想要降低dataframe的内存占用主要有两种方法:
- 使用小一点的数值型 datatype
- 把
object类型的列转为categorical类型
df = pd.DataFrame({"col_1":[x for x in range(0, 21)],
"col_2":['even' if val%2==0 else 'odd' for val in range(0, 21)]})
df
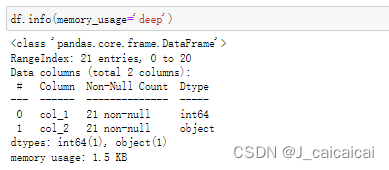
df.info(memory_usage='deep')
可以看到原始memory usage是 1.5KB
1. 把数值字段的datatype换成一个更小的数据类型
但是要注意这些数据的最大值和最小值,确保他们都在这个更小的数据类型的能保留的数据范围之内
| datatype | 数值范围 |
|---|
int8 | -128 ~ 127 |
int16 | -32768 ~ 32767 |
int64 | -9223372036854775808 ~ 9223372036854775807 |
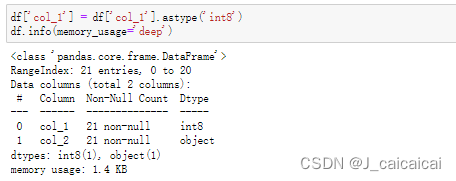
df['col_1'] = df['col_1'].astype('int8')
df.info(memory_usage='deep')
数值类型减小之后memory usage是 1.4KB
2. 把object类型转为categorical类型
df['col_2'] = df['col_2'].astype('category')
df.info(memory_usage='deep')
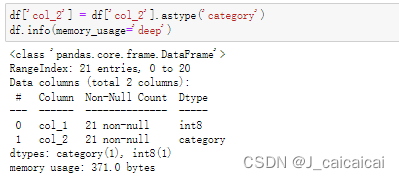
转categorical类型之后之后memory usage是 371 bytes
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)