从0到1用PyG创建异构图
- 异构图
- 创建异构图
- 电影评分数据集MovieLens
- 建立二分图数据集
- 转换为可训练的数据集
- 建立异构图神经网络
- 以OGB数据集为例
- HeteroData中常用的函数
- 将简单图神经网络转换为异质图神经网络
- GraphGym的使用
- PyG中常用的卷积层
- 参考资料
在现实中需要对
多种类型的节点以及这些
节点之间多种类型的边进行处理,这就需要
异构图的概念,在异构图中,
不同类型的边描述不同类型节点之间
不同的关系,
异构图神经网络的任务就是在这种图结构上学习出节点或者整个异构图的特征表示。
异构图
异构图的准确定义如下:异构图(Heterogeneous Graphs):一个异构图
G
G
G有一组节点
V
=
v
1
,
v
2
,
.
.
.
,
v
n
V=v_1,v_2,...,v_n
V=v1,v2,...,vn和一组边
E
=
e
1
,
e
2
,
.
.
.
,
e
m
E=e_1,e_2,...,e_m
E=e1,e2,...,em组成,其中每个节点和每条边都对应着一种类型,用
T
v
T_v
Tv表示节点类型的集合,
T
e
T_e
Te表示边类型的集合,一个异构图有两个映射函数,分别将每个节点映射到其对应的类型
ϕ
v
:
V
→
T
v
\phi_v:V\rightarrow T_v
ϕv:V→Tv,每条边映射到其对应的类型:
ϕ
e
:
E
→
T
e
\phi_e:E\rightarrow T_e
ϕe:E→Te。
创建异构图
电影评分数据集MovieLens
这里以一个电影评分数据集MovieLens为例,逐行示例如何创建异构图。MovieLens包含了600个用户对于电影的评分,利用这个数据集构建一个二分图,包含电影、用户两种类型的节点,一种类型的边(含有多种类型节点,所以可以看作一个异质图)。
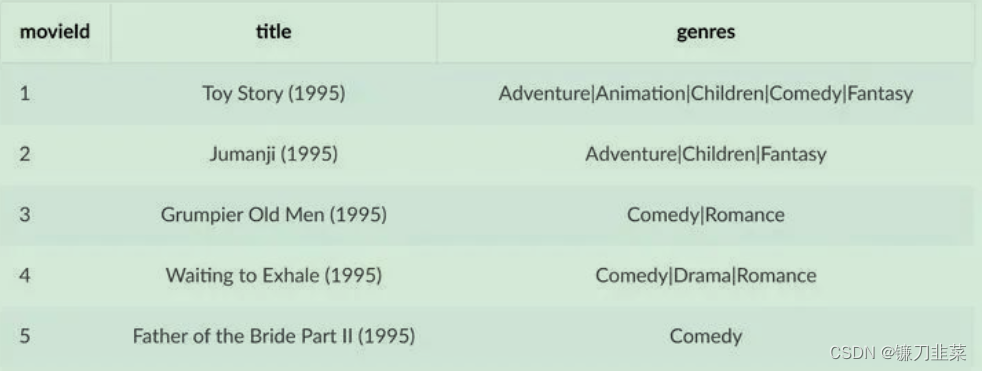
- MovieLens中的
movies.csv文件描述了电影的信息,包括电影在数据集中唯一的ID,电影名,电影所属的类型:
- MovieLens中的ratings.csv包含了用户对于电影的评分:

建立二分图数据集
首先下载一个Python库:sentence_transformers。SentenceTransformers 是一个可以用于句子、文本和图像嵌入的Python库。 可以为 100 多种语言计算文本的嵌入并且可以轻松地将它们用于语义文本相似性、语义搜索和同义词挖掘等常见任务。该框架基于 PyTorch 和 Transformers,并提供了大量针对各种任务的预训练模型。 还可以很容易根据自己的模型进行微调。
pip install -U sentence-transformers
首先,导入依赖库:
import os.path as osp
import torch
import pandas as pd
from sentence_transformers import SentenceTransformer
from torch_geometric.data import HeteroData, download_url, extract_zip
from torch_geometric.transforms import ToUndirected, RandomLinkSplit
然后,设定数据集:
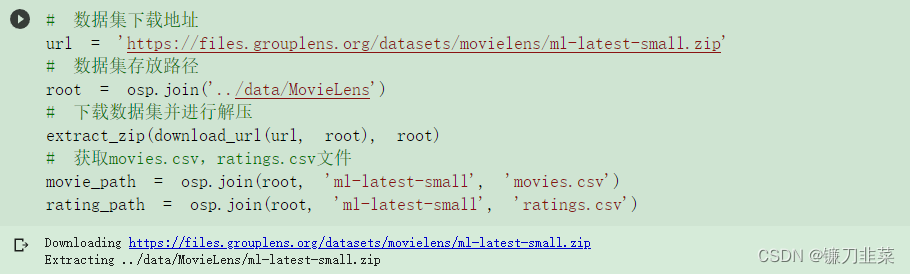
利用Pandas查看数据集
(1)利用嵌入模型将每个电影名用向量表示(Embedding)
class SequenceEncoder(object):
def __init__(self, model_name='all-MiniLM-L6-v2', device=None):
self.device = device
self.model = SentenceTransformer(model_name, device=device)
@torch.no_grad()
def __call__(self, df):
x = self.model.encode(
df.values,
show_progress_bar=True,
convert_to_tensor=True,
device=self.device
)
return x.cpu()
(2)将电影类型也进行嵌入表示
class GenresEncoder(object):
def __init__(self, sep="|"):
self.sep = sep
def __call__(self, df):
genres = set(g for col in df.values for g in col.split(self.sep))
mapping = {genre: i for i, genre in enumerate(genres)}
x = torch.zeros(len(df), len(mapping))
for i, col in enumerate(df.values):
for genre in col.split(self.sep):
x[i, mapping[genre]]=1
return x
(3)从CSV文件中读取信息,建立二分图中的节点信息
def load_node_csv(path, index_col, encoders=None, **kwargs):
"""
:param path: CSV文件路径
:param index_col: 文件中的索引列,也就是节点所在的列
:param encoders: 节点嵌入器
:param kwargs
:return:
"""
df = pd.read_csv(path, index_col=index_col, **kwargs)
mapping = {index: i for i, index in enumerate(df.index.unique())}
x = None
if encoders is not None:
xs = [encoder(df[col]) for col, encoder in encoders.items()]
x = torch.cat(xs, dim=-1)
return x, mapping
(4)获取节点信息
movie_x, movie_mapping = load_node_csv(movie_path, index_col = 'movieId', encoders = {'title':SequenceEncoder(),'genres':GenresEncoder()})
user_x, user_mapping = load_node_csv(rating_path, index_col='userId')
data = HeteroData()
data['user'].num_nodes = len(user_mapping)
data['movie'].x = movie_x
print(data)

(5)建立用户和电影之间的边的信息
class IdentityEncoder(object):
def __init__(self, dtype=None):
self.dtype = dtype
def __call__(self, df):
return torch.from_numpy(df.values).view(-1, 1).to(self.dtype)
(6)建立二分图边的连接信息
def load_edge_csv(path, src_index_col, src_mapping, dst_index_col, dst_mapping, encoders=None, **kwargs):
"""
:param path: CSV表的路径
:param src_index_col: 二分图左边节点来源于CSV表的哪一列,比如'user_id'这列
:param src_mapping:将user_id映射为节点编号,我们前面定义的user_mapping
:param dst_index_col:同理,二分图右边电影节点
:param dst_mapping:
:param encoders:边的嵌入器
:param kwargs:
:return:
"""
df = pd.read_csv(path, **kwargs)
src = [src_mapping[index] for index in df[src_index_col]]
dst = [dst_mapping[index] for index in df[dst_index_col]]
edge_index = torch.tensor([src, dst])
edge_attr = None
if encoders is not None:
edge_attrs = [encoder(df[col]) for col, encoder in encoders.items()]
edge_attr = torch.cat(edge_attrs, dim=-1)
return edge_index, edge_attr
(7)获取二分图边的信息
edge_index, edge_label = load_edge_csv(
rating_path,
src_index_col='userId',
src_mapping=user_mapping,
dst_index_col='movieId',
dst_mapping=movie_mapping,
encoders={'rating': IdentityEncoder(dtype=torch.long)}
)
(8)将二分图中的边命名为(‘user’, ‘rates’, ‘movie’)

到此,我们的异构图数据集,实际上是一个二分图,就构建完毕了。下面还要将其转换为一个可以进行训练的数据集
转换为可训练的数据集
这里,我们将构建的异构图数据集转换为一个可训练的无向图数据集。
(1)转换为无向图,同时删除相反方向边的属性信息
data = ToUndirected()(data)
del data['movie', 'rev_rates', 'user'].edge_label
(2)按照比例分割数据集为训练集、测试集、验证集
transform = RandomLinkSplit(
num_val=0.05,
num_test=0.1,
neg_sampling_ratio = 0.0,
edge_types=[('user', 'rates', 'movie')],
rev_edge_types=[('movie', 'rev_rates', 'user')],
)
train_data, val_data, test_data = transform(data)
print(train_data)
print(val_data)
print(test_data)

至此,一个可训练的数据集已经构建完毕。
建立异构图神经网络
以OGB数据集为例
在OGB数据集中包含4种类型的节点:author、paper、institution、field of study;4种类型的边:
- writes:author和paper之间的连接关系
- affiliated with:author和institution之间的连接关系
- cites:paper和paper之间的关系
- has topic:paper和field of study之间的关系
OGB数据集上的任务是预测论文在整个关系网中所属的位置。下面代码示例如何表示这个异质图:
from torch_geometric.data import HeteroData
data = HeteroData()
data['paper'].x = ...
data['author'].x = ...
data['institution'].x = ...
data['field_of_study'].x = ...
data['paper', 'cites', 'paper'].edge_index = ...
data['author', 'writes', 'paper'].edge_index = ...
data['author', 'affiliated_with', 'institution'].edge_index = ...
data['paper', 'has_topic', 'field_of_study'].edge_index = ...
data['paper', 'cites', 'paper'].edge_attr = ...
data['author', 'writes', 'paper'].edge_attr = ...
data['author', 'affiliated_with', 'institution'].edge_attr = ...
data['paper', 'has_topic', 'field_of_study'].edge_attr = ...
这样上面的异质图就建立完成了,我们可以将它输入到一个异质图神经网络中:
model = HeteroGNN(...)
output = model(data.x_dict, data.edge_index_dict, data.edge_attr_dict)
如果PyG中包含你想用的异质图,可以直接这样导入:
from torch_geometric.datasets import OGB_MAG
dataset = OGB_MAG(root='./data', preprocess='metapath2vec')
data = dataset[0]
这样上面的异质图就建立完成了,我们可以将它输入到一个异质图神经网络中
HeteroData中常用的函数
下面介绍一下HeteroData中常用的函数:
paper_node_data=data['paper']
cites_edge_data=data['paper','cites','paper']
- 如果边的连接节点集合或者边的命名是唯一的,还可以这样写
cites_edge_data=data['paper','paper']
cites_edge_data=data['cites']
data['paper'].year=...
def data['field_of_study']
node_types,edge_types=data.metadata()
print(node_types)
print(edge_types)
print(data.has_isolated_nodes())
- 如果不同类型信息之间维度匹配,还可以将异质图融合为一个简单图
homogeneous_data=data.to_homogeneous()
import torch_geometric.transforms as T
data=T.ToUndirected()(data)
data=T.AddSelfLoops()(data)
将简单图神经网络转换为异质图神经网络
PyG可以通过torch_geometric.nn.to_hetero(),或者torch_geometric.nn.to_hetero_with_bases()将一个简单图神经网络转换成异质图的形式。
import torch_geometric.transforms as T
from torch_geometric.datasets import OGB_MAG
from torch_geometric.nn import SAGEConv, to_hetero
dataset = OGB_MAG(root='./data', preprocess='metapath2vec', transform=T.ToUndirected())
data = dataset[0]
class GNN(torch.nn.Module):
def __init__(self, hidden_channels, out_channels):
super().__init__()
self.conv1 = SAGEConv((-1, -1), hidden_channels)
self.conv2 = SAGEConv((-1, -1), out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index).relu()
x = self.conv2(x, edge_index)
return x
model = GNN(hidden_channels=64, out_channels=dataset.num_classes)
model = to_hetero(model, data.metadata(), aggr='sum')
PyG的to_hetero具体工作方式是这样的:
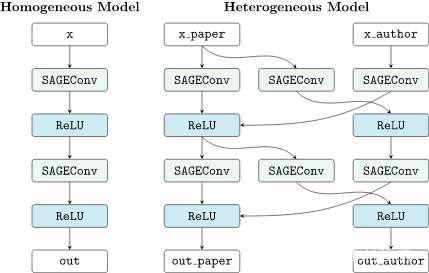
它根据我们的异质图数据结构,自动将我们定义的简单图神经网络结构中的层结构进行了复制,并添加了信息传递路径。
然后,创建的模型可以像往常一样进行训练:
def train():
model.train()
optimizer.zero_grad()
out = model(data.x_dict, data.edge_index_dict)
mask = data['paper'].train_mask
loss = F.cross_entropy(out['paper'][mask], data['paper'].y[mask])
loss.backward()
optimizer.step()
return float(loss)
异构卷积包装器torch_geometry.nn.conv.HeteroConv允许定义自定义异构消息和更新函数,以从头开始为异构图构建任意MP-GNN。虽然to_hetero()的自动转换器对所有边类型使用相同的运算符,但包装器允许为不同的边类型定义不同的运算符。在这里,HeteroConv将子模块的字典作为输入,图数据中的每个边缘类型都有一个子模块。以下示例显示了如何应用它。
import torch_geometric.transforms as T
from torch_geometric.datasets import OGB_MAG
from torch_geometric.nn import HeteroConv, GCNConv, SAGEConv, GATConv, Linear
dataset = OGB_MAG(root='./data', preprocess='metapath2vec', transform=T.ToUndirected())
data = dataset[0]
class HeteroGNN(torch.nn.Module):
def __init__(self, hidden_channels, out_channels, num_layers):
super().__init__()
self.convs = torch.nn.ModuleList()
for _ in range(num_layers):
conv = HeteroConv({
('paper', 'cites', 'paper'): GCNConv(-1, hidden_channels),
('author', 'writes', 'paper'): SAGEConv((-1, -1), hidden_channels),
('paper', 'rev_writes', 'author'): GATConv((-1, -1), hidden_channels,add_self_loops=False),
}, aggr='sum')
self.convs.append(conv)
self.lin = Linear(hidden_channels, out_channels)
def forward(self, x_dict, edge_index_dict):
for conv in self.convs:
x_dict = conv(x_dict, edge_index_dict)
x_dict = {key: x.relu() for key, x in x_dict.items()}
return self.lin(x_dict['author'])
model = HeteroGNN(hidden_channels=64, out_channels=dataset.num_classes,
num_layers=2)
我们可以通过调用一次来初始化模型(有关延迟初始化的更多详细信息,请参阅此处)
with torch.no_grad():
out = model(data.x_dict, data.edge_index_dict)
GraphGym的使用
PyG 2.0 现在通过 torch_geometric.graphgym 正式支持 GraphGym。总的来说,GraphGym 是一个平台,用于通过高度模块化的 pipeline 从配置文件中设计和评估图神经网络:
- GraphGym 是开始学习标准化 GNN 实现和评估的最佳平台;
- GraphGym 提供了一个简单的接口来并行尝试数千个 GNN 架构,以找到适合特定任务的最佳设计;
- GraphGym 可轻松进行超参数搜索并可视化哪些设计选择更好。

对于GraphGym更多资料,参考https://pytorch-geometric.readthedocs.io/en/latest/modules/graphgym.html
PyG中常用的卷积层
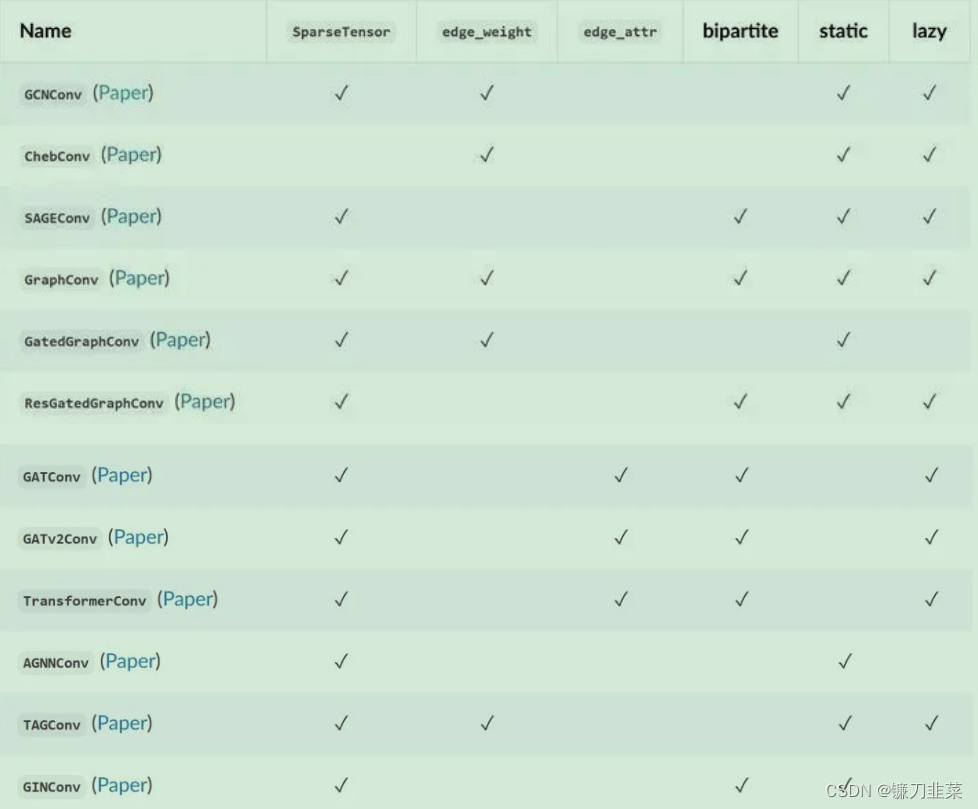
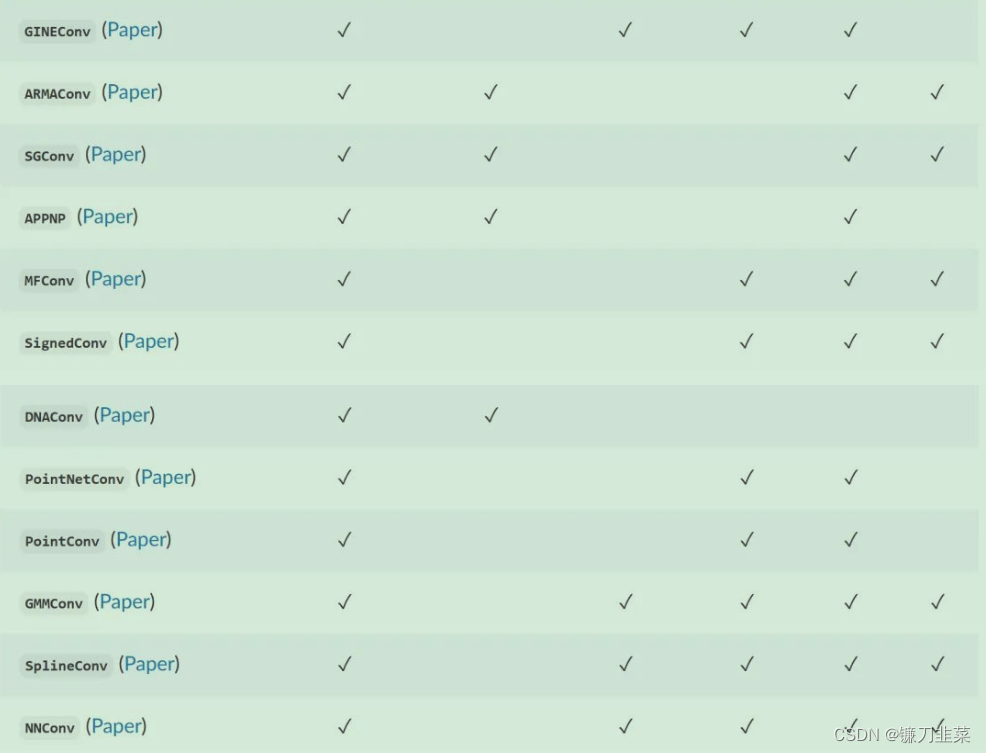
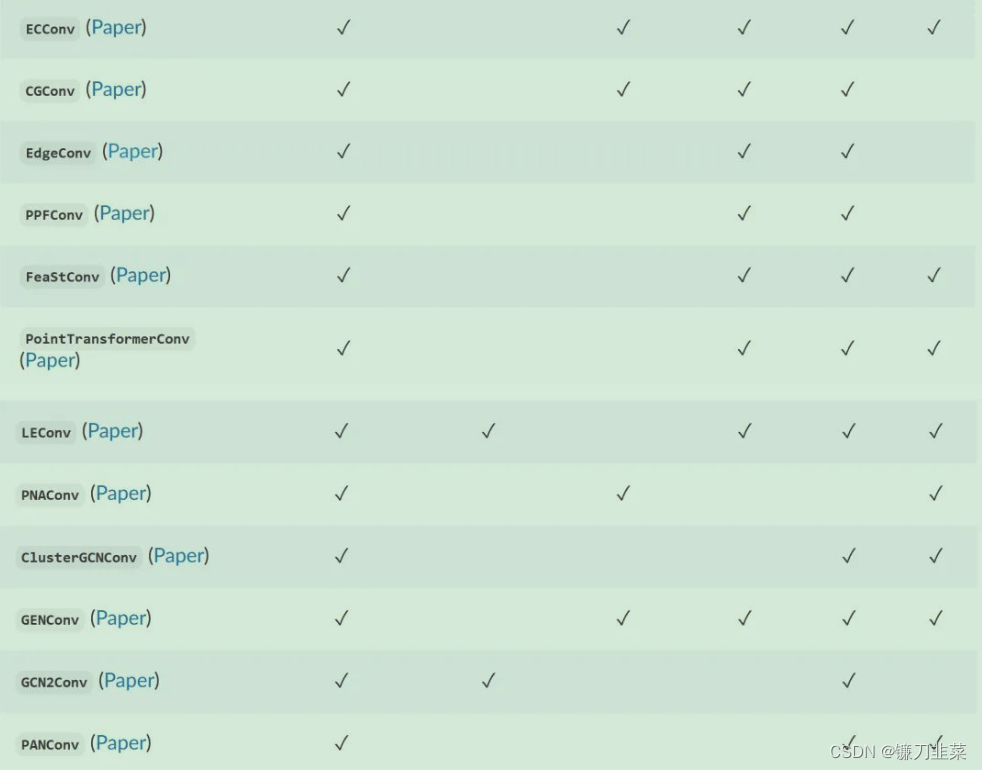
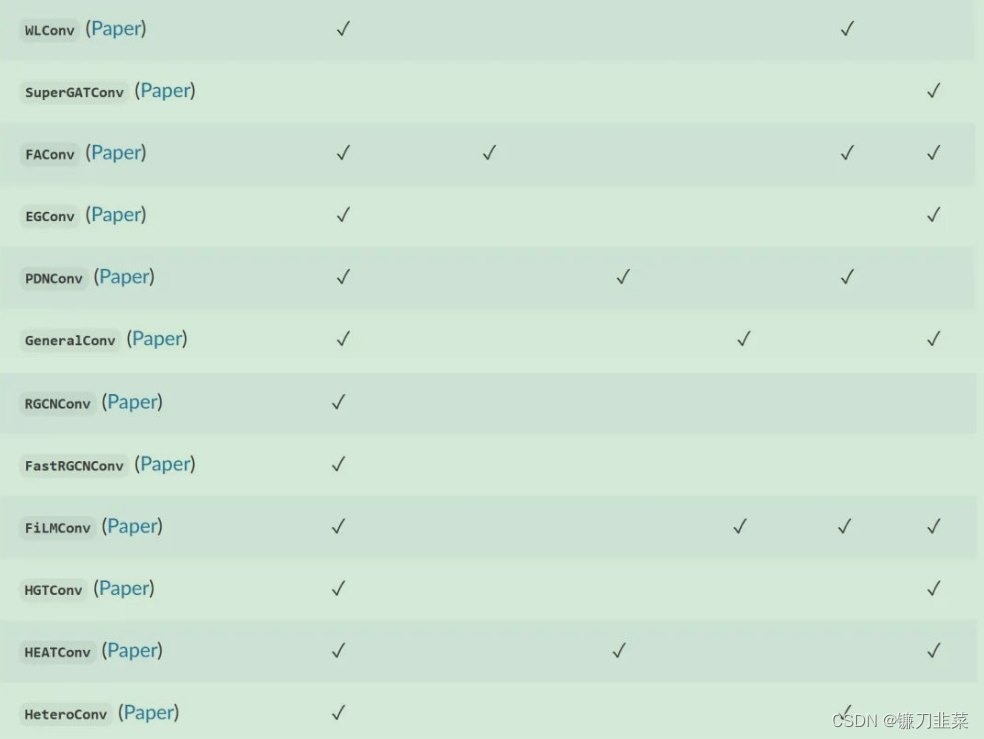

参考资料
- PyG创建自定义异构图Heterogeneous Graphs数据集
- Pytorch图神经网络库——PyG创建自己的数据集
- Pytorch图神经网络库——PyG异构图学习
- 异质图的建立
- 《图深度学习》 马耀、汤继良著
- SentenceTransformers 库介绍
- GraphGym
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)