背景介绍:
现在的社会,人们产生越来越多的数据,而数据对每个人人都产生了巨大的影响。比如你去银行贷款,那么必然银行要对你做信用评估,会涉及到大数据画像等数据分析。比如美团外卖,则需要分析足够多的数据,给买卖各方做推荐引导,并同时结合大量的订单数据给骑手做配送陆续引导。
所有的这一切都离不开大数据计算,而flink作为其中的经典代表,有着极其重要的位置。在成千上万的服务器上跑着flink应用。
今天本文抛出一个flink应用里面极其重要的因子-watermark。
我们看下实际的应用场景中的例子:我们知道在实际的生产环境上,应用是在不同的物理机器上面运行着的,所以数据的产生和真正的消费是通过网络传输在不同的机器上流流转着的。有网络传输就可能会有一些延迟,毕竟网络不可靠么。
那必然就有一个问题,比如event1 产生的时间是第1S,而event2 产生的时间是第2S,因为网络延迟的原因, event2 反而先于event1到来消费,如果我们都是按照实时消费的模式来处理数据,那么必然event1的数据就被忽略了,因为event1的数据没按时到来。所以这种实时窗口的方式实际在生成中会有一些问题。
那么如何解决这样的问题呢?所以就引出了本文的内容:实际会定义一个window,允许 window规格内的数据也是正常需要处理的数据。
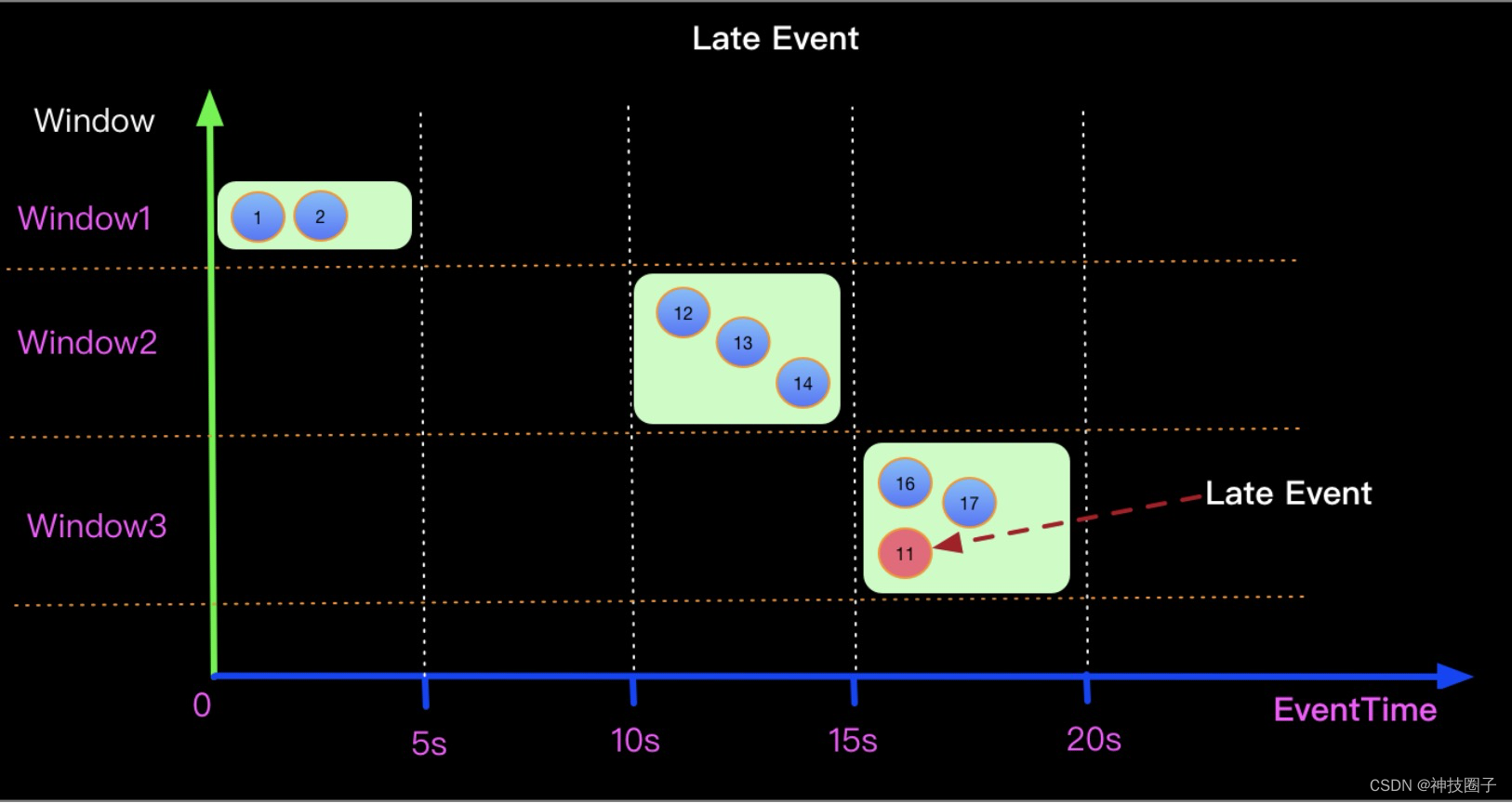
一种非实时的事件产生图示
下面开始我们的今天的主题。
--------------------------------------------------------------------------------------------------------------------------
Watermark的定义
Watermark就是为了解决上述问题由Apache Flink提出的一种机制,本质上也是一种时间戳,由Flink Source或者自定义的Watermark生成器按照一定的方式,通常是Punctuated或者Periodic两种方式生成的,接收方收到Watermark Event就会根据流入事件去调整自己管理的EventTime clock。 Apache Flink 框架保证Watermark不会重复且严格递增,接受方收到某个Watermark时候,就知道不会再有任何小于该Watermark的时间戳的event了,所以Watermark简单理解就是某种协议,约定在接受到watermark的时候,已经处理完所有小于该watermark的事件了。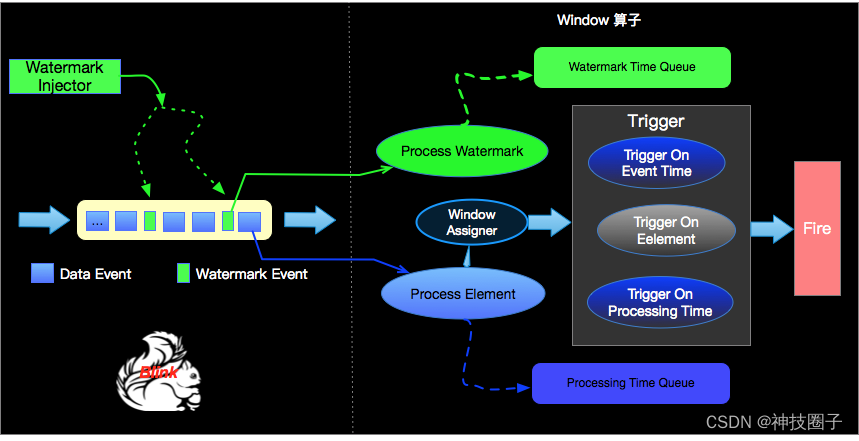
处理流程图如上图
系统里面涉及的几种时间类型
我们上文中说了解决event 乱序的问题,乱序本质就是数据的产生和消费时间没有严格顺序,在flink里面的涉及到的时间,有如下三种:
- ProcessingTime
是数据流入到具体某个算子(即将进入运算)时候相应的系统时间。ProcessingTime 有最好的性能和最低的延迟。但在分布式计算环境中相同数据流多次运行有可能产生不同的计算结果,具有不确定性。 - IngestionTime
IngestionTime是数据进入Flink框架的时间,Source Operator中去设置。结果可预算,因为只在source源处产生,IngestionTime的时间戳比较稳定,同一数据在流经不同窗口时,该时间是固定的,而对于ProcessingTime同一数据在流经不同窗口算子会有不同的处理时间戳。
EventTime
EventTime是事件流经设备的时候产生的时间。在进入Flink框架之前EventTime通常就生成到记录中,后续不改变, EventTime也可以从记录中提取出来。在实际计算中,大多会使用EventTime来进行数据计算的依据。

三种时间示意图
开篇描述的问题和本篇要介绍的Watermark所涉及的时间类型均是指EventTime类型
Watermark的接口定义
在Apache Flink官方文档中有如下定义:
- Periodic Watermarks - AssignerWithPeriodicWatermarks
| 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 | /**
* Returns the current watermark. This method is periodically called by the
* system to retrieve the current watermark. The method may return {@code null} to
* indicate that no new Watermark is available.
*
* <p>The returned watermark will be emitted only if it is non-null and itsTimestamp
* is larger than that of the previously emitted watermark (to preserve the contract of
* ascending watermarks). If the current watermark is still
* identical to the previous one, no progress in EventTime has happened since
* the previous call to this method. If a null value is returned, or theTimestamp
* of the returned watermark is smaller than that of the last emitted one, then no
* new watermark will be generated.
*
* <p>The interval in which this method is called and Watermarks are generated
* depends on {@link ExecutionConfig#getAutoWatermarkInterval()}.
*
* @see org.Apache.flink.streaming.api.watermark.Watermark
* @see ExecutionConfig#getAutoWatermarkInterval()
*
* @return {@code Null}, if no watermark should be emitted, or the next watermark to emit.
*/
@Nullable
Watermark getCurrentWatermark(); |
- Punctuated Watermarks - AssignerWithPunctuatedWatermarks
| 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | public interface AssignerWithPunctuatedWatermarks<T> extendsTimestampAssigner<T> {
/**
* Asks this implementation if it wants to emit a watermark. This method is called right after
* the {@link #extractTimestamp(Object, long)} method.
*
* <p>The returned watermark will be emitted only if it is non-null and itsTimestamp
* is larger than that of the previously emitted watermark (to preserve the contract of
* ascending watermarks). If a null value is returned, or theTimestamp of the returned
* watermark is smaller than that of the last emitted one, then no new watermark will
* be generated.
*
* <p>For an example how to use this method, see the documentation of
* {@link AssignerWithPunctuatedWatermarks this class}.
*
* @return {@code Null}, if no watermark should be emitted, or the next watermark to emit.
*/
@Nullable
Watermark checkAndGetNextWatermark(T lastElement, long extractedTimestamp);
} |
AssignerWithPunctuatedWatermarks 继承了TimestampAssigner接口 -TimestampAssigner
| 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | public interfaceTimestampAssigner<T> extends Function {
/**
* Assigns aTimestamp to an element, in milliseconds since the Epoch.
*
* <p>The method is passed the previously assignedTimestamp of the element.
* That previousTimestamp may have been assigned from a previous assigner,
* by ingestionTime. If the element did not carry aTimestamp before, this value is
* {@code Long.MIN_VALUE}.
*
* @param element The element that theTimestamp is wil be assigned to.
* @param previousElementTimestamp The previous internalTimestamp of the element,
* or a negative value, if noTimestamp has been assigned, yet.
* @return The newTimestamp.
*/
long extractTimestamp(T element, long previousElementTimestamp);
} |
| | |
英文可能看着吃力,总结了讲就是Watermark可以在事件中提取EventTime,进而定义一定的计算逻辑产生Watermark的时间戳。
Watermark的产生方式
主流的Flink生成watermark的方式有两种:
- Punctuated – 严格递增,即每个数据流中的EventTime都会产生一个Watermark。
这就有个问题,会产生大量的watermark,对接收方造成TPS的压力,所以这种方式一般用在实时性要求很高的应用系统中。。
- Periodic - 周期性的产生一个Watermark(比如多长时间或者多少条数据)。实际使用过程中需要考虑到时间以及数据量两个维度,解决时延大的问题。
怎么用就看你的场景对实时性如何要求。
用Watermark再看开篇问题
从Watermark定义和Flink用periodic方式的watermark结合起来看,因为eventTime 产生之后不能再变,而Watermark可以根据实际的系统情况自定义或者干脆跟eventTime 一致,实际上Watermark的产生是在Flink的源节点或有Watermark生成器计算的节点上产生的,Flink内部对单流或多流的场景有统一的Watermark处理。
上面的提到的延迟问题的核心在于EventTime在延迟接受到后该如何处理的问题。要解决这个问题再看一下EventTime window是如何触发的? EventTime window 计算条件是当Window计算的Timer时间戳 小于等于 当前系统的Watermak的时间戳时候进行计算。
- 当Watermark的时间戳等于Event中携带的EventTime时候,上面场景(Watermark=EventTime)的计算结果如下:
- 处理数据延迟场景,则Watermark生成策略为 Watermark = EventTime -5s, 如下:

通过上面前后两种方式对比我们知道,能处理延迟的数据核心在于window计算的时候延迟触发了(eventTime – 5s 就是延迟触发)。这个方式也有问题因为延迟计算,所以整个结果也是延迟的,这就是为什么window计算要求实时性高的时候,watermark 不能周期性太大。
有可能数据流不止一条
实际的应用系统中,会从多个source 表去输入数据,然后经过一定的规则映射,去分组处理数据,处理的数据在汇总的到相同的输出节点。这里带来一个问题,不同的source 源(还记得eventTime 是在source处产生的吗?)就必然涉及多个不同的watermark,虽然每个watermark是单调严格递增的,但是多个watermark之间就没这个约束了。这时候如果你去设计flink,如何解决问题?
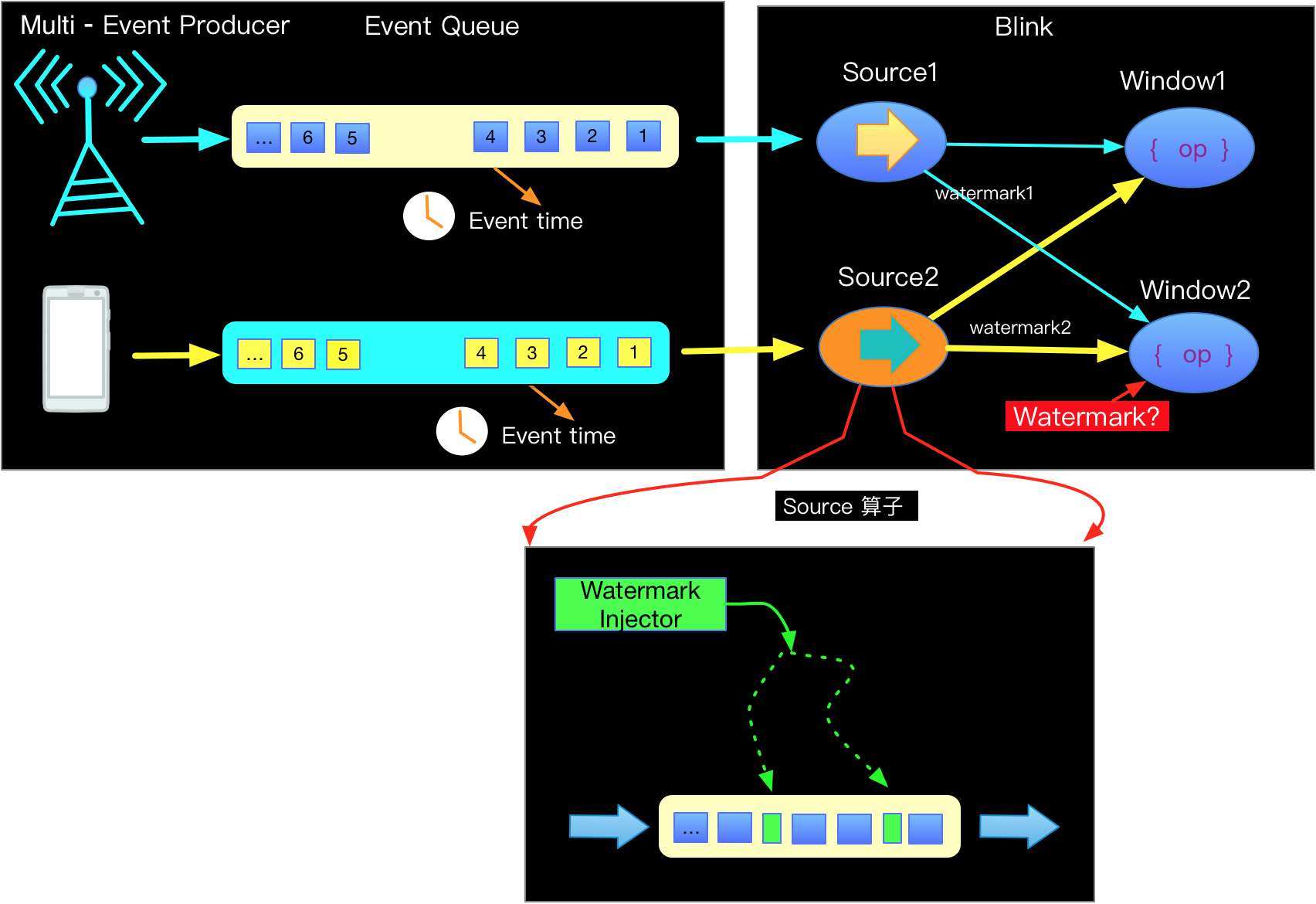
Flink解决问题这问题说起来也很简单:每一个边上只能有一个递增的Watermark按照这个逻辑去设计,一但有多个EventTime流分组汇总的时候,就挑选eventTime最小的那个waterMark作为统一的汇总的watermark给下游,这样就保证了严格递增。
这个方法其实用数学公式可以很容易推导的:
时间A: W1 , W2 , W3 ,W4, W5 (w1…w5 分别表是watermark)
时间A+5S W11 W21 W31 W41 W51 (W11..W51分别是在时间A+5s时候的watermark)
假设 W3 是 w1…w5 中最小的watermark ,那么必然有 w1 > w3 , w2 > w3 w4 > w3 w5 > w3
W41 是 W11..w51中最小的watermark , 那么必然有 w11 > w41 ,w21 > w41, w31 > w41, w51 > w41
那么因为对于同一个source ,watermark内部是严格递增的,则有如下关系:
w11 > w41 > w4 , 而 w4 又大于 w3, 那么 w41 > w3 ,结论显而易见了。

不同source 源的watermark处理流程图
小结
本文从一个分布式计算场景经典的事件延迟处理问题,引申出了flink中是如何借助 watermark解决的,并拓展了在多个source源的场景下,如何利用多watermark解决递增问题。至此,你就掌握了flink的关键技术watermark机制。
其实在watermark使用过程中会遇到各种各样具体的问题工程问题,这个就需要各位实际上手才会有真实的解决思路与感觉。而且不同的大数据平台对于watermark的使用也有些许的差异。
感谢您的观看。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)