为何备份?
备份 SQL Server 数据库、在备份上运行测试还原过程以及在另一个安全位置存储备份副本可防止可能的灾难性数据丢失。 备份是保护数据的唯一方法 。
使用有效的数据库备份,可从多种故障中恢复数据,例如:
-
介质故障。
-
用户错误(例如,误删除了某个表)。
-
硬件故障(例如,磁盘驱动器损坏或服务器报废)。
-
自然灾难。 通过使用 SQL Server 备份到 Azure Blob
存储服务,可以在本地位置之外的其他区域创建一个站外备份,这样在发生影响本地位置的自然灾难时仍可以使用数据库。
此外,数据库备份对于进行日常管理(如将数据库从一台服务器复制到另一台服务器、设置 Always On 可用性组 或数据库镜像以及进行存档)非常有用。
备份术语的术语表
数据备份 (data backup)
完整数据库的数据备份(数据库备份)、部分数据库的数据备份(部分备份)或一组数据文件或文件组的数据备份(文件备份)。
数据库备份 (database backup)
数据库的备份。 完整数据库备份表示备份完成时的整个数据库。 差异数据库备份只包含自最近完整备份以来对数据库所做的更改。
差异备份 (differential backup)
一种数据备份,基于完整数据库或部分数据库或一组数据文件或文件组(差异基准)的最新完整备份,并且仅包含自确定差异基准以来发生更改的数据。
完整备份 (full backup)
一种数据备份,包含特定数据库或者一组特定的文件组或文件中的所有数据,以及可以恢复这些数据的足够的日志。
日志备份 (log backup)
包括以前日志备份中未备份的所有日志记录的事务日志备份。 (完整恢复模式)
recover
将数据库恢复到稳定且一致的状态。
recovery
将数据库恢复到事务一致状态的数据库启动阶段或 Restore With Recovery 阶段。
恢复模式
用于控制数据库上的事务日志维护的数据库属性。 有三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式。 数据库的恢复模式确定其备份和还原要求。
还原 (restore)
一种包括多个阶段的过程,用于将指定 SQL Server 备份中的所有数据和日志页复制到指定数据库,然后通过应用记录的更改使该数据在时间上向前移动,以前滚备份中记录的所有事务。
备份和还原策略
备份和还原数据必须根据特定环境进行自定义,并且必须使用可用资源。 因此,要可靠地使用备份和还原进行恢复,需要制定备份和还原策略。设计完善的备份和还原策略可以平衡业务需求,以实现最大的数据可用性和最小的数据丢失,同时考虑维护和存储备份的成本。
备份和还原策略包含备份部分和还原部分。 策略的备份部分定义备份的类型和频率、备份所需硬件的特性和速度、备份的测试方法以及备份介质的存储位置和方法(包括安全注意事项)。 策略的还原部分定义负责执行还原的人员、如何执行还原以满足数据库可用性和最大程度减少数据丢失的目标,以及如何测试还原。
设计有效的备份和还原策略需要仔细计划、实现和测试。 需要进行测试:直到成功还原了还原策略中包含的所有组合中的备份并且测试了还原的数据库是否具有物理一致性后,才会生成备份策略。 必须考虑各种因素。 其中包括:
-
组织在生产数据库方面的目标,尤其是对可用性和防止数据丢失或损坏的要求。
-
每个数据库的特性包括:大小、使用模式、内容特性以及数据要求等。
-
对资源的约束,例如:硬件、人员、备份介质的存储空间以及所存储介质的物理安全性等。
最佳做法建议
使用独立的存储
重要
确保将数据库备份放在与数据库文件不同的物理位置或设备上。
存储数据库的物理驱动器出现故障或崩溃时,可恢复性取决于能否访问存储备份的独立驱动器或远程设备以执行还原。
请记住,你可以在同一个物理磁盘驱动器中创建多个逻辑卷或分区。 在为备份选择存储位置之前,请仔细研究磁盘分区和逻辑卷布局。
如何选择恢复模式
备份和还原操作发生在恢复模式的上下文中。 恢复模式是一种数据库属性,用于控制事务日志的管理方式。 因此,数据库的恢复模式决定了数据库支持的备份类型和还原方案,以及事务日志备份的大小。 通常,数据库使用
简单恢复模式或完整恢复模式
。 可以在执行大容量操作之前切换到大容量日志恢复模式,以补充完整恢复模式。 有关这些恢复模式以及它们是如何影响事务日志管理方式的说明,请参阅 事务日志 (SQL Server)。
数据库的最佳恢复模式取决于您的业务要求。 若要免去事务日志管理工作并简化备份和还原,请使用
简单恢复模式
。 若要在管理开销一定的情况下使工作丢失的可能性降到最低,请使用
完整恢复模式
。 为了在大容量日志操作期间最大程度减少对日志大小的影响,同时允许这些操作的可恢复性,请使用大容量日志恢复模式。 有关恢复模式对备份和还原的影响的信息,请参阅 备份概述 (SQL Server) 。
设计备份策略
当为特定数据库选择了满足业务要求的恢复模式后,需要计划并实现相应的备份策略。 最佳备份策略取决于各种因素,以下因素尤其重要:
-
一天中应用程序访问数据库的时间有多长?
如果存在一个可预测的非高峰时段,则建议您将完整数据库备份安排在此时段。
-
更改和更新可能发生的频率如何?
如果更改经常发生,请考虑下列事项:
在简单恢复模式下,请考虑将差异备份安排在完整数据库备份之间。 差异备份只能捕获自上次完整数据库备份之后的更改。
在完整恢复模式下,应安排经常的日志备份。 在完整备份之间安排差异备份可减少数据还原后需要还原的日志备份数,从而缩短还原时间。
-
可能只是更改数据库的小部分内容,还是需要更改数据库的大部分内容?
对于更改集中于部分文件或文件组的大型数据库,部分备份和/或文件备份非常有用。 有关详细信息,请参阅 SQL Server) 部分备份 和
完整文件 (备份 (SQL Server) 。
-
完整数据库备份需要多少磁盘空间?
-
你的企业需要维护过去多久的备份?
确保你已根据应用程序需求和业务需求制定了适当的备份计划。 随着备份变得陈旧,数据丢失风险会更高,除非你有办法重新生成故障点之前的所有数据。
由于存储资源限制而选择处理旧备份之前,请考虑是否需要以前的可恢复性
计划备份
执行备份操作对运行中的事务影响很小,因此可以在正常操作过程中执行备份操作。 您可以在对生产工作负荷的影响很小的情况下执行 SQL Server 备份。
有关备份期间并发限制的信息,请参阅 备份概述 (SQL Server) 。
确定所需的备份类型和必须执行每种备份类型的频率后,建议您将定期备份计划为数据库维护计划的一部分。 有关维护计划以及如何为数据库备份和日志备份创建维护计划的信息,请参阅 Use the Maintenance Plan Wizard。
备份操作限制
可以在
数据库在线并且正在使用时进行备份
。 但是,存在下列限制:
无法备份脱机数据
隐式或显式引用脱机数据的任何备份操作都会失败。 一些典型示例包括:
-
您请求完整数据库备份,但是数据库的一个文件组脱机。 由于所有文件组都隐式包含在完整数据库备份中,因此,此操作将会失败。
若要备份此数据库,可以使用文件备份并仅指定联机的文件组。
-
请求部分备份,但是有一个读/写文件组处于脱机状态。 由于部分备份需要使用所有读/写文件组,因此该操作失败。
-
请求特定文件的文件备份,但是其中有一个文件处于脱机状态。 该操作失败。 若要备份联机文件,可以省略文件列表中的脱机文件并重复该操作。
通常,即使一个或多个数据文件不可用,日志备份也会成功。 但如果某个文件包含大容量日志恢复模式下所做的大容量日志更改,则所有文件都必须都处于联机状态才能成功备份。
并发限制
SQL Server 可以使用联机备份过程来备份数据库。 在备份过程中,可以进行多个操作;例如:在执行备份操作期间允许使用 INSERT、UPDATE 或 DELETE 语句。 但是,如果在正在创建或删除数据库文件时尝试启动备份操作,则备份操作将等待,直到创建或删除操作完成或者备份超时。
在数据库备份或事务日志备份的过程中无法执行的操作包括:
-
文件管理操作,如含有 ADD FILE 或 REMOVE FILE 选项的 ALTER DATABASE 语句。
-
收缩数据库或文件操作。 这包括自动收缩操作。
-
如果在进行备份操作时尝试创建或删除数据库文件,则创建或删除操作将失败。
如果备份操作与文件管理操作或收缩操作重叠,则产生冲突。 无论哪个冲突操作首先开始,第二个操作总会等待第一个操作设置的锁超时。(超时期限由会话超时设置控制。)如果在超时期限内释放锁,第二个操作将继续执行。 如果锁超时,则第二个操作失败。
测试备份!
直到完成备份测试后,才会生成还原策略。 必须通过将数据库副本还原到测试系统,针对每个数据库的备份策略进行全面测试。 您必须对每种要使用的备份类型进行还原测试。 另外建议在还原备份后,通过数据库的 DBCC CHECKDB 执行数据库一致性检查,以验证备份媒体是否未损坏。
使用 Transact-SQL 创建维护计划
在 “对象资源管理器” 中,连接到 数据库引擎的实例。
在标准菜单栏上,单击 “新建查询” 。
将以下示例复制并粘贴到查询窗口中,然后单击“执行” 。
USE msdb;
GO
-- Adds a new job, executed by the SQL Server Agent service, called "HistoryCleanupTask_1".
EXEC dbo.sp_add_job
@job_name = N'HistoryCleanupTask_1',
@enabled = 1,
@description = N'Clean up old task history' ;
GO
-- Adds a job step for reorganizing all of the indexes in the HumanResources.Employee table to the HistoryCleanupTask_1 job.
EXEC dbo.sp_add_jobstep
@job_name = N'HistoryCleanupTask_1',
@step_name = N'Reorganize all indexes on HumanResources.Employee table',
@subsystem = N'TSQL',
@command = N'USE AdventureWorks2012
GO
ALTER INDEX AK_Employee_LoginID ON HumanResources.Employee REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE AdventureWorks2012
GO
ALTER INDEX AK_Employee_NationalIDNumber ON HumanResources.Employee REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE AdventureWorks2012
GO
ALTER INDEX AK_Employee_rowguid ON HumanResources.Employee REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE AdventureWorks2012
GO
ALTER INDEX IX_Employee_OrganizationLevel_OrganizationNode ON HumanResources.Employee REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE AdventureWorks2012
GO
ALTER INDEX IX_Employee_OrganizationNode ON HumanResources.Employee REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE AdventureWorks2012
GO
ALTER INDEX PK_Employee_BusinessEntityID ON HumanResources.Employee REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
',
@retry_attempts = 5,
@retry_interval = 5 ;
GO
-- Creates a schedule named RunOnce that executes every day when the time on the server is 23:00.
EXEC dbo.sp_add_schedule
@schedule_name = N'RunOnce',
@freq_type = 4,
@freq_interval = 1,
@active_start_time = 233000 ;
GO
-- Attaches the RunOnce schedule to the job HistoryCleanupTask_1.
EXEC sp_attach_schedule
@job_name = N'HistoryCleanupTask_1',
@schedule_name = N'RunOnce' ;
GO
有关详细信息,请参阅:
sp_add_job (Transact-SQL)
添加 SQL 代理服务执行的新作业
sp_add_job [ @job_name = ] 'job_name'
[ , [ @enabled = ] enabled ]
[ , [ @description = ] 'description' ]
[ , [ @start_step_id = ] step_id ]
[ , [ @category_name = ] 'category' ]
[ , [ @category_id = ] category_id ]
[ , [ @owner_login_name = ] 'login' ]
[ , [ @notify_level_eventlog = ] eventlog_level ]
[ , [ @notify_level_email = ] email_level ]
[ , [ @notify_level_netsend = ] netsend_level ]
[ , [ @notify_level_page = ] page_level ]
[ , [ @notify_email_operator_name = ] 'email_name' ]
[ , [ @notify_netsend_operator_name = ] 'netsend_name' ]
[ , [ @notify_page_operator_name = ] 'page_name' ]
[ , [ @delete_level = ] delete_level ]
[ , [ @job_id = ] job_id OUTPUT ]
参数
[ @job_name = ] ‘job_name’ 作业的名称。 该名称必须是唯一的,并且不能包含 (%) 字符的百分比。 job_name为 nvarchar (128) ,无默认值。
[ @enabled = ] enabled 指示已添加的作业的状态。 enabled为 tinyint,默认值为 1 (已启用) 。 如果 为 0,则作业未启用,并且不按计划运行;但是,它可以手动运行。
[ @description = ] ‘description’ 作业的说明。 说明 为 nvarchar (512) ,默认值为 NULL。 如果省略 说明 ,则使用“无可用说明”。
[ @start_step_id = ] step_id 要为作业执行的第一步的标识号。 step_id为 int,默认值为 1。
[ @category_name = ] ‘category’ 作业的类别。 类别为 sysname,默认值为 NULL。
[ @category_id = ] category_id 用于指定作业类别的语言无关的机制。 category_id为 int,默认值为 NULL。
[ @owner_login_name = ] ‘login’ 拥有作业的登录名。 login为 sysname,默认值为 NULL,该默认值解释为当前登录名。 只有 sysadmin 固定服务器角色的成员才能设置或更改 @owner_login_name的值。 如果不是 sysadmin 角色集的成员的用户或更改 @owner_login_name的值,则执行此存储过程会失败,并返回错误。
[ @notify_level_eventlog = ] eventlog_level 一个值,该值指示何时在此作业的 Microsoft Windows 应用程序日志中放置条目。 eventlog_level为 int,可以是其中一个值。
值 说明
0 从不
1 成功时
2 (默认值) 失败时
3 始终
[ @notify_level_email = ] email_level 一个值,该值指示完成此作业后何时发送电子邮件。 email_level为 int,默认值为 0,表示永不。 email_level使用 与eventlog_level相同的值。
[ @notify_level_netsend = ] netsend_level 一个值,该值指示完成此作业后何时发送网络消息。 netsend_level为 int,默认值为 0,表示永不。 netsend_level 使用 与eventlog_level相同的值。
[ @notify_level_page = ] page_level 一个值,该值指示完成此作业后何时发送页面。 page_level为 int,默认值为 0,表示永远不会。 page_level使用 与eventlog_level相同的值。
[ @notify_email_operator_name = ] ‘email_name’ 到达 email_level 时要发送电子邮件的人员的电子邮件名称。 email_name 为 sysname,默认值为 NULL。
[ @notify_netsend_operator_name = ] ‘netsend_name’ 完成此作业后向其发送网络消息的操作员的名称。 netsend_name为 sysname,默认值为 NULL。
[ @notify_page_operator_name = ] ‘page_name’ 完成此作业后要页面的人员的名称。 page_name为 sysname,默认值为 NULL。
[ @delete_level = ] delete_level 一个值,该值指示何时删除作业。 delete_value为 int,默认值为 0,这意味着永远不会。 delete_level使用与 eventlog_level相同的值。
备注
当delete_level为 3 时,无论为作业定义的任何计划,该作业仅执行一次。 而且,如果作业将自身删除,则将同时删除该作业的历史记录。
[ @job_id = ] _job_idOUTPUT 如果成功创建,则分配给作业的作业标识号。 job_id 是 uniqueidentifier 类型的输出变量,默认值为 NULL。
sp_add_jobstep (Transact-SQL)
将步骤 (操作) 添加到 SQL 代理作业。
sp_add_jobstep [ @job_id = ] job_id | [ @job_name = ] 'job_name'
[ , [ @step_id = ] step_id ]
{ , [ @step_name = ] 'step_name' }
[ , [ @subsystem = ] 'subsystem' ]
[ , [ @command = ] 'command' ]
[ , [ @additional_parameters = ] 'parameters' ]
[ , [ @cmdexec_success_code = ] code ]
[ , [ @on_success_action = ] success_action ]
[ , [ @on_success_step_id = ] success_step_id ]
[ , [ @on_fail_action = ] fail_action ]
[ , [ @on_fail_step_id = ] fail_step_id ]
[ , [ @server = ] 'server' ]
[ , [ @database_name = ] 'database' ]
[ , [ @database_user_name = ] 'user' ]
[ , [ @retry_attempts = ] retry_attempts ]
[ , [ @retry_interval = ] retry_interval ]
[ , [ @os_run_priority = ] run_priority ]
[ , [ @output_file_name = ] 'file_name' ]
[ , [ @flags = ] flags ]
[ , { [ @proxy_id = ] proxy_id
| [ @proxy_name = ] 'proxy_name' } ]
参数
[ @job_id = ] job_id 要向其添加步骤的作业的标识号。 job_id 是 uniqueidentifier,默认值为 NULL。
[ @job_name = ] ‘job_name’ 要向其添加步骤的作业的名称。 job_name 为 sysname,默认值为 NULL。
备注
必须指定 job_id 或 job_name ,但不能指定两者。
[ @step_id = ] step_id 作业步骤的序列号。 步骤标识号从 1 开始,增量不带间隙。 如果在现有序列中插入一个步骤,则将自动调整序列号。 如果未指定 step_id, 则提供一个值。 step_id 为 int,默认值为 NULL。
[ @step_name = ] ‘step_name’ 步骤的名称。 step_name 为 sysname,无默认值。
[ @subsystem = ] ‘subsystem’ SQL Server 代理服务用来执行 命令的子系统。 子系统 是 nvarchar (40) ,可以是其中一个值。
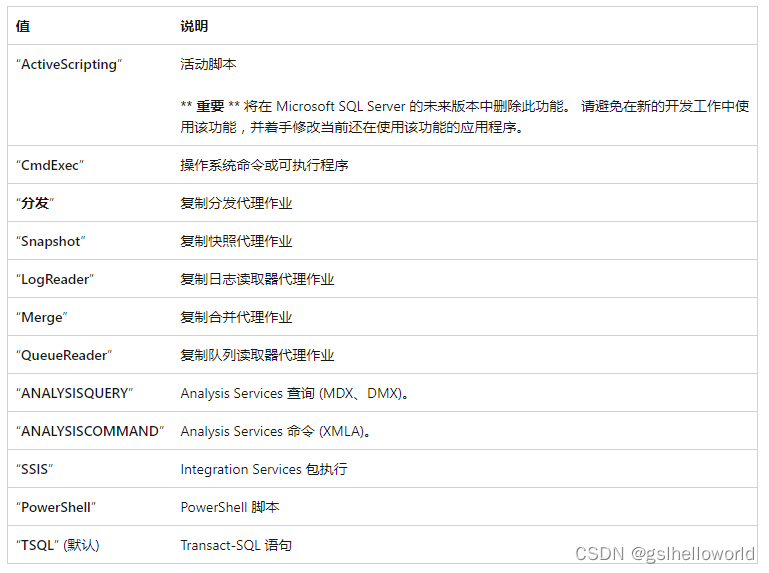
[ @command = ] 'command’通过子系统由 SQLServerAgent 服务执行的命令。 命令 为 nvarchar (max) ,默认值为 NULL。 SQL Server 代理提供标记替换功能;在编写软件程序时,它可提供与变量相同的灵活性。
重要
作业步骤中使用的所有标记现在必须附带转义宏,否则,这些作业步骤将会失败。
此外,您现在还必须用括号将标记名称括起来,并在标记语法开头加上美元符号 ($)。 例如:
$(ESCAPE_宏名称(DATE))
有关这些令牌以及更新作业步骤以使用新令牌语法的详细信息,请参阅 “在作业步骤中使用令牌”。
重要
对 Windows 事件日志拥有写入权限的任何 Windows 用户都可以访问由 SQL Server 代理警报或 WMI
警报激活的作业步骤。 为了防范此安全隐患,默认情况下,可以在由警报激活的作业中使用的特定 SQL Server 代理标记已被禁用。
这些标记包括:A-DBN、A-SVR、A-ERR、A-SEV、A-MSG 和 WMI(属性) 。
请注意,在此版本中,对标记的使用扩展至所有警报。
如果您需要使用这些标记,请首先确保只有可信任的 Windows 安全组(如 Administrators 组)成员才对安装 SQL
Server 的计算机的事件日志拥有写入权限。 然后在对象资源管理器中右键单击“SQL Server
代理”,选择“属性”,并在“警报系统”页上选择“为警报的所有作业响应替换标记”以启用这些标记。
[ @additional_parameters = ] ‘parameters’ 仅用于信息性目的标识。 不支持。 不保证以后的兼容性。 参数 为 ntext,默认值为 NULL。
[ @cmdexec_success_code = ] codeCmdExec 子系统命令返回的值,指示该命令已成功执行。 代码 为 int,默认值为 0。
[ @on_success_action = ] success_action 如果步骤成功,则执行的操作。 success_action 是 tinyint,可以是其中一个值。

[ @on_success_step_id = ] success_step_id 如果步骤成功且 success_action 为 4,则此作业中要执行的步骤的 ID。 success_step_id 为 int,默认值为 0。
[ @on_fail_action = ] fail_action 如果步骤失败,要执行的操作。 fail_action 是 tinyint,可以是其中一个值。

[ @on_fail_step_id = ] fail_step_id 如果步骤失败且 fail_action 为 4,则此作业中要执行的步骤的 ID。 fail_step_id为 int,默认值为 0。
[ @server = ] ‘server’ 仅用于信息性目的标识。 不支持。 不保证以后的兼容性。 服务器 为 nvarchar (30) ,默认值为 NULL。
[ @database_name = ] ‘database’ 要在其中执行 Transact-SQL 步骤的数据库的名称。 数据库 是 sysname,默认值为 NULL,在这种情况下使用 master 数据库。 不允许用方括号 ([ ]) 将名称括起来。 对于 ActiveX 作业步骤, 数据库 是该步骤使用的脚本语言的名称。
[ @database_user_name = ] ‘user’ 执行 Transact-SQL 步骤时要使用的用户帐户的名称。 用户 为 sysname,默认值为 NULL。 当用户为 NULL 时,该步骤在作业所有者的用户上下文中对数据库运行。 只有在作业所有者是 SQL Server sysadmin 时,SQL Server 代理才包括此参数。 如果是这样,则给定的 Transact-SQL 步骤将在给定的 SQL Server 用户名的上下文中执行。 如果作业所有者不是 SQL Server sysadmin,则 Transact-SQL 步骤将始终在拥有此作业的登录名的上下文中执行,并且 @database_user_name 将忽略该参数。
[ @retry_attempts = ] retry_attempts 如果此步骤失败,重试尝试次数。 retry_attempts为 int,默认值为 0,表示没有重试尝试。
[ @retry_interval = ] retry_interval 重试尝试之间的时间(以分钟为单位)。 retry_interval为 int,默认值为 0,表示 0 分钟间隔。
[ @os_run_priority = ] run_priority 保留。
[ @output_file_name = ] ‘file_name’ 保存此步骤输出的文件的名称。 file_name 为 nvarchar (200) ,默认值为 NULL。 file_name 可以包含 命令下列出的一个或多个令牌。 此参数仅在 Transact-SQL、 CmdExec、 PowerShell、Integration Services 或 Analysis Services 子系统上运行的命令有效。
[ @flags = ] flags 控件行为的选项。 标志 为 int,可以是其中一个值。
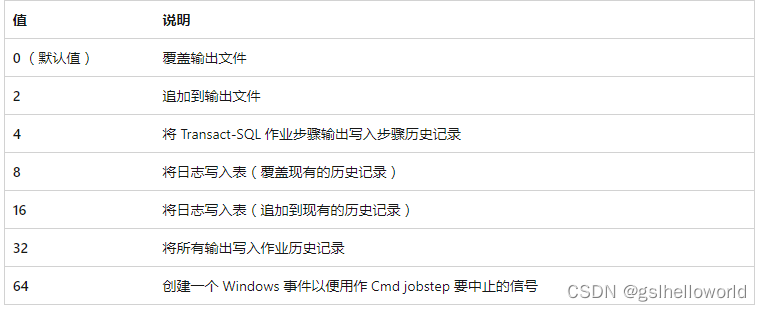
[ @proxy_id = ] proxy_id 作业步骤运行方式的代理的 ID 号。 proxy_id 类型 为 int,默认值为 NULL。 如果未指定 任何proxy_id ,则未指定 任何proxy_name ,并且未指定 任何user_name ,则作业步骤将作为 SQL Server 代理的服务帐户运行。
[ @proxy_name = ] ‘proxy_name’ 作业步骤作为运行方式的代理的名称。 proxy_name 类型为 sysname,默认值为 NULL。 如果未指定 任何proxy_id ,则未指定 任何proxy_name ,并且未指定 任何user_name ,则作业步骤将作为 SQL Server 代理的服务帐户运行。
sp_add_schedule (Transact-SQL)
创建一个可由任意数量的作业使用的计划
sp_add_schedule [ @schedule_name = ] 'schedule_name'
[ , [ @enabled = ] enabled ]
[ , [ @freq_type = ] freq_type ]
[ , [ @freq_interval = ] freq_interval ]
[ , [ @freq_subday_type = ] freq_subday_type ]
[ , [ @freq_subday_interval = ] freq_subday_interval ]
[ , [ @freq_relative_interval = ] freq_relative_interval ]
[ , [ @freq_recurrence_factor = ] freq_recurrence_factor ]
[ , [ @active_start_date = ] active_start_date ]
[ , [ @active_end_date = ] active_end_date ]
[ , [ @active_start_time = ] active_start_time ]
[ , [ @active_end_time = ] active_end_time ]
[ , [ @owner_login_name = ] 'owner_login_name' ]
[ , [ @schedule_uid = ] schedule_uid OUTPUT ]
[ , [ @schedule_id = ] schedule_id OUTPUT ]
[ , [ @originating_server = ] server_name ] /* internal */
参数
[ @schedule_name = ] ‘schedule_name’ 计划的名称。 schedule_name 为 sysname,没有默认值。
[ @enabled = ] enabled 指示计划的当前状态。 enabled 为 tinyint,默认值为 1 (已启用) 。 如果 为 0,则不启用计划。 如果不启用计划,则作业不会按此计划运行。
[ @freq_type = ] freq_type 一个值,该值指示何时执行作业。 freq_type为 int,默认值为 0,可以是以下值之一。
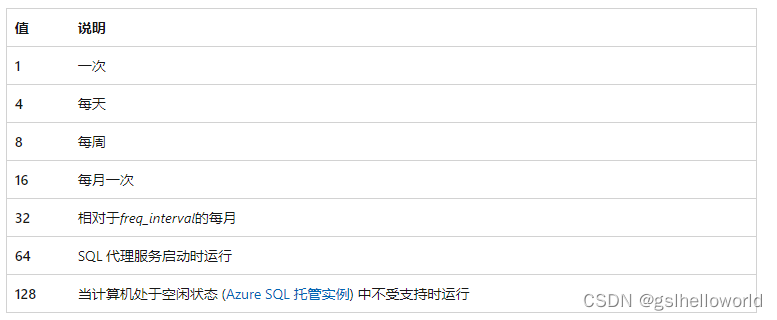
[ @freq_interval = ] freq_interval 执行作业的天数。 freq_interval 为 int,默认值为 1,取决于 freq_type的值。

[ @freq_subday_type = ] freq_subday_type 指定 freq_subday_interval单位。 freq_subday_type为 int,默认值为 0,可以是其中一个值。

[ @freq_subday_interval = ] freq_subday_interval 每个作业执行之间要发生的 freq_subday_type 句点数。 freq_subday_interval为 int,默认值为 0。 注意:间隔应大于 10 秒。 在freq_subday_type等于 1 的情况下,将忽略freq_subday_interval。
[ @freq_relative_interval = ] freq_relative_interval如果freq_interval是每月的 32 (相对) ,则每个月出现freq_interval。 freq_relative_interval为 int,默认值为 0,可以是以下值之一。 freq_relative_interval在freq_type不等于 32 的情况下被忽略。

[ @freq_recurrence_factor = ] freq_recurrence_factor 计划的作业执行之间的周数或月数。 仅当freq_type为 8、16 或 32 时,才会使用freq_recurrence_factor。 freq_recurrence_factor 为 int,默认值为 0。
[ @active_start_date = ] active_start_date 作业执行开始的日期。 active_start_date 为 int,默认值为 NULL,表示今天的日期。 日期的格式为 YYYYMMDD。 如果 active_start_date 不为 NULL,则日期必须大于或等于19900101。
创建了计划后,请检查其开始日期,确认该日期是否正确。 有关详细信息,请参阅 “创建和将计划附加到作业”中的“计划开始日期”部分。
对于每周或每月时间表,如果活动开始日期是在过去,则代理将忽略该日期,改用当前日期。 在使用 sp_add_schedule 创建 SQL 代理计划时,有一个选项可用来指定作为作业执行开始日期的参数 active_start_date。 如果计划类型是每周或每月并且 active_start_date 参数设置为过去中的某个日期,则忽略该 active_start_date 参数并且将当前日期用于 active_start_date。
[ @active_end_date = ] active_end_date 作业执行可以停止的日期。 active_end_date为 int,默认值为 99991231,表示 9999 年 12 月 31 日。 其格式为 YYYYMMDD。
[ @active_start_time = ] active_start_timeactive_start_date和active_end_date开始执行作业的任意一天的时间。 active_start_time 为 int,默认值为 000000,它指示 24 小时 12:00:00 A.M.,必须使用 HHMMSS 格式输入。
[ @active_end_time = ] active_end_time在active_start_date和active_end_date之间的任意一天结束作业执行的时间。 active_end_time 为 int,默认值为 235959,指示下午 24 小时 11:59:59,并且必须使用 HHMMSS 格式输入。
[ @owner_login_name = ] ‘owner_login_name’ 拥有计划的服务器主体的名称。 owner_login_name 为 sysname,默认值为 NULL,表示计划由创建者拥有。
[ @schedule_uid = ] _schedule_uidOUTPUT 计划的唯一标识符。 schedule_uid 是 uniqueidentifier 类型的变量。
[ @schedule_id = ] _schedule_idOUTPUT 计划的标识符。 schedule_id 是 int 类型的变量。
[ @originating_server = ] server_name
标识为仅供参考。 不支持。 不保证以后的兼容性。
sp_attach_schedule (Transact-SQL)
设置一个作业计划
sp_attach_schedule
{ [ @job_id = ] job_id | [ @job_name = ] 'job_name' } ,
{ [ @schedule_id = ] schedule_id
| [ @schedule_name = ] 'schedule_name' }
参数
[ @job_id = ] job_id 计划添加到的作业的作业标识号。 job_iduniqueidentifier,默认值为 NULL。
[ @job_name = ] ‘job_name’ 计划添加到的作业的名称。 job_namesysname,默认值为 NULL。
备注
必须 job_id 或 job_name ,但不能同时指定这两者。
[ @schedule_id = ] schedule_id 要为作业设置的计划的计划标识号。 schedule_id为 int,默认值为 NULL。
[ @schedule_name = ] ‘schedule_name’ 要为作业设置的计划的名称。 schedule_namesysname,默认值为 NULL。
备注
必须 schedule_id 或 schedule_name ,但不能同时指定这两者。
测试
创建测试数据库
USE [master]
GO
CREATE DATABASE [SQLTestDB]
GO
USE [SQLTestDB]
GO
CREATE TABLE SQLTest
(
ID INT NOT NULL PRIMARY KEY,
c1 VARCHAR(100) NOT NULL,
dt1 DATETIME NOT NULL DEFAULT getdate()
);
GO
USE [SQLTestDB]
GO
INSERT INTO SQLTest (ID, c1) VALUES (1, 'test1')
INSERT INTO SQLTest (ID, c1) VALUES (2, 'test2')
INSERT INTO SQLTest (ID, c1) VALUES (3, 'test3')
INSERT INTO SQLTest (ID, c1) VALUES (4, 'test4')
INSERT INTO SQLTest (ID, c1) VALUES (5, 'test5')
GO
SELECT * FROM SQLTest
GO
完整备份到默认位置的磁盘
USE SQLTestDB;
GO
BACKUP DATABASE SQLTestDB
TO DISK = 'f:\tmp\SQLTestDB.bak'
WITH FORMAT,
MEDIANAME = 'SQLServerBackups',
NAME = 'Full Backup of SQLTestDB';
GO