先上效果图吧(因为确实也是刚入门,很多细节没有注意到的,各位尽管提出来)
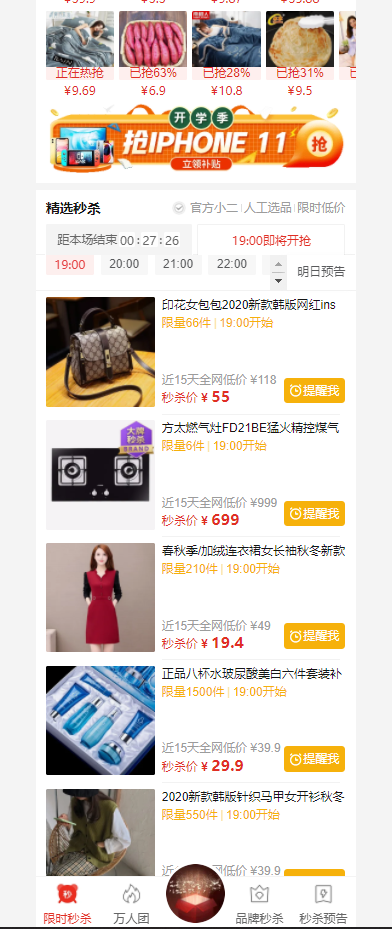
并夕夕很多时候都在不停的有秒杀商品的活动,对于价格问题,我就没法讨论了,但是人家能吸引到这么多流量,真本事还是有些的。
我只在乎他这些商品的秒杀活动我怎么把他用python爬取下来。
我先提供下url吧:https://mobile.yangkeduo.com/spike.html?__rp_name=spike_v3&_pdd_tc=ffffff&refer_share_uid=5112141669494&refer_share_id=PESOLudc1rQRf0tuIcRLKTfGwbMzRILK&_wv=41729&refer_share_channel=copy_link&_pdd_fs=1&share_uid=5112141669494&_pdd_nc=d4291d&_pdd_sbs=1&_wvx=10
先拿抓包看看,

我们知道requests请求的抓取是抓取的浏览器的第一个请求,拿来看看里面有没有我想要的信息。
哦豁,第一个请求里面并没有我要的东西,那么光只是requests.get(url)是拿不到东西的,那就得找找问题出在哪了。
实际上他的页面请求是动态的,在network里可以看到,我只要网页有往下滑,就会有新的请求在进行,那么就是XHR的问题了,看下XHR:

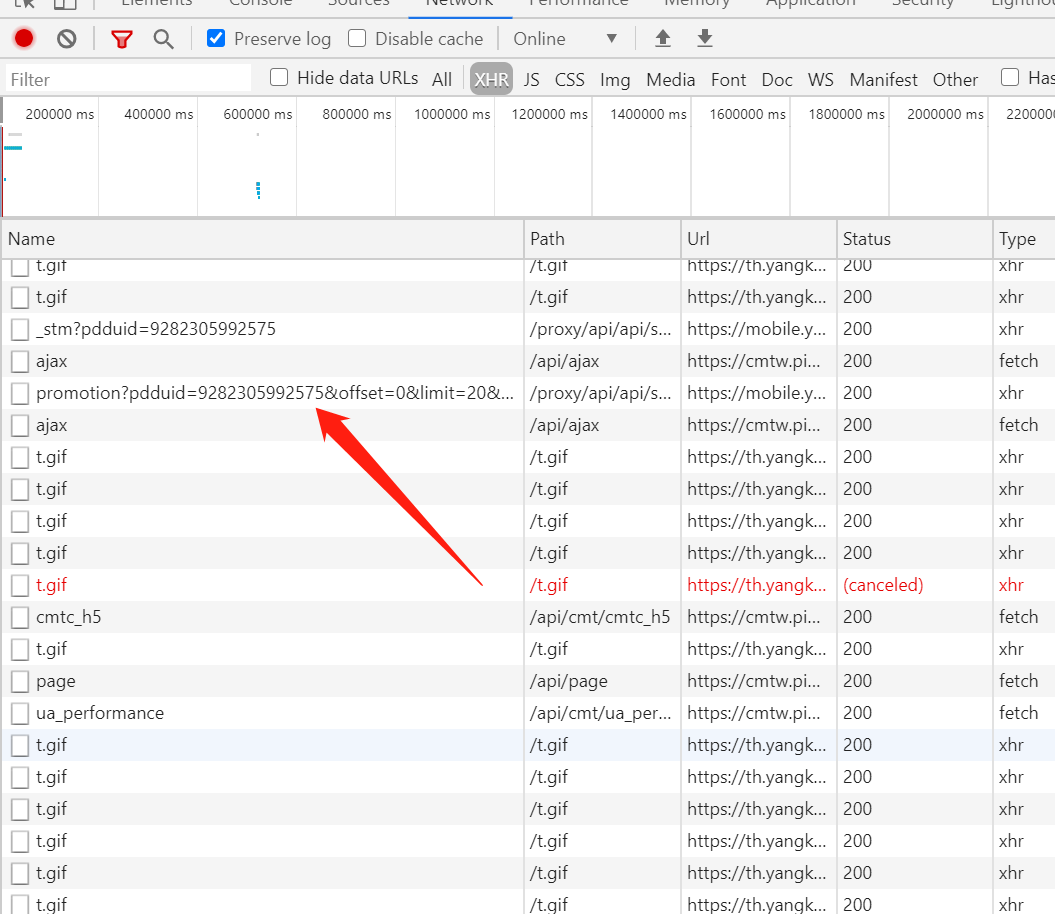
里面有个这个promotion?啥啥啥的,点开这个的preview,发现了不得了的东西
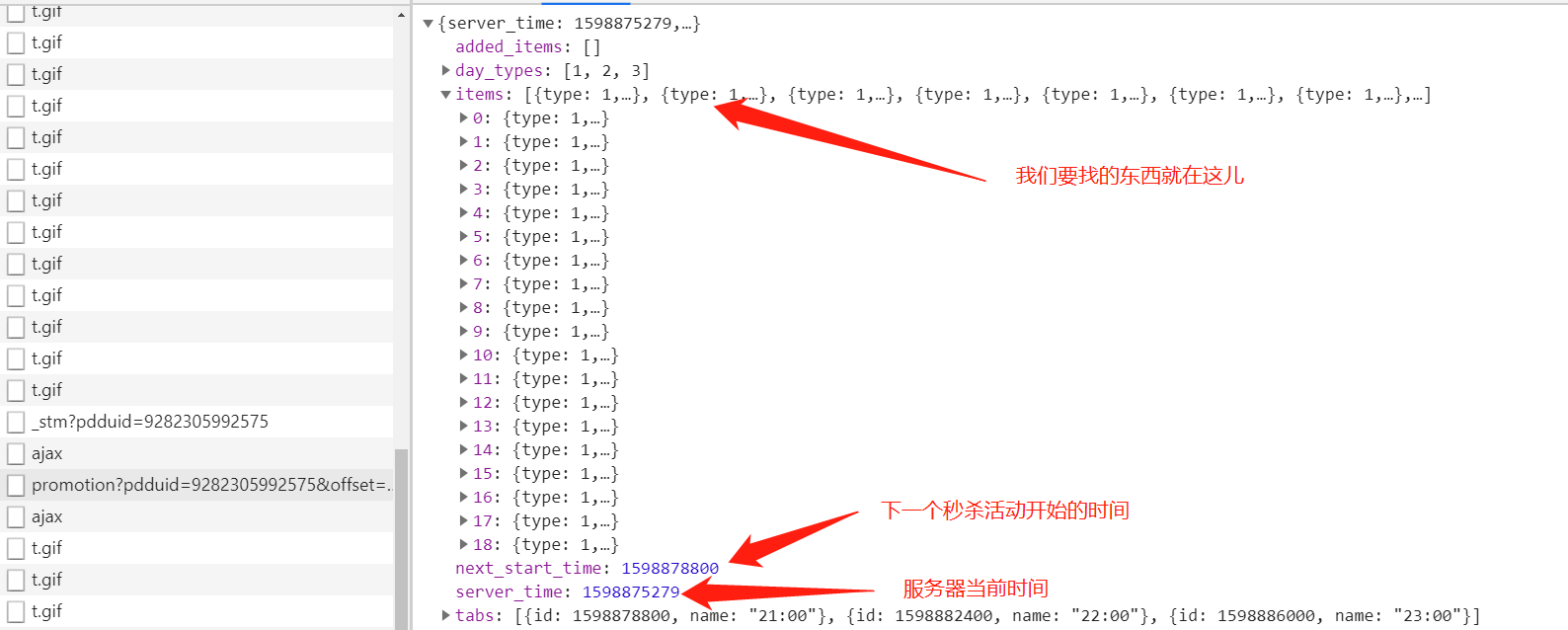
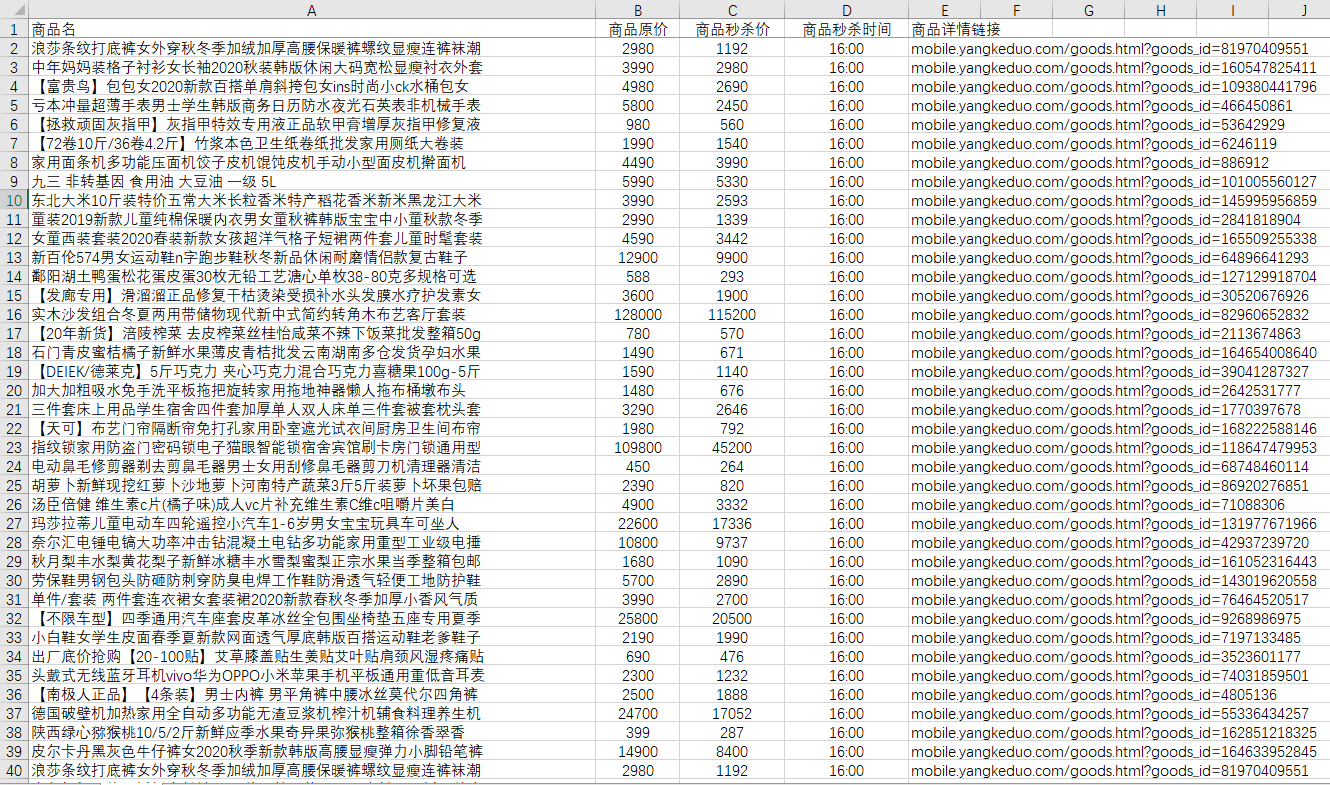
这个XHR里面包含了我们所有要找的东西,商品名,商品链接,商品图,价格等等,只是一个promotion只包括20个商品,所以网页再往后加载又会有新的promotion把信息带给我:
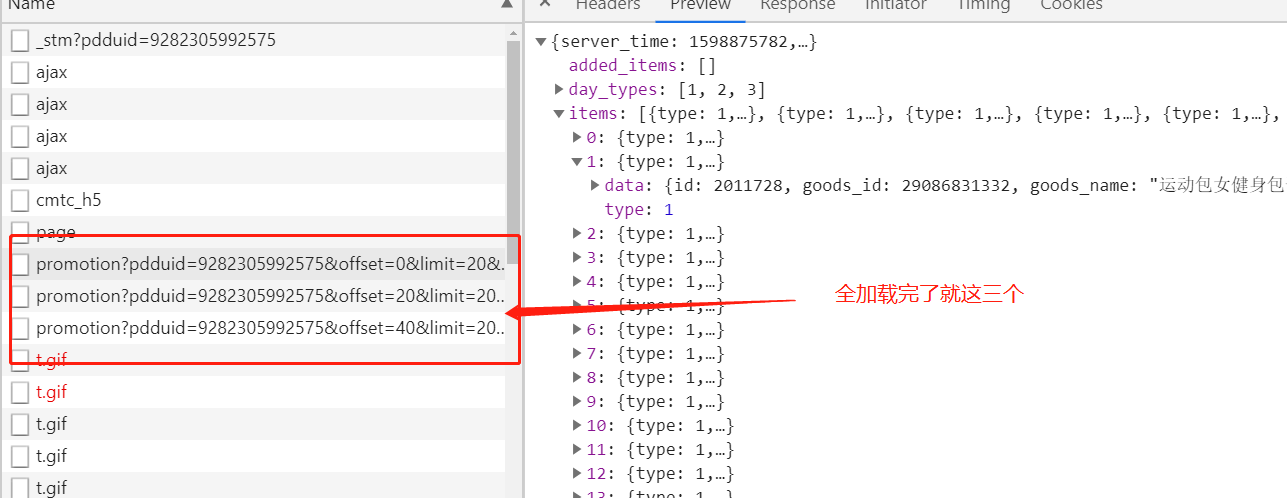
那我们的思路也有了,requests.get()请求到这些XHR,通过这几个promotion的headers和params参数我们定位到他,但requests.get()每此只能请求一个XHR,上面这个图就能解决问题,这三个XHR的区别只在于他们的“offset:”参数不一样,第一个的是“offset:0”,第二个是“offset:20”,第三个是40,那我们就有办法了。

那么我用代码实现一下:
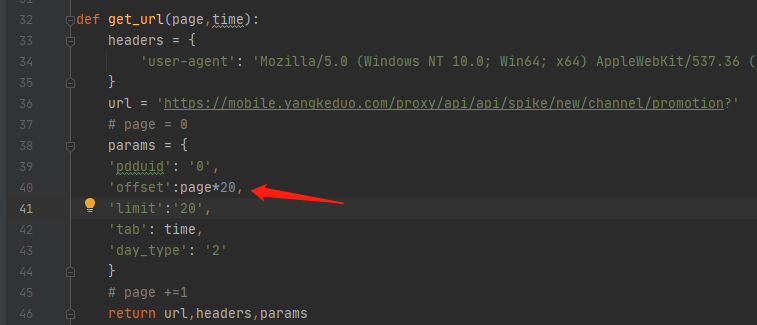
每次请求让page递增,然后乘以20就行了,

因为商品信息里存放的都是服务器的时间(以秒来计数的,例如:1598878800),我们要存下来的应该是21:00,所以还要对时间读取之后做替换。

我把下面我的整个程序留在下面吧,还是有很多需要改进的地方的,请见谅:
# -*-coding = utf-8 -*-
# @Time :2020/8/31 8:30
# @Author : jamesenh
# @File : 拼多多.py
# @Software: PyCharm
import requests,time,csv
from bs4 import BeautifulSoup
def get_goods(url,headers,params): #从url获取商品信息,再拿csv存下来
promotion = requests.get(url,headers=headers,params=params)
promotion.encoding = 'unicode_escape' #因为爬到reseponse是以’unicode‘编码方式,要转码成中文
promotion_json = promotion.json()
# print(promotion_json)
times = start_time(promotion_json) #获取各个时间段的服务器对应时间
items = promotion_json['items'] #获取商品列表
# print(items)
# print(type(items))
for item in items: #分别提取出商品名,秒杀价,秒杀开始时间等
good_name = item['data']['goods_name']
good_price_old = item['data']['group_price_original']*0.01
good_price_mini = item['data']['price']*0.01
good_time = item['data']['start_time']
good_url_one = item['data']['link_url']
good_url = 'mobile.yangkeduo.com/'+good_url_one
good_jpeg = item['data']['hd_thumb_url']
good_time = change_time(times,good_time)
save_goods(good_name,good_price_old,good_price_mini,good_time,good_url,good_jpeg) #
print(good_name,good_price_old,good_price_mini,good_time,good_url,good_jpeg)
def get_url(page,time):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36'
}
url = 'https://mobile.yangkeduo.com/proxy/api/api/spike/new/channel/promotion?'
# page = 0
params = {
'pdduid': '0',
'offset':page*20,
'limit':'20',
'tab': time,
'day_type': '2'
}
# page +=1
return url,headers,params
def save_goods(name,old,price,time,url,jpeg):
with open('拼多多.csv','a',newline='')as f:
writer = csv.writer(f)
writer.writerow([name,old,price,time,url,jpeg])
def start_time(promotion_json):
times = promotion_json['tabs']
# time = ''.join(time)
# print(times)
# print(type(times))
return times
def change_time(times,time):
for each in times:
if time == each['id']:
time = each['name']
return time
def main():
with open('拼多多.csv','w',newline='')as f:
write = csv.writer(f)
write.writerow(['商品名','商品原价','商品秒杀价','商品秒杀时间','商品详情链接','商品头图链接'])
time1 = ['1598846400']
num = 1
i=0
while i <1598886000:
i = int(1598846400)+int(3600*num)
# print(i)
time1.append(i)
num +=1
# print(start_time)
for i in time1:
page = 0
while page <3:
url,headers,params = get_url(page,i)
time.sleep(5)
page += 1
get_goods(url, headers, params)
if __name__ == '__main__':
main()