论文题目 :Austere Flash Caching with Deduplication and Compression
来源:USENIX ATC 2020
链接:Austere Flash Caching with Deduplication and Compression | USENIX
一、概念
1、Flashcache
Flashcache开源混合存储方案--原理与安装 - dhb_oschina的个人空间 - OSCHINA - 中文开源技术交流社区

(1)虚拟文件系统(VFS)是由Sun microsystems公司在定义网络文件系统(NFS)时创造的。它是一种用于网络环境的分布式文件系统,是允许和操作系统使用不同的文件系统实现的接口。虚拟文件系统(VFS)是物理文件系统与服务之间的一个接口层,它对Linux的每个文件系统的所有细节进行抽象,使得不同的文件系统在Linux核心以及系统中运行的其他进程看来,都是相同的。严格说来,VFS并不是一种实际的文件系统。它只存在于内存中,不存在于任何外存空间。VFS在系统启动时建立,在系统关闭时消亡。
(2)块层:块层介绍 第一篇: bio层
(3)DM层:
(4)设备驱动:【哈工大李治军】操作系统课程笔记9:设备驱动与文件管理(显示器、键盘和磁盘)_辰阳星宇的博客-CSDN博客_李治军哈工大
***flashcache 断电丢失数据 flash断电不丢失数据
deduplication(去重)
重复数据删除以粗粒度但轻量级的方式删除块级重复数据。通过将数据划分成一个个chunk(KB级别),对每个chunk的内容做hash,若算出的hash值(fingerprint,FP)一样(不同),则视为冗余(唯一)数据。通过在物理空间上(SSD上)只保存一份冗余数据的副本,从而进行数据缩减,但在逻辑空间上,所有冗余数据不会被删除,而是都指向同一块物理地址。此外还会将每个chunk和其FP的映射存储下来,用于重复检查和chunk查找。块(chunk)的大小可能是固定也可能是变化的,本文主要关注去重固定大小的块。
compression(压缩)
压缩通过将数据转换为更紧凑的形式,旨在字节级进行细粒度的数据减少。压缩通常在去重后进行,一般应用于那些唯一数据块。压缩后的数据块大小一般是可变的。本文使用顺序压缩算法(例如Ziv-Lempel算法),对每个块的字节进行操作。
deduplication&compression是两种data eduction技术,相辅相成。
flash
flash存储器又称闪存,它结合了ROM和RAM的长处,不仅具备电子可擦除可编程(EEPROM)的性能,还可以快速读取数据(NVRAM的优势),使数据不会因为断电而丢失。固态硬盘和传统的机械硬盘最大的区别就是不再采用盘片进行数据存储,而采用存储芯片进行数据存储。固态硬盘的存储芯片主要分为两种:一种是采用闪存作为存储介质的;另一种是采用DRAM作为存储介质的。目前使用较多的主要是采用闪存作为存储介质的固态硬盘
flashcache
Flashcache是Facebook技术团队的一个开源项目,最初目的是为加速MySQL的数据库引擎InnoDB,是一个开源的混合存储方案,兼顾了机械硬盘和固态硬盘两者的优点,即有HHD的高容量、高顺序访问,也有SSD的高随机访问,低延迟,且这个方案成本也相对较低。Flashcache利用了Linux的device mapping机制,将Flash disk和普通硬盘的块设备做了一层映射,在OS中变现为一块普通的磁盘,使用简单。通过在文件系统和设备驱动之间新增了一层缓存层,用来实现对热点数据的缓存。通常用SSD固态硬盘作为缓存,通过将传统硬盘上的热门数据缓存到SSD上,然后利用SSD优秀的读性能,来加速系统。参考https://my.oschina.net/u/658505/blog/544599

上图是一般的带有去重和压缩功能的flashcache架构。带有去重和压缩功能的flashcache保证SSD中的数据块都是唯一且压缩过的。而传统的flashcache不带有去重和压缩功能,因此只用维护一种索引结构:LBA->CA。经过假设计算后,带有去重和压缩的flashcache由于要维护两个index(LBA-index、FP-index),其内存开销要是传统的flashcache的16倍(4G/256MB)。此外还可能产生额外的CPU开销(计算FP、压缩数据、寻找索引对等)
LBA-index:LBA->FP
逻辑地址索引,即将存于HDD中的数据的逻辑地址(LBA)与数据块的FP值进行映射(多对一,可能有多个不同的逻辑地址指向相同内容的数据)
FP-index:FP->CA,length
FP索引,即将每个数据块的FP值与该数据块经过压缩后位于SSD中的物理地址(CA)以及该块的大小进行映射(一对一)
Write-through(直写模式)
在数据更新时,同时写入缓存Cache和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢
Write-back(回写模式)
在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
其他
任何哈希冲突只会导致缓存丢失而不会丢失数据
二、解决问题
提高Flashcache的空间效率和耐久性;重删和压缩为索引管理带来了大量的内存开销;探索如何通过重复数据删除和压缩来增强传统的闪存缓存,以实现存储和I/O节省,从而解决固态硬盘容量有限和损耗问题。
【有关 SSD 磨损原因的信息:硬盘 — 为什么固态设备 (SSD) 磨损 | Dell 中国】
AustereCache,这是一种新的Flash缓存设计,旨在实现内存高效索引,同时保留重复数据删除和压缩的数据减少优势。
AustereCache原型节省了69.9%-97.0%的内存使用,同时保持了可比的读命中率和写减少率,并实现了高I/O吞吐量。
三、核心技术
AustereCache强调严格的cache数据管理,使用多种技术来进行有效的数据组织和cache数据替换,主要包括三个核心技术点:
3.1 bucketization(桶化)
如下图所示,为了消除在LBA-index和FP-index中维护地址映射的内存开销,AustereCache将索引项散列到大小相等的分区(称为桶,每个桶分为多个槽)中,每个桶保存部分LBA和FP(通过hash后取其前缀码,如前16bit)以节省内存。根据桶位置,将数据块映射到SSD中。并将SSD分为元数据区(metadata)和数据区(chunk data),这两个区也都被分为多个桶,每个桶包含多个槽(slot),数量与FP-index保持一致(1对1映射)。

3.2固定大小压缩数据管理
为了避免在FP-index中跟踪块的长度,AustereCache将可变大小的压缩块划分为较小的固定大小的子块,并在不记录压缩块长度的情况下管理子块。如下图所示,在FP-index中会选取多个连续的槽来存放属于同一个压缩块的子块,并且不会在FP-index中记录压缩块的大小,而是在SSD中记录压缩块的大小,从而减小FP-index大小,减小内存开销。这样做既可以很好的使用桶—槽(bucket—slot)机制来管理每个数据块(将大小变化的压缩块分为多个固定大小的子块),也可以节省内存开销。

有压缩的读/写工作流与无压缩的读/写工作流类似(§3.1)??
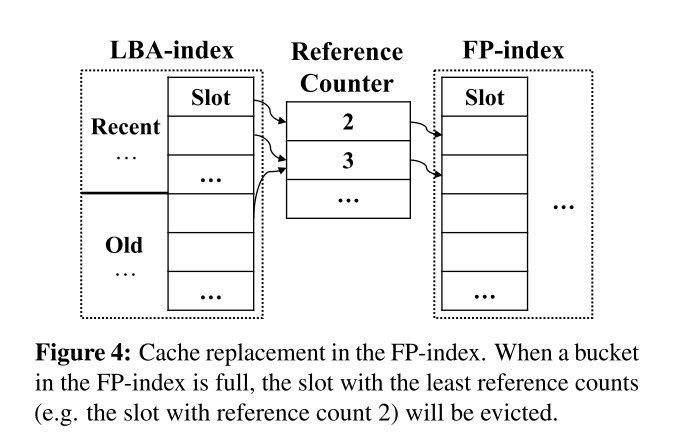
3.3 基于bucket的缓存替换
AustereCache为了增加缓存命中的可能性,其结合了基于引用计数(即引用每个唯一块的重复副本的计数)的最近性和去重性原则,以实现有效的SSD缓存数据替换。但是,记录引用计数会产生不可忽略的内存开销。因此,AustereCache利用固定大小的紧凑型草图数据结构在有限的内存空间中使用有限的误差进行参考计数估计。
对于LBA-index,其替换策略为LRU,每当新加入或者新访问一个LBA就会将这个LBA移动到最前面(偏移量为0),其余所有entry往后移动一格,处于最后一个的entry(偏移量最大)会被替换掉。
对于FP-index,其替换策略是要将去重(deduplication)和最近访问性(recency,相当于局部性原理)结合起来,通过一个额外的数据结构:引用计数(count)来表明冗余LBA的程度,当FP-index满后,会替换掉count最小的entry来满足去重性。此外还通过将LBA-index分为Recent、Old两个区,位于Recent区中的entry,每次被访问,或者新加入的entry,其count+2;当从Recent进入Old,或者在Old中被替换掉的entry,其count-1;当Old中的entry被访问进入Recent区,其count+1。通过这种规则既兼顾了去重也兼顾了局部性原理。
总结
为什么要用固定块大小的重删而不是cdc;
全篇没有考虑时间,都是空间
问题及其重要性:
目前SSD被广泛用作RAM和HDD之间的一个缓存层(即flashcache技术,通过将热点数据存储在SSD,可以提高整体I/O性能),但可用容量很小,而且由于磨损问题,续航能力也很差。
我们探索重复数据删除和压缩作为数据减少技术,以消除I/O路径上的重复内容,从而降低存储和I/O成本。
尽管有减少数据的好处,但是现有的将重复数据删除和压缩应用于闪存缓存的方法[24,26,37]不可避免地由于昂贵的索引管理而招致大量的内存开销。
现阶段的研究现状:
特别地,最近的研究[24,26,37]用重复数据删除和压缩来增强闪存缓存,重点是在大的替换单元中管理可变大小的缓存数据[24]或设计新的缓存替换算法[26,37]。
论文新的发现和解决思路、
我们提出了一种Flashcache设计AustereCache,它使用重复数据删除和压缩来节省存储和I/O,同时大大降低了类似设计中索引结构的内存开销。
AustereCache提倡在数据布局和缓存替换策略上进行严格的缓存管理,以限制由于重复数据删除和压缩而导致的内存放大。 它建立在三个核心技术之上:㈠Bucketization,它通过确定地将块映射到固定大小的桶中来实现轻量级地址映射; ㈡固定大小的压缩数据管理,通过将可变大小的压缩块组织为固定大小的子块,避免跟踪内存中的块长度; 以及(iii)基于桶的高速缓存替换,其在每个桶的基础上执行存储器有效的高速缓存替换,并利用紧凑的草图数据结构[13]来跟踪有限存储器空间中的重复数据删除和最近模式,以用于高速缓存替换决策。
主要结论、
与CachedEdup[26]相比,AustereCache使用的内存比CachedEdup少69.9-97.0%,同时保持了可比的读命中率和写减少率(即,通过以重复数据删除和压缩为后盾的Flash缓存,它保持了I/O性能的提高)。 此外,AustereCache在I/O路径上引入了有限的CPU开销,并且可以通过多线程进一步提高I/O吞吐量。
存在的问题和你自己的思考。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)