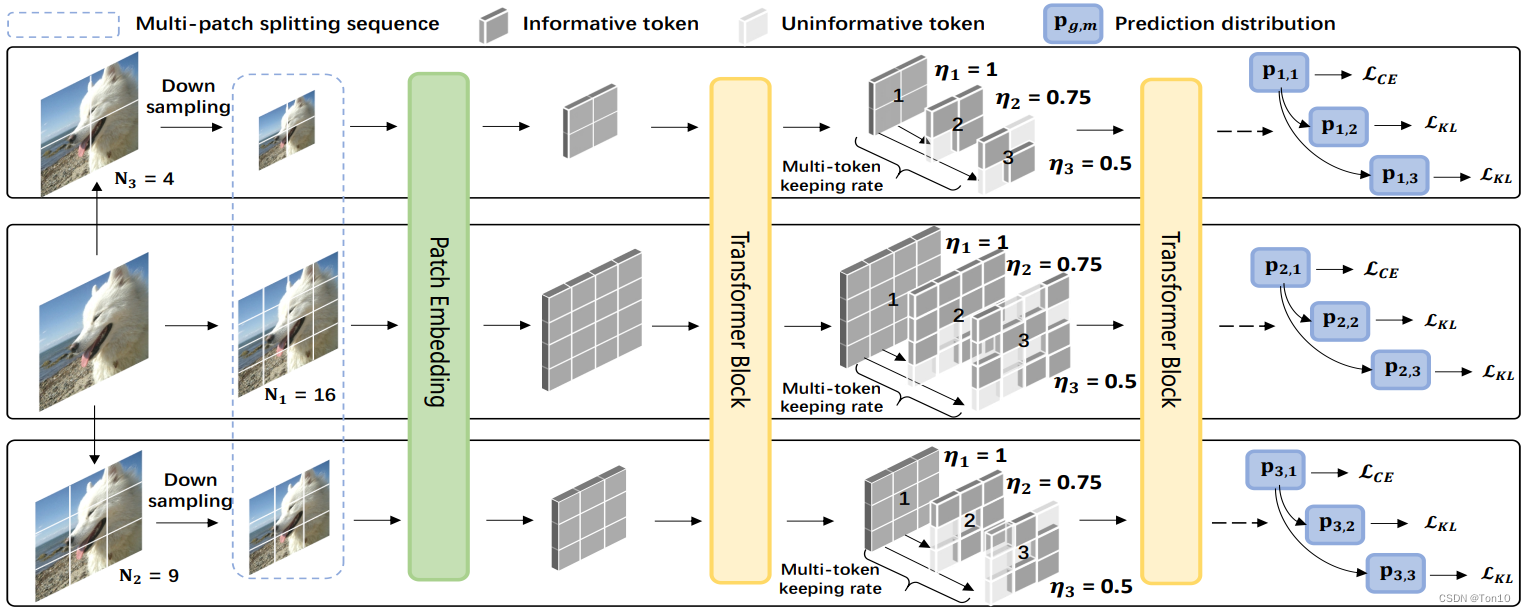
这篇文章是今年发表的一篇Transformer类文章。文章作者提出了ViT的增强版——SuperViT,其核心有2个:①多尺度输入;②Token-keeping-rate机制。作者通过一系列实验证明SuperViT可以在计算效率和正确率上实现比Swin-T更好的表现力!
参考文档:
①源码
②Transformer学习(四)—DeiT
③各类Transformer都得稍逊一筹,LV-ViT:探索多个用于提升ViT性能的高效Trick
Super Vision Transformer
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Methodology
-
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)