用它自带的wordcount来测试下这个环境是否可行
- 生成输入文件
echo "I love Java I love Hadoop I love BigData Good Good Study, Day Day Up" > wc.txt - 在Hdfs上创建文件夹,把wc.txt上传到Hdfs
hdfs dfs -mkdir -p /input/wordcount hdfs dfs -put wc.txt /input/wordcount - 然后就可以执行了。输出文件目录是不存在的
hadoop jar /home/u/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input/wordcount /output/wordcount
结果:
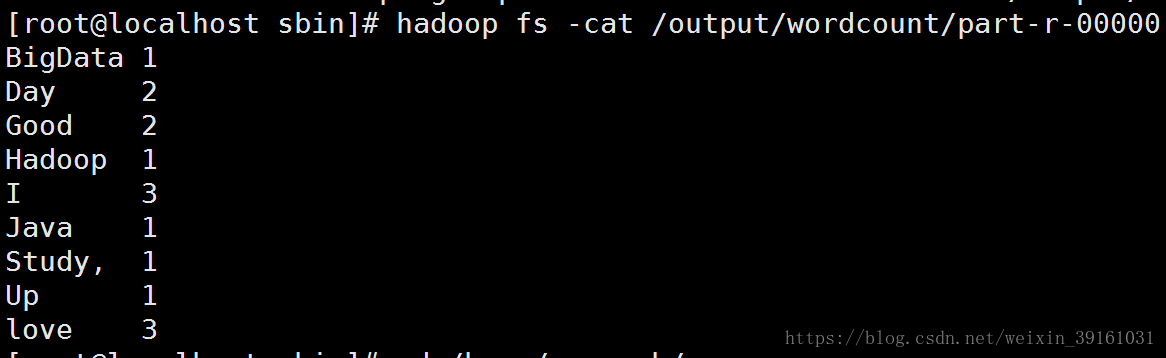
本地WordCount代码
package cn.edu.ruc.cloudcomputing.book.chapter03;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text mapOutPutKey = new Text();
private final static IntWritable mapOutPutValue = new IntWritable(1);
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String lineValue = value.toString();
String[] strs = lineValue.split(" ");
for(String str : strs){
mapOutPutKey.set(str);
context.write(mapOutPutKey, mapOutPutValue);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable outPutVlaue = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value : values){
sum += value.get();
}
outPutVlaue.set(sum);
context.write(key, outPutVlaue);
}
}
public int run(String[] args) throws Exception, InterruptedException{
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration,this.getClass().getName());
job.setJarByClass(getClass());
Path inPath = new Path(args[0]);
FileInputFormat.addInputPath(job, inPath);
Path outPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outPath);
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
boolean isSUccess = job.waitForCompletion(true);
return isSUccess ? 0 : 1;
}
public static void main(String[] args) throws Exception {
args = new String[]{
"hdfs://xxxx:9000/input/",
"hdfs://xxxx:9000/output"
};
int status = new WordCount().run(args);
System.exit(status);
}
}
主要注意端口的配置。eclipse插件端口的配置
在eclipse中打成可执行jar包
环境上运行语句:
hadoop jar wordcount.jar cn.edu.ruc.cloudcomputing.book.chapter03.WordCount
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)