写在开头
随着数据科学的发展,解决更为复杂问题的关键往往在于深入了解数据并采用更高级的分析工具。本文将带您深入探讨Python中的Statsmodels库,并引入一些高级功能,为更深入的数据挖掘奠定基础。
1 方差分析
1.1 方差分析概念
方差分析(Analysis of Variance,ANOVA)是一种统计方法,用于比较两个或更多组之间的均值差异是否显著。它将总体的方差分解为组内方差和组间方差,通过比较这两种方差的大小,判断组别之间是否存在显著差异。方差分析的基本思想是将总体方差分解为不同来源的方差,为组内方差和组间方差,通过比较这两种方差的大小,来判断组别间是否存在显著性差异。
解决问题
-
比较多个组的均值是否有显著差异:
方差分析能够判断不同组别之间的平均值是否有显著差异。
-
确认影响因素:
当研究中有一个自变量(例如产品类型、治疗方法)对一个因变量(例如销售额、疗效)产生影响时,方差分析可以帮助确定这种影响是否显著。
-
探索交互效应:
可以通过方差分析来探讨多个因素对因变量的交互作用,即它们是否共同影响因变量。
适合场景:
-
实验设计:
当研究中有多个实验组时,方差分析可用于检验这些组别是否有显著差异。例如,药物的疗效试验,不同广告对销售的影响等。
-
质量控制:
在生产过程中,方差分析可用于检测不同批次或生产线的产品是否存在质量差异。
-
教育研究:
在教育领域,方差分析可用于比较不同教学方法或不同学校之间学生成绩的差异。
-
社会科学研究:
在社会科学中,方差分析可以用于分析不同群体之间的差异,例如不同职业群体的薪资水平。
方差分析是一种强大的工具,但要注意确保数据满足方差分析的前提条件,如正态性和方差齐性。在实际应用中,正确选择适当的统计方法和工具对于得出可靠的结论至关重要。
1.2 利用Statsmodels进行方差分析
假设这样一个场景:我们在研究了不同广告渠道(电视广告、社交媒体广告、搜索引擎广告)对某个产品的销售影响。我们希望通过方差分析确定这些广告渠道是否在产品销售上产生显著影响。下面是使用Statsmodels进行方差分析的过程。
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 设置随机种子以确保可复现性
np.random.seed(12)
# 生成模拟数据
data = pd.DataFrame({
'Advertising_Channel': np.repeat(['TV', 'Social Media', 'Search Engine'], 30),
'Sales': np.concatenate([np.random.normal(1000, 150, 30),
np.random.normal(1200, 100, 30),
np.random.normal(800, 120, 30)])
})
# 可视化数据分布
plt.figure(figsize=(10, 6))
sns.boxplot(x='Advertising_Channel', y='Sales', data=data)
plt.title('Sales Distribution by Advertising Channel')
plt.show()
# 进行方差分析
model = ols('Sales ~ Advertising_Channel', data=data).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
# 打印ANOVA结果
print(anova_table)
运行上述代码后,结果如下:
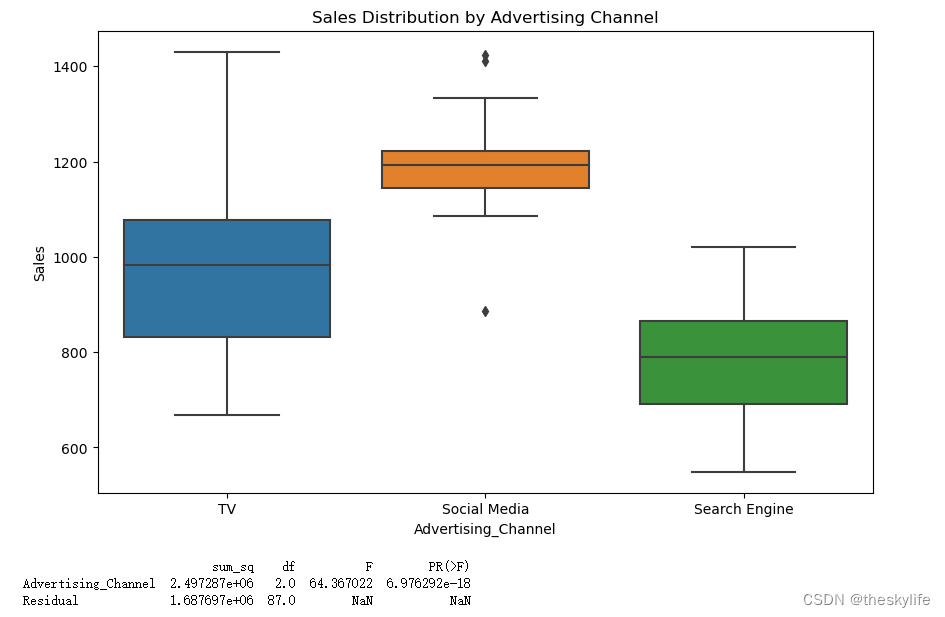
根据运行结果,可以得出下面的结论:
根据上方的结果,选择不同广告渠道确实会对产品销售产生显著影响。在实际场景中,可用于:
-
广告预算分配:
根据不同广告渠道对销售的影响,可以合理分配广告预算,以最大程度地提高销售效果。
-
广告策略调整:
结果表明某些广告渠道可能更有效,因此可以调整广告策略,加大对这些渠道的投放。
-
市场定位:
了解不同广告渠道对销售的影响,有助于更好地理解目标市场,从而更有针对性地开展市场定位和推广活动。
2 主成分分析(PCA)
Stasmodels中没有直接提供主成分分析(PCA)的实现,我们常常会用scikit-learn库进行主成分分析,并使用statsmodels库进行线性回归,用于查看主成分与变量之间的效果。
2.1 主成分分析基本介绍
主成分分析(Principal Component Analysis,PCA)是一种常用的多变量数据分析方法,其目标是通过线性变换将原始数据转换为一组新的互相正交的变量,即主成分。这些主成分是原始变量的线性组合,按照方差递减的顺序排列。主成分分析的核心思想是通过保留数据中的主要信息,实现数据降维和去相关。
2.1.1 适用数据类型
主成分分析适用于以下类型的数据:
-
高维数据:
主成分分析通常用于处理高维数据,即变量数量多于样本数量的情况。
-
连续型数据:
PCA对于连续型数据效果更好,因为它依赖于协方差矩阵的计算。
-
线性关系:
PCA假设数据是线性相关的,因此对于非线性关系的数据,PCA可能不是最佳选择。
2.1.2 能解决的问题
-
降维:
主成分分析最常见的应用之一是数据降维。通过保留主要信息,可以将高维数据集降至较低维度,减少冗余信息,提高计算效率,同时保持数据的主要特征。
-
去相关:
主成分分析能够将原始变量投影到无关的主成分上,从而去除数据中的相关性。
-
特征提取:
PCA可用于提取数据中最具代表性的特征,这些特征通常对数据变异性贡献较大。
-
数据可视化:
通过将数据投影到较低维度,可以更容易地可视化数据,观察数据的结构和模式。
-
噪声过滤:
通过保留主成分中方差较大的部分,可以过滤掉数据中的噪声。
2.1.3 适合的场景
-
多变量数据分析:
当涉及到多个相关变量时,PCA可以帮助简化数据结构,提取主要特征。
-
数据探索:
主成分分析常用于数据探索阶段,帮助了解数据的内在结构和关系。
-
模式识别:
在模式识别和机器学习中,PCA常用于降维以减少计算负担和提高模型性能。
-
图像处理:
在图像处理领域,PCA可以用于图像压缩和特征提取。
-
金融领域:
在金融数据分析中,PCA可用于处理多维的金融指标,提取影响最大的因子。
2.1.4 实现过程
主成分分析(PCA)的实现过程可以简单概括为以下几个步骤:
-
标准化数据:
将原始数据进行标准化,使得每个变量都有相同的尺度。
-
计算协方差矩阵:
计算标准化后的变量之间的协方差矩阵。
-
计算特征值和特征向量:
对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
-
选择主成分:
按照特征值的大小,选择其中最大的k个特征值对应的特征向量作为主成分。一般情况下,可以根据累计方差贡献率来确定主成分的数量。
-
构建新的数据集:
将原始数据投影到选定的主成分上,得到新的主成分数据集。
2.1.5 实现的相关公式
-
标准化数据:
Standardized Data
=
X
−
X
ˉ
σ
\text{Standardized Data} = \frac{
{X - \bar{X}}}{
{\sigma}}
Standardized Data
=
σ
X
−
X
ˉ
其中,
X
X
X
是原始数据,
X
ˉ
\bar{X}
X
ˉ
是均值,
σ
\sigma
σ
是标准差。
-
协方差矩阵:
Covariance Matrix (C)
=
1
n
−
1
(
X
T
⋅
X
)
\text{Covariance Matrix (C)} = \frac{1}{n-1}(X^T \cdot X)
Covariance Matrix (C)
=
n
−
1
1
(
X
T
⋅
X
)
其中,
X
T
X^T
X
T
是数据矩阵的转置。
-
特征值分解:
将协方差矩阵
C
C
C
进行特征值分解:
C
=
P
Λ
P
−
1
C = P \Lambda P^{-1}
C
=
P
Λ
P
−
1
其中,
P
P
P
是特征向量矩阵,
Λ
\Lambda
Λ
是对角矩阵,对角线上的元素是特征值。
-
选择主成分:
选择前k个最大的特征值对应的特征向量,构成主成分矩阵
P
k
P_k
P
k
。
-
构建新的数据集:
Transformed Data
=
X
⋅
P
k
\text{Transformed Data} = X \cdot P_k
Transformed Data
=
X
⋅
P
k
2.2 一个例子
假设现在有一份包含房屋面积(Area)、房间数(Rooms)、浴室数(Bathrooms)和售价(Price)的数据集,我们需要利用主成分分析(PCA)来降维并了解哪些特征对房价的影响最大。具体的实现步骤如下:
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
import statsmodels.api as sm
# 准备数据
np.random.seed(12)
data = pd.DataFrame({
'Area': np.random.normal(100, 20, 100),
'Rooms': np.random.normal(3, 1, 100),
'Bathrooms': np.random.normal(2, 0.5, 100),
'Price': np.random.normal(50000, 100000, 100)
})
# 进行主成分分析
features = ['Area', 'Rooms', 'Bathrooms']
X = data[features]
pca = PCA(n_components=2)
principal_components = pca.fit_transform(X)
# 将主成分添加到数据框中
data['PC1'] = principal_components[:, 0]
data['PC2'] = principal_components[:, 1]
# 利用主成分进行线性回归(使用statsmodels)
X_pca = sm.add_constant(data[['PC1', 'PC2']])
model = sm.OLS(data['Price'], X_pca).fit()
# 打印回归结果
print(model.summary())
运行上方的代码后,结果如下:
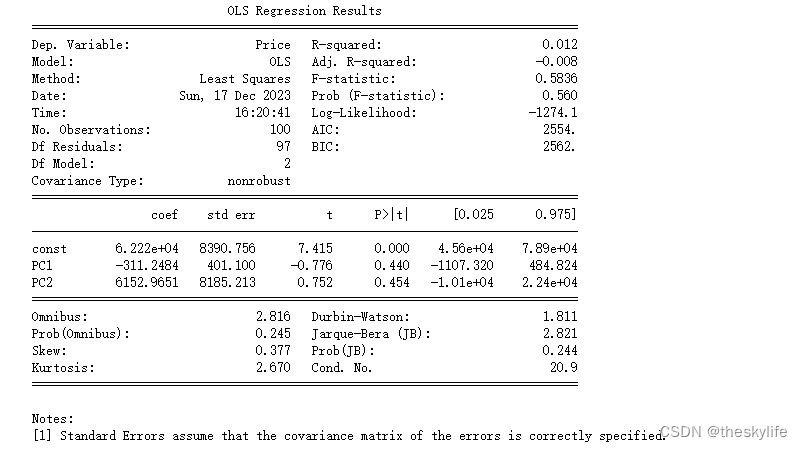
从上述运行结果中,我们可以得出以下信息:
-
R-squared (
R
2
R^2
R
2
):
-
R
2
R^2
R
2
表示模型对目标变量变异性的解释程度。在这个模型中,
R
2
R^2
R
2
为0.012,说明模型只能解释因变量变异性的1.2%。
-
Adj. R-squared (调整
R
2
R^2
R
2
):
-
调整
R
2
R^2
R
2
考虑了模型中使用的自变量的数量。在这个模型中,调整
R
2
R^2
R
2
为-0.008。
-
F-statistic:
-
F-statistic 衡量模型整体的显著性。在这个模型中,F-statistic为0.5836,对应的 p-value 为0.560。p-value大于通常的显著性水平,表明模型整体并不显著。
-
系数(coef):
-
const 代表截距,PC1 和 PC2 是主成分的系数。
-
对于 const,系数为6.222e+04,表示当主成分为0时,房价的估计值为6.222e+04。
-
对于 PC1,系数为-311.2484,表示每单位 PC1 的增加,房价估计减少311.25。
-
对于 PC2,系数为6152.9651,表示每单位 PC2 的增加,房价估计增加6152.97。
-
P>|t|:
-
P-value 衡量系数的显著性。在这个模型中,const 的 p-value 小于0.05,而 PC1 和 PC2 的 p-value 都大于0.05,表明只有截距是显著的。
-
Omnibus、Prob(Omnibus)、Jarque-Bera (JB)、Skew、Kurtosis:
-
这些统计量用于检验模型的正态性假设。在这个模型中,它们的p-value都较大,表明残差可能符合正态分布。
-
Durbin-Watson:
-
Durbin-Watson 统计量用于检验模型中残差之间的自相关性。在这个模型中,Durbin-Watson为1.811,接近2,暗示着残差可能没有显著的自相关性。
-
Cond. No.:
-
Condition Number 是用于检验模型中矩阵条件的指标。在这个模型中,Condition Number为20.9。
得出结论:
-
模型拟合程度:
R
2
R^2
R
2
很低,表明模型对于解释房价的变异性非常有限。这可能暗示主成分的选择或者主成分本身无法很好地解释房价。
-
主成分的显著性
:除了截距(const)之外,主成分 PC1 和 PC2 对于解释房价的变异性不显著。这可能表明选取的主成分无法很好地捕捉房价的关键变化。
-
模型整体显著性:
F-statistic 的 p-value较大,表明整个模型并不显著。这可能意味着我们需要重新考虑模型中的变量选择或者引入其他变量。
总体而言,这个模型并没有很好地拟合数据,对于房价的解释能力非常有限。可能需要考虑重新选择主成分,增加模型中的变量,或者使用其他方法来提高模型的拟合能力。
通过主成分分析,我们可以发现哪些房屋特征对于解释房价的变异性最为重要。线性回归的结果可以帮助我们理解每个主成分与房价之间的关系,从而指导我们在实际场景中作出更加合理的房价预测或定价策略。这个例子是为了演示主成分分析的基本流程和应用,实际场景中需要更多的数据预处理、模型选择和评估。
3 生存分析
3.1 生存分析的基本概念
3.1.1 生存分析的来源
生存分析(Survival Analysis)是一种用于研究个体在一段时间内经历特定事件(如死亡、失败、损坏)的统计方法。该方法最初在医学领域中被广泛应用,但后来扩展到其他领域,如工程学、社会科学和金融领域。
3.1.2 适用数据类型
-
右侧截尾数据:
生存分析通常应用于右侧截尾的数据,其中观察时间有限,因此事件可能在观察期内发生,也可能未发生。
-
Censoring(截尾):
当观察结束时,个体尚未经历事件,数据就会被截尾。生存分析需要考虑这种截尾情况,以准确估计生存概率。
3.1.3 解决问题
-
事件时间分布:
生存分析可以用来估计个体经历特定事件的时间分布,例如生命终点、产品故障等。
-
比较生存曲线:
生存分析允许比较不同群体、治疗组和对照组的生存曲线,以评估干预措施的效果。
-
危险因素:
生存分析可以识别和量化影响生存时间的危险因素,这些危险因素可以是疾病特征、治疗方案或其他相关因素。
-
时间相关性:
生存分析考虑了时间的因素,可以更全面地理解事件发生的时间模式和动态。
3.1.4 适用场景
-
医学研究:
评估治疗效果、疾病复发的概率,研究患者的生存时间等。
-
金融领域:
评估投资产品的寿命,了解客户的生命周期价值。
-
工业工程:
估计设备或系统的可靠性,预测设备故障的发生时间。
-
社会科学:
研究社会现象,如婚姻的持续时间、雇佣关系的稳定性等。
-
公共卫生:
研究疾病的流行病学特征,制定公共卫生政策。
3.1.5 生存分析方法
-
Kaplan-Meier 生存曲线:
用于估计未经历事件的个体在给定时间点上的生存概率。
-
Cox 比例风险模型:
用于探讨不同因素对生存时间的影响,考虑多个协变量。
-
Log-Rank 检验:
用于比较两个或多个生存曲线是否存在显著差异。
-
加速失效时间模型(Accelerated Failure Time Model):
用于描述因素如何影响生存时间的缩短或延长。
总体而言,生存分析对于研究个体在一段时间内经历事件的时间模式提供了强大的工具,适用于多个领域中的时间相关性问题。
3.2 生存分析的应用
生存分析常用于处理时间相关数据,例如医学研究中的患者生存时间。以下是一个简单的生存分析示例,
事件 (Event)
表示客户是否在观察期间发生了订购(1 表示发生,0 表示未发生)。
:
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 设置随机种子
np.random.seed(123)
# 客户数据
customer_data = pd.DataFrame({
'Customer_ID': range(1, 101),
'First_Order': np.random.randint(1, 180, size=100),
'Last_Order': np.random.randint(180, 360, size=100),
})
# 计算生存时间和事件状态
customer_data['Survival_Time'] = customer_data['Last_Order'] - customer_data['First_Order']
customer_data['Event'] = np.random.choice([0, 1], size=100, p=[0.2, 0.8])
# 创建SurvfuncRight对象
sf = sm.SurvfuncRight(customer_data['Survival_Time'], customer_data['Event'])
# 生存函数摘要
summary = sf.summary()
# 输出结果
print(summary)
# 使用SurvfuncRight对象进行生存曲线绘制
sf.plot()
# 设置图形属性
plt.title('Survival Curve')
plt.xlabel('Time')
plt.ylabel('Survival Probability')
plt.show()
运行上述结果后,我们可以得到下图的运行结果:
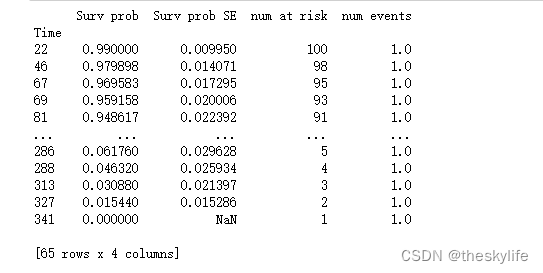
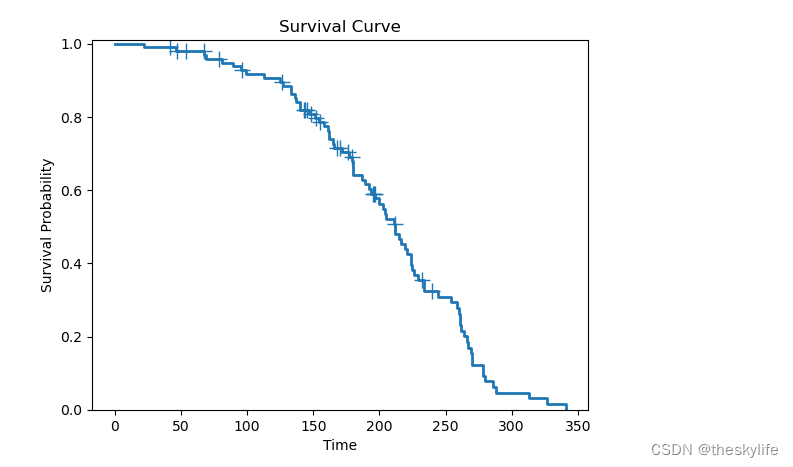
从上述生存分析的结果,获取到在不同时间点上的生存概率、标准误差、样本量和事件数量等信息。我们可以得到下面的信息:
-
Surv prob (Survival Probability):
-
在时间点 22,生存概率为 0.99,表示在这个时间点前,有 99% 的客户仍然保持活跃状态。
-
随着时间推移,生存概率逐渐下降。
-
Surv prob SE (Survival Probability Standard Error):
-
标准误差表示相应生存概率的估计不确定性。标准误差越小,估计的生存概率越可信。
-
在所有时间点上,标准误差都在逐渐增加,因为样本量在减小。
-
num at risk (Number at Risk):
-
表示在给定时间点上参与生存分析的客户数量。在初始时间点 22,所有100名客户都参与了分析。
-
随着时间的推移,客户数量逐渐减少,因为部分客户发生了事件(生命周期结束)。
-
num events (Number of Events):
-
在给定时间点上发生事件的客户数量。在所有时间点上,每个时间点都有一个事件发生。
这个生存分析的结果表明,客户在初始时段具有较高的生存概率,但随着时间推移,生存概率逐渐下降。在观察的时间范围内,所有客户最终都发生了事件,生命周期结束。标准误差的增加可能表示由于样本量的减少,生存概率的估计不确定性增加。另外,通过下面这条曲线更直观地了解客户在不同时间点上的生存情况。曲线下降越快,说明生存概率下降得越迅速。
写在最后
通过深入挖掘Statsmodels库的高级功能,我们不仅能够更全面、更精确地理解数据,还能为解决更为复杂的问题建模提供坚实基础。无论是探索数据结构、进行降维分析,还是研究事件发生的概率,Statsmodels都为高级数据分析提供了可靠的支持。让我们在实际场景中应用这些强大工具,通过数据和代码来发现更多有趣的现象,为未来的数据科学探索打下坚实的基础。