背景
新一代的Bonree ONE主要体现在轻盈、有序、精准三个亮点,而这三个方向都离不开一个稳定、可靠、高效的数据存储底座。目前,Bonree ONE基于Clickhouse进行存储,容纳了包括APM、RUM、LOG、会话、用户行为分析等多个业务模块的场景数据。
存储的难点
Bonree ONE容纳模块较多,数据使用场景复杂多变,对于底层数据存储,主要难点如下:
· 数据写入量大,数据量级要可以扩展到PB级别的数据摄入;
· 业务流量存在波峰和波谷,而且波峰和波谷的差距较大,存在突发超高峰写入的场景;
· 查询场景复杂,有olap分析、明细数据查询以及复杂的多字段排序场景;
· 查询稳定性要求较高,对于告警、重要指标要做到ms级别响应;
· 集群维护场景复杂度高,要应对集群扩缩容、数据均衡以及数据重分布等场景;
围绕Clickhouse的优化
针对以上难点,我们需要在写入、读取、多租户以及failover机制的策略响应上进行优化,满足Bonree ONE应对超大数据量应用场景的需求。
写入优化
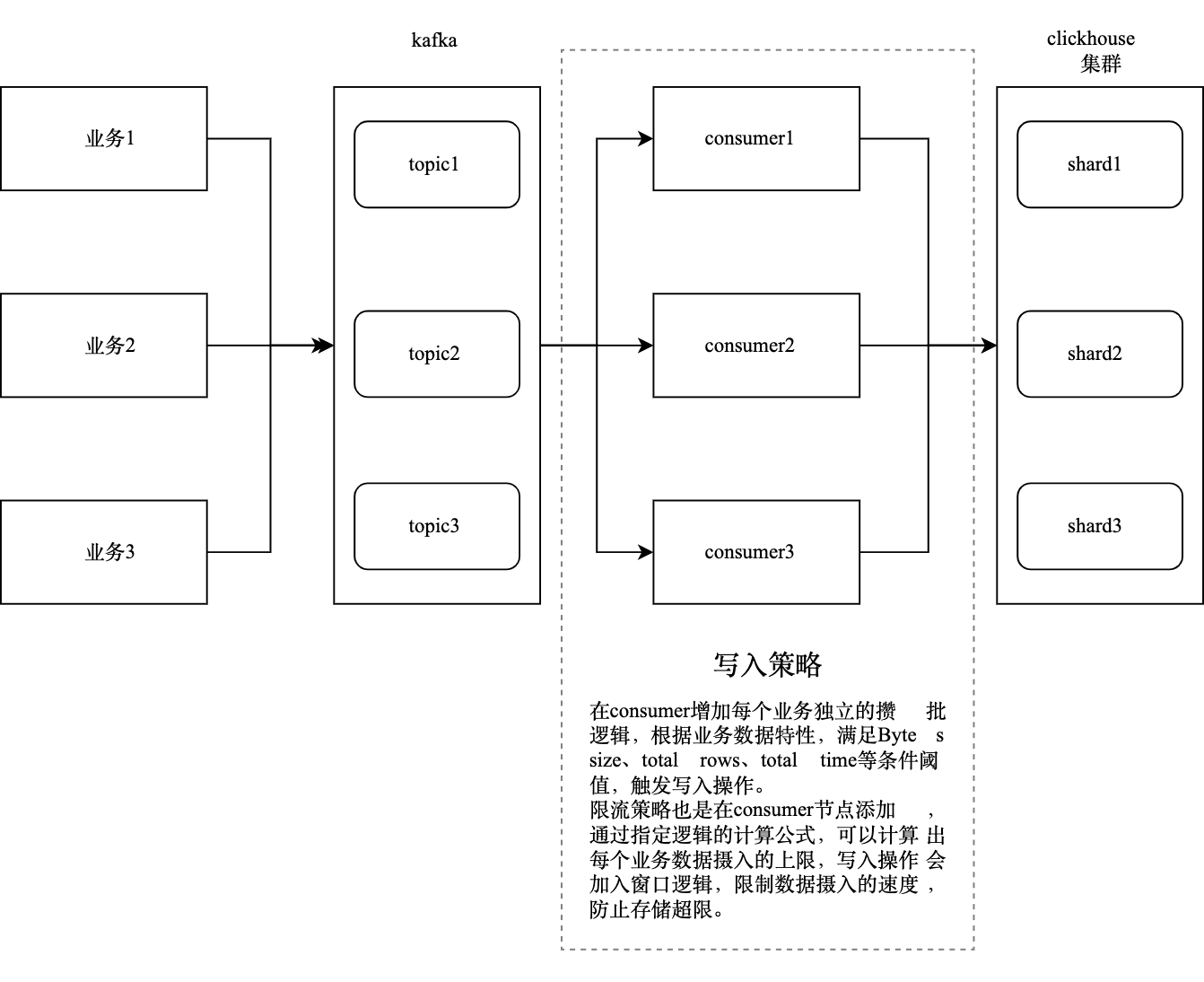
· 按表攒批
Clickhouse是擅长按批写入数据的,批次的数据越大,吞吐量越高。为应对多场景数据涉入的状况和减少业务端对数据存储感知的需求,我们通过消费节点来完成攒批逻辑,根据每个表的个性化定制策略,实现攒批效果的最大化,这既能满足业务效率的要求,又能实现Clickhouse数据摄入的最大吞吐量。
· 限流
在有限存储资源的情况下,Clickhouse集群支持的摄入量是有限的,过大的数据写入主要有两个维度的原因,一个是写入的数据量过多,另一个是写入的峰值过高。前者会通过告警功能送达运维团队,通过扩容或者数据裁剪的操作来解决问题。后者则通过限流来保证存储集群的稳定性。目前,在consumer节点,我们增加了窗口逻辑来满足限流操作策略介入的需要,比如每秒写入次数、写入时间间隔等。
读取优化
为支持多业务有更稳定的数据使用效率,在数据查询上,高频查询的响应效率务必高效,我们主要从以下角度着手优化:
· 查询加速
· orderBy 和 primaryKey的高效使用:orderBy相关字段是表数据的排序设置,它对高频查询的效率有重要。一般orderBy的设置要尽量覆盖当前表业务的高频查询,从低基数到高基数进行排序设置。primaryKey默认与orderBy一致,如果filter条件没有覆盖所有的orderBy字段,则可以提取部分字段作为 primaryKey ,但是primaryKey 必须是 orderBy字段的前缀。
· 索引:针对等值过滤使用BF索引,针对范围查询使用minmax索引,针对全文检索,使用tokenbf索引。
· 物化视图:针对固定优化查询场景,使用物化视图,满足数据一致性的同时,大大提高查询效率。
· projection:针对部分预聚合场景,使用projection的效率更高,而且有更友好的自动路由,减少业务侵入。
· 压缩和编码
Clickhouse提供了多种编码以及多种编解码器,极大提高数据的压缩效率,节省IO、存储等资源。Clickhouse支持的压缩算法如下:
·NONE : No Compression.
·LZ4 : Applies LZ4 fast compression.
·LZ4HC[(level)] : LZ4 HC (high compression) algorithm with configurable level.
·ZSTD[(level)] : ZSTD compression algorithm with configurable level.
经过测试对比,ZSTD的压缩效率是LZ4的5~~6倍。
若想要更高的压缩效率,数据的存储编码是一种更好的优化手段。Clickhouse提供的编码算法如下:
·Delta : This approach stores the difference between 2 neighbor values. It can be combined with LZ4 and ZSTD.
·DoubleDelta : This approach stores the difference between 2 neighbor delta values (delta of deltas). Suitable for time series data.
·Gorilla : Calculates XOR between current and previous value. Suitable for slowly changing floating numbers.
·T64 : It crops unused high bits of values in integer data types(include Enum, Date, DateTime) and puts them into a 64×64 bit matrix.
·FPC : Used in floating point values. XOR between the actual value and the predicted value.
针对以上编码算法的特性,时间字段我们选择基于DoubleDelta编码的ZSTD(1)压缩算法,String类型使用ZSTD(1)的压缩算法。
· 字段类型精细化
Clickhouse提供了非常精细的数据字段进行压缩,比如整数就支持int8、int16、int32、int64,Clickhouse之所以这么细化数据类型,是为了高效的存储和计算,所以在业务使用端,也要做到精确化管理。
· 低基数的String使用 LowCardinality(String)。
· 能用更少位数的数据存储,就选择最少位数的数据存储,比如优先使用int8,而不是默认使用int64。
· 半结构化数据优先使用Map结构,其次是JSON结构。
多租户
Clickhouse为了保障多业务稳定查询,支持了多租户,减少业务之间的影响。我们基于Clickhouse的多租户能力,给予每条产品线单独的租户,实现租户资源个性化配置,满足不同业务不同优先级的诉求。
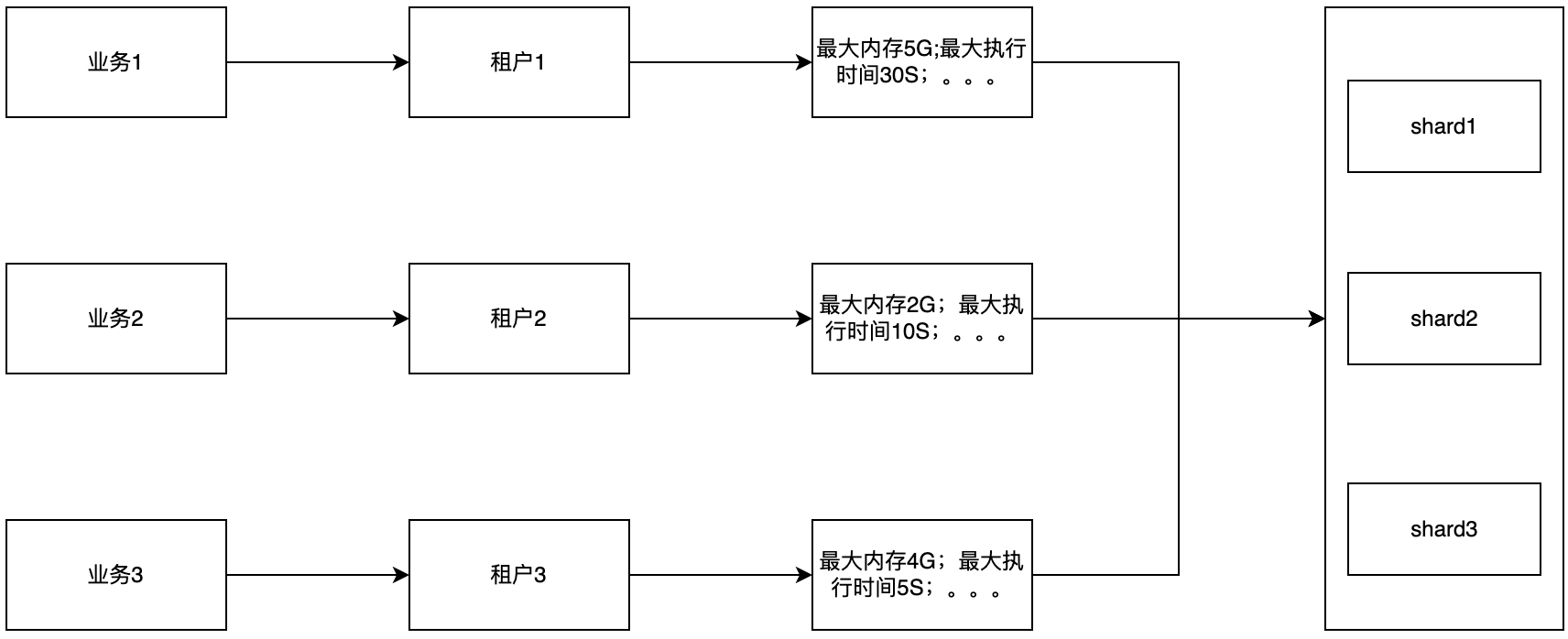
系统是根据各个租户的业务重要程度与场景响应需求来制定对应的租户资源显示的。目前Clickhouse支持了多租户,但是对于Clickhouse内部的资源隔离其实是不具备的,在这一点上,我们是通过完整的监控告警链路来跟进,减少资源冲突带来的不稳定性,支持租户资源的快速释放,从而快速解决某些应急场景。
failover策略
数据的摄入和读取需要高可用机制来满足需求,比如写入端某个consumer节点异常,或者某个clickhouse节点异常等情况,我们如何保证集群的稳定性。
当consumer节点或者clickhouse节点遇到异常时,ch-manager节点能够感知到节点异常进行流量调度,使异常节点不影响数据正常摄入和查询,同时调整流量写入策略,保证consumer节点写入的稳定性,避免发生级联雪崩状况。

效果
· 写入效率:Bonree ONE最新版本的写入效率较春季版本提高3-5倍,且稳定性更强,能够从容应对超预期的流量写入。
· 读取效率:目前Bonree ONE公有云生产环境Clickhouse集群的读取效率,TP99在S级以内。
· 稳定性:Clickhouse集群支持任意单节点服务掉线,而不影响集群整体的写入和查询,consumer任意单节点掉线,也不影响集群整体写入。
最后
在Bonree ONE应用场景愈发复杂的情况下,系统对数据存储的要求会越来越高,我们会在资源管理、实时性等方向上继续深入研究,让Bonree ONE在轻盈、有序、精准的方向上走得更远更稳,同时我们也会积极分享我们的改进方案,跟大家一起学习探讨。