摘要
对比学习在无监督图表示学习中取得了很好的效果,大部分图对比学习首先对输入图做随机增强生成两个视图然后最大化两个视图表示的一致性。其中,图上的增强方式是非常重要的部分鲜有人探索。我们认为数据增强模式应该保留图固有的属性和结构,可以使模型学到对于不重要的结点和边扰动不敏感的表示信息。但目前的方法大多采用均质的增强方法如均匀的去边,或扰动特征,只能达到次优效果。本文借助先验信息从拓扑和语义角度引入自适应的增强策略。具体来说,在拓扑角度,采用基于结点的中心性来衡量连接结构的重要性的方式设计增强模式;在特征维度,给不重要的结点特征加入更多噪声来扰动结点特征,强化模型识别潜在语义信息。
引言
之前的增强方式主要有两个缺点。首先,在结构或者特征角度的简单增强不足以生成多样的邻居,很难在对比目标函数中优化;其二是之前的工作了结点和边影响的差异性。比如均匀的丢弃边的化,一些重要的边丢弃会恶化结果。如果在边移除的增强方式中,给重要的边小的概率,不重要的边大的概率,在学习时可以使模型自适应的忽略噪声和不重要的边,学到重要的模式。
本文设计了一个自适应增强的图对比学习方法,首先通过随机扰动生成两个相关的视图,然后最大化这两个视图上结点表示的互信息。我们设计了一个联合的,自适应的数据增强模式,通过分别在拓扑级移除边和在结点属性角度做特征遮掩来为结点在不同视图提供多样的上下文信息,优化对比目标。

模型
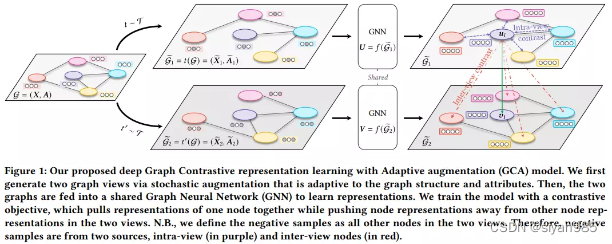
GCA按照常规图对比学习的模式,最大化不同视图表示的一致性。对于每一个结点i,所有视图中该结点的表示作为正样本,其他结点的表示视作负样本。借鉴InfoNCE,在多视图图对比学习中,对于每对正样本(ui, vi)我们定义对级目标函数为
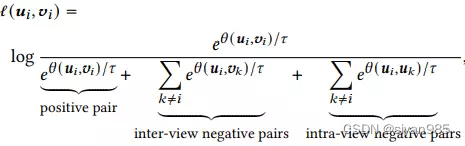
θ(u,v)=s(g(u), g(v)),其中s(., .)为余弦相似度,g(.)是一个非线性映射映射提升判别函数表达能力,我们采用两层感知机实现。在所有视图中,其他结点都可以视作负样本。因此,来自两个视图即inter-view和intra-view。由于两个视图是对称的,因此最终的目标函数定义为所有正样本对的平均值即
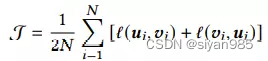
这个训练算法总结如下

Adaptive Graph Augmentation
对比学习希望学到扰动无关的信息,而在GCA中,期望学到重要的结构和 不变的特征。在扰动中,给不重要的结点或特征赋值较高的丢弃率或者遮盖率,我们在随机扰动的视图上强调重要的结构和属性,使模型保留基础的拓扑和语义模式。
1)Topology-level augmentation
在拓扑上的增强中,通过直接对输入的图随机丢弃一些边来增强。具体来说就是按照一定的概率从边集E中采样一个子集E’
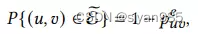
Puv表示移除的概率,E’为生成视图的边集。其中,Puv反映边(u,v)的重要程度,增强函数会丢弃不重要的边同时在增强视图中保留重要的连接结构。
结点中心性是常用的度量结点重要性的方法,我们使用边两端的结点的中心性来衡量边的中心性。在给定结点的中心性的衡量方法f(.)后,边的中心性定义为两个邻接结点中心性值的平均即Wuv=(f(u) + f(v))/2。在有向图中,直接用尾结点的中心性表示边的中心性。
在得到边的中心性后,通过转化可以得到边对应的概率。由于结点有不同阶数的连接强度,因此需要归一化操作。其中Pe,Pt都是超参,分别控制边的移除概率和整体的丢弃比例,丢弃太多会过度扰动图结构。
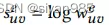
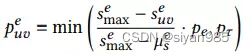
2)Node-atttibute-level augmentation
类似于图像处理中的椒盐噪声,我们通过用0随机遮掩一部分结点特征来给结点添加噪声。具体来说,首先采样一个随机向量m,他的每个维度独立且服从伯努利分布。然后生成的结点特征为
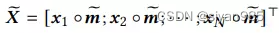
类似于拓扑级的增强,pfi应该反映结点特征第i个维度的重要性。我们假设,在重要的结点中频繁出现的特征维度应该是重要的,并按照如下方式定义特征维度i的权重。
对于任意结点u,结点特征为稀疏one-hot编码,第i维特征的权重计算如下
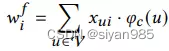
其中第一项Xui是二值的,表示第i为特征是否在结点u中出现;第二项表示结点的中心性,衡量每个出现的特征的重要程度。直观的解释,在引用网络中,结点的每个维度的特征表示 一个关键字。在重要的文章中出现频繁的关键字应该是重要的。
对于结点特征为稠密,连续的情况时,Xui表示第i个维度的特征值。由于我们无法记录每个one-hot编码值的出现次数,因此我们转向度量第i个维度特征值的大小。通过特征值的绝对值计算权重
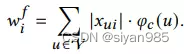
最后,类似于拓扑结构的增强,我们使用标准化操作计算特征重要性的概率
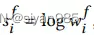
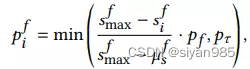
GCA中的每个视图都是在拓扑结构和结点特征两个空间联合做增强得到的。GCA会生成两个视图为对比学习提供多样的上下文环境。
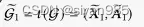
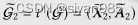
其中,两个视图的概率分别表示为
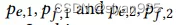
注意,所有的中心性和权重都是在原始输入图中计算的。
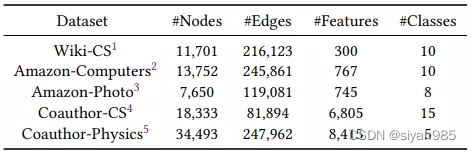
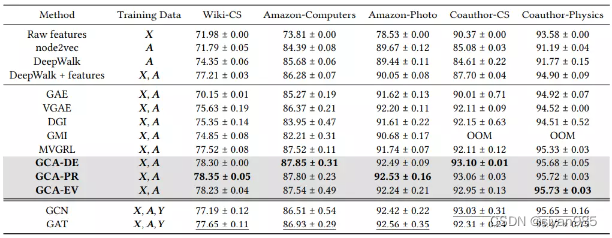
实验

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)