-
背景
-
样本规模及划分
∙
\bullet
∙ 二分类问题,正负样本 1:1,特征数:20
∙
\bullet
∙ 训练集:3475;测试集:896;验证集:1087
-
使用模型
∙
\bullet
∙ 深度学习模型
∙
\bullet
∙ 损失函数使用对数损失函数:binary_crossentropy
∙
\bullet
∙ 优化方法:Adam,lr = 0.0035
-
遇到问题
训练中的损失函数正常下降,测试集中的损失函数正常下降;
训练中的预测准确率达到 99%
但关键问题是:在测试集的损失函数正常下降的情况下,测试集精度非常不稳定!就我以前的认知来讲,过拟合,是在训练集上准确好而测试集上不好,即二者有较大差距,但之前没有见过测试集上震荡如此大的情况,一时有些不解。
如图:

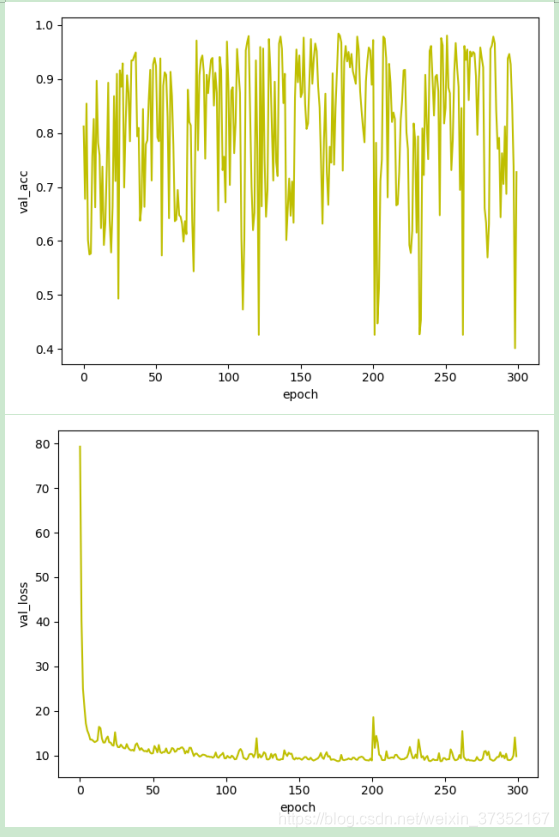
在测试集上的准确度震荡非常厉害!
-
思路
对于损失函数,虽然在下降,但却是在10左右(后来几次是 3 左右),距离最优损失值 0 仍有差距。所以我认为,此时情况相当于预测值在 类别 0,与类别 1 周围的分布较为离散,而距离常用的阈值 0.5 来说比较接近,当预测值稍微改变,可能就跨过阈值0.5,成为另一个类别。相当于预测值都在黑色框里,虽然可以被分类正确,但很容易受影响。
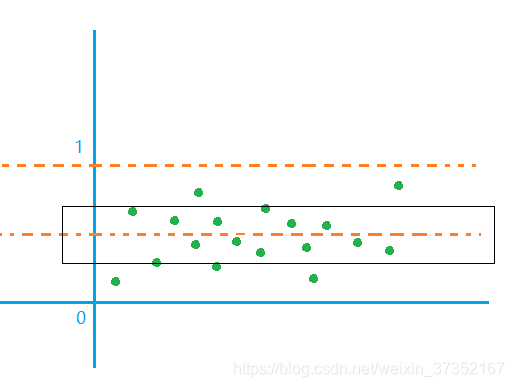
对于测试精度不稳定忽高忽低,可以说明泛化能力不稳定,有可能学到噪声或信号中的干扰,易受噪声影响。
另外,不稳定还有可能是学习速率过大引起的,在最优点附近跳跃。
综上,说明此时的模型预测结果方差大,易受波动,表明是过拟合的,而且学习速率过大。
-
解决办法
因为使用的数据量不是很大,特征数并不多,所以不需要使用 dropout 或更严格的正则化,只需降低复杂的网络结构,减少层数,降低神经元结点即可。
在降低模型复杂度后损失函数值与测试准确度完全负相关,在验证集上正确率为98.6%,损失值为:0.097, 且最终 AUC 达到 0.995.
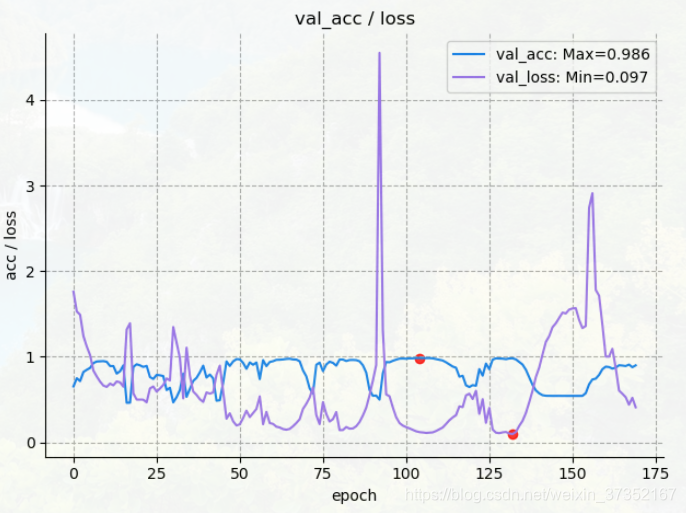
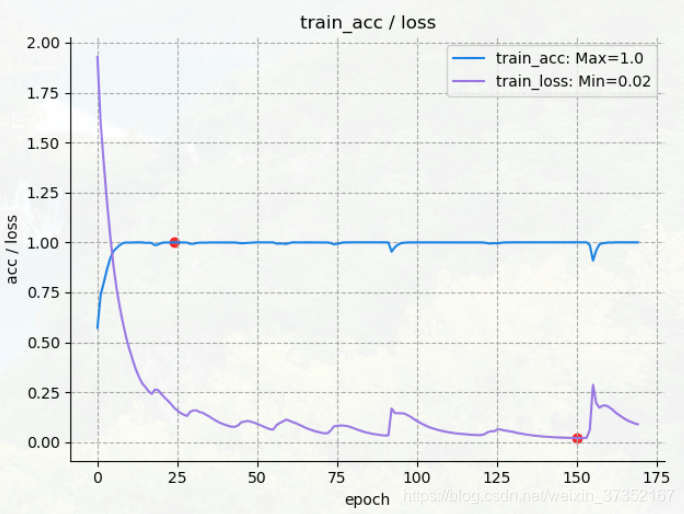
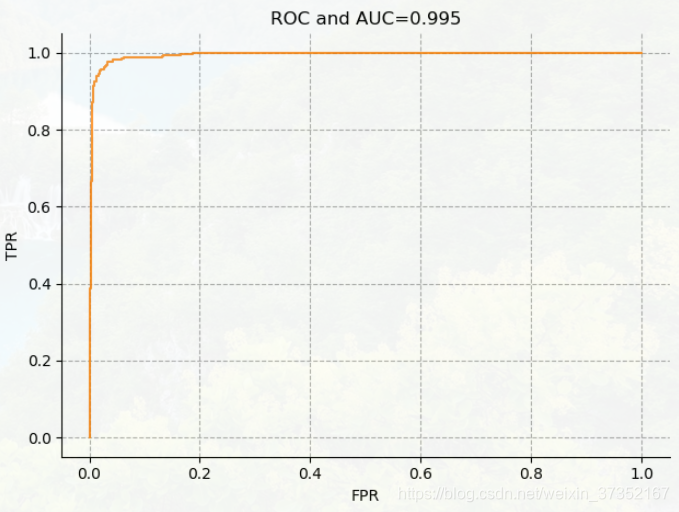
再降低学习速率,得到较为平滑的学习曲线:

问题解决。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)