概述
身为一个苦逼的IT男,每天必不可少的就是要上网查资料,在网上总是经常能看到python、自动化办公、白领的福音之类的字眼,虽然自己主要做嵌入式方面的底层开发,每天也就是码码代码,也没多少办公文件需要我来处理,不过还是怀着好奇的心打算一探究竟。
背景
某一天,就跟正常的每一天一样的某一天,xxx给我发消息,说他们部门马上进入繁忙期,每个人都不能幸免,要开始拼命加班了,不明所以的我还以为他们接了什么大项目,后来一问才知道原来是他们公司把近几年所有同事的工资信息扫描录入一个pdf文件里面,而他们需要找到每个人的工资条并标注,然后单独提取出来放在一个新的pdf文件里面,由于员工的数量庞大,而且信息较多,所以需要动用大量的人力来完成。
听完之后,我这聪明好动的小脑袋马上就开始想了,不是python自动化办公这么牛吗,是不是这种时候就能体现出来了,既然如此,我是不是可以设计一个软件,自动化完成这一系列的工作呢?
思考
需求:设计软件之前第一步必须是分析需求,这一步重中之重,很多人不注重这一点,拿到项目马上就一股脑盲目的写代码,觉得自己灵感迸发,文思泉涌,如有神助,等到设计出来展示给用户,才发现原来这根本就不是用户想要的,悲哀的自己原来从一开始就走偏了,或者说是跑偏了。
既然需求这么重要,那么我们第一件事就是弄懂xxx的需求,经过反复向xxx求证,明确需求如下图所示:
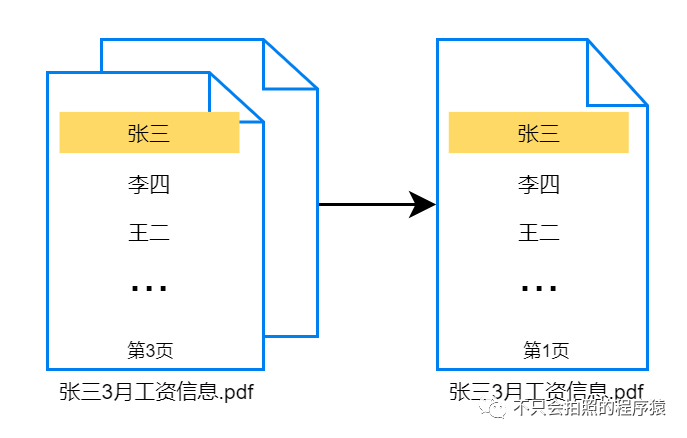
总体来说,xxx需要做的有三件事。
1. 在原文档(包含所有员工工资信息,如上图的3月张三工资信息.pdf文件)中找到指定员工(张三)所在位置,并用特殊颜色(黄色)标记出来。
2. 将将文档中指定员工所在页(如上图中的第3页)外其它页全部删除。
3. 使用上面的规则完成所有员工的处理。
xxx也向我展示了一下她的文件目录,如下图所示:
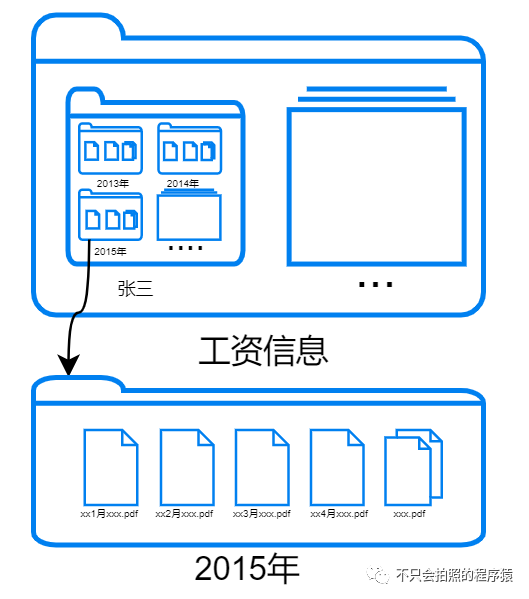
文件结构还是比较简单,
1. 首先有一个根目录(工资信息),存放所有员工工资信息,不同员工之间以目录的方式分开存放,如张三、李四等。
2. 每个员工目录下,将每年的工资信息通过子目录分开存放。
3. 每年的目录下存放着员工当年的工资信息文档,文档以月份为单位,格式为pdf。
设计
整个项目软件设计围绕用户需求展开,大致完成三个功能;
1. 在文档中,找到指定用户,并标记。
2. 删除文档中指定用户所在页外的其它页。
3. 遍历处理所有员工。
技术点:
1. 解析pdf文档内容。
难点:pdf文档存储内容为扫描文件,解析相对比较麻烦。
思路:先将文档所有页转换为jpg格式,然后调用OCR软件解析图片,找到相关的信息。
实施:应用开源软件tesseract。
结果:由于扫描原因,很多内容清晰度并不高,解析效果显得并不理想,不过因为时间有限,也暂时没有时间研究其它的OCR软件,所以此功能暂时放弃。
2. 处理pdf文档。
调用PyPDF2实现对pdf文档的操作,不过该调用库处理pdf文档需要以页为单位,对于本项目也已经足够了。
3. 多文件处理。
调用os库,遍历指定文件夹下所有.pdf文件(注意:对于子目录,需要递归遍历),存储为列表,然后再进行循环处理即可。
4. ui界面
原计划打算调用pyqt5设计用户界面,不过发现项目功能太过单一,所以改用tkinter库搭建。
功能修改:
考虑到pdf文档解析的复杂性,以及项目时间的紧张的原因,最终将项目功能1交给用户实现,软件仅仅完成功能2和3,也正是因为项目只完成了提取页码的工作,所以被命名为《自动提取pdf指定页》。
项目实施:
1. 用户通过肉眼查找文档中指定员工位置,找到后标注,并修改文件名,在文件名前两位加上页码数字(用于后期软件判断),如下图所示。
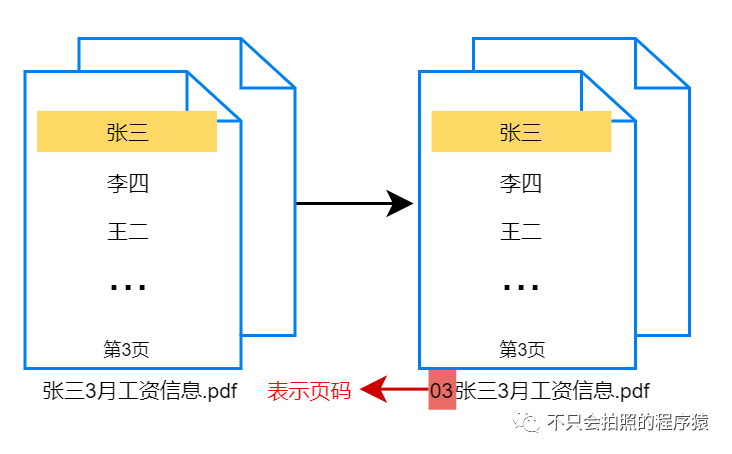
2. 通过软件提取页码,删除文档其它页。
3. 遍历处理所有员工信息,查找部分交于用户,删除部分交由软件。
往期 · 推荐
也没想象中那么神秘的数据结构-一种通用化的双向链表设计(底层源码)
也没想象中那么神秘的数据结构-一环扣一环的“链表”(双向链表)
我用C语言玩对象,框架化的模板模式
我用C语言玩对象,偷偷关注着你的观察者模式(基类设计)
我用C语言玩对象,独一无二的单例模式
关注
更多精彩内容,请关注微信公众号:不只会拍照的程序猿,本人致力分享linux、设计模式、C语言、嵌入式、编程相关知识,也会抽空分享些摄影相关内容,同样也分享大量摄影、编程相关视频和源码,另外你若想要本文章源码请关注公众号:不只会拍照的程序猿,后台回复:PDF拆解源码,也可点击此处下载。
