全文谷歌翻译+自己理解
原地址:https://arxiv.org/pdf/2106.14855.pdf
0. 摘要
语义、实例和全景分割已经使用不同的和专门的框架来解决,尽管它们存在潜在的联系。
本文为这些本质上相似的任务提出了一个统一、简单且有效的框架。
这个名为 K-Net 的框架通过一组可学习的Kernel对实例和语义类别进行一致的分割,其中每个内核负责一个instance或者负责一个stuff类别。
为了解决区分各种实例的困难,我们提出了一种内核更新策略,that enables each kernel dynamic and conditional on its meaningful group in the input image. (这个定语从句不知道什么意思)
K-Net 可以通过二分匹配以端到端的方式进行训练,其训练和推理是 NMS-free 和 box-free 的。
没有花里胡哨的东西,K-Net 以 55.2% PQ 和 54.3% mIoU 分别超越了 MS COCO test-dev split 上的全景分割和 ADE20K val split 上的语义分割的所有先前发布的最先进的单模型结果。
其实例分割性能也与 MS COCO 上的 Cascade Mask R-CNN 相当,推理速度快 60%-90%
1. Introduction
图像分割旨在找到相似像素组 (coherent pixels) [48]。
组中有不同的概念,例如语义类别(例如,汽车、狗、猫)或实例(例如,在同一图像中共存的对象)。
基于不同的分割目标,任务被称为不同的名字,即分别是语义和实例分割。
之前也有一些尝试 [19, 29, 51, 64],将两个分割任务联合起来以获得更全面的场景理解。
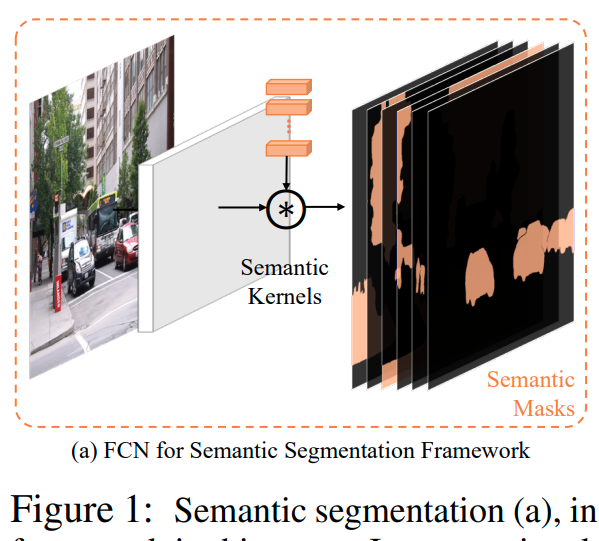
根据语义类别对像素进行分组可以表述为密集分类问题。
如图 1-(a) 所示,最近的方法直接学习一组预定义类别的卷积核(即本文中的语义核),并使用它们对像素 [40] 或区域 [22] 进行分类。这样的框架优雅而直接。
然而,鉴于跨图像的实例数量不同,将此概念扩展到实例分割并非易事。
However, extending this notion to instance segmentation is non-trivial given the varying number of instances across images.
(这句还是很地道的)
因此,实例分割由更复杂的框架和额外的步骤解决,例如目标检测(object detection) [22] 或嵌入生成(embedding generation) [44]。
这些方法依赖于额外的组件,这必须在合理的范围内保证额外组件的准确性,或者需要复杂的后处理,例如非最大抑制(NMS)和像素分组。
最近的方法 [34、50、56] 从密集特征网格生成内核,然后选择内核进行分割以简化框架。
尽管如此,由于它们建立在密集网格上以枚举和选择内核,因此这些方法仍然依赖于手工设计(hand-crafted)的后处理来消除重复实例的掩码或内核。
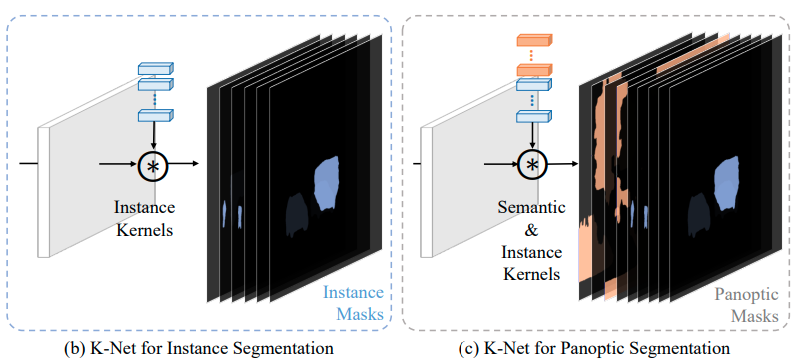
在本文中,我们首次尝试通过内核的概念制定一个统一有效的框架来弥合看似不同的图像分割任务(语义、实例和全景)。 我们的方法被称为 K-Net(“K”代表内核)。
它从一组随机初始化的卷积核开始,去学习两种Kernel,即用于语义类别的语义核和用于实例身份的实例核 (图 1-(b))。
语义内核和实例内核的简单组合允许自然地进行全景分割 (图 1-(c))。
在前向传递中,内核对图像特征进行卷积以获得相应的分割预测。
K-Net 的多功能性和简单性通过两种设计成为可能。
首先,我们制定 K-Net,使其动态更新内核,使它们以图像上的激活为条件。(意思是感受野是整张图片)
这种内容感知机制 (content-aware mechanism) 对于确保每个内核(尤其是实例内核)准确响应图像中的不同目标至关重要。
Such a content-aware mechanism is crucial to ensure that each kernel, especially an instance kernel, responds accurately to varying objects in an image.
通过迭代地应用这种自适应内核更新策略,K-Net 显着提高了内核的判别能力并提高了最终的分割性能。
值得注意的是,该策略普遍适用于所有分割任务的内核。
其次,受目标检测 [4] 最新进展的启发,我们采用二分匹配策略 [47] 为每个内核分配学习目标。
这种训练方法有利于传统的训练策略 [37, 46],因为它在图像中的内核和实例之间建立了一对一的映射。
因此,它解决了处理图像中不同数量实例的问题。(从实验结果来说确实)
另外,它是纯mask驱动的,不涉及boxes。
因此,K-Net 自然是无 NMS 和 box-free 的,这对实时应用程序很有吸引力。
为了展示所提出的统一框架在不同分割任务上的有效性,我们对用于全景和实例分割的 COCO 数据集 [38] 和用于语义分割的 ADE20K 数据集 [72] 进行了广泛的实验。
没有花里胡哨的东西(Without bells and whistles),K-Net 在全景(54.6% PQ)和语义分割基准(54.3% mIoU)上超越了之前所有最先进的单一模型结果,并且与 Cascade Mask RCNN 相比取得了有竞争力的性能 [3].
我们进一步分析学习到的内核,发现实例内核倾向于专注于大小相似的特定位置的对象。
instance kernels incline to specialize on objects at specific locations of similar sizes.
2. Related Work
- Semantic Segmentation
- Instance Segmentation
- Panoptic Segmentation
- Dynamic Kernels
卷积核通常是静态的(第一次听说),即对输入不可知,因此表示能力有限。
以前的作品 [16、18、25、26、73] 探索了不同种类的动态内核来提高模型的灵活性和性能。
一些语义分割方法应用动态内核来改进具有扩大的感受野 [57] 或多尺度上下文 [20] 的模型表示。
不同的是,K-Net使用动态内核来提高分割内核的判别能力,而不是内核的输入特征。
最近的研究应用动态内核直接生成实例 [50、56] 或全景 [34] 分割预测。
由于这些方法从密集特征图生成核,枚举每个位置的核,并过滤掉背景区域的核,它们要么仍然依赖 NMS [50, 56],要么需要额外的核融合 [34] 来消除重复的核或掩码。
K-Net 中的内核不是从密集网格生成的,而是一组可学习的参数,这些参数由它们在图像中的相应内容更新。
K-Net 不需要处理重复的内核,因为它的内核在训练中学习专注于图像的不同区域,受到在内核和实例之间建立一对一映射的二分匹配策略的约束。
3. Methodology
我们通过内核的统一视角来考虑各种分割任务。
3.1 K-Net
尽管对 meaningful group 有不同的定义,但所有分割任务基本上都将每个像素分配给预定义的有意义组之一 [48]。
由于通常假定图像中的组数是有限的,因此我们可以将分割任务的最大组数设置为 N。
例如,有 N 个预定义语义类用于语义分割,或者图像中至多有 N 个对象用于实例分割。
对于全景分割,N 是图像中的东西类和对象的总数。
因此,我们可以使用 N 个内核将图像分成 N 个组,其中每个内核负责找到属于其对应组的像素
分割结果可以这样表示:
M
=
σ
(
K
∗
F
)
M = \sigma(K * F)
M=σ(K∗F)
K
K
K 是特定卷积核,
F
F
F是Backbone+Neck的输出特征,
M
M
M是最终的分割结果,
σ
\sigma
σ是激活函数sigmoid或者softmax
这个公式已经主导了语义分割多年 [8,40,69]。
在语义分割中,每个内核负责在图像中找到相似类别的所有像素。
而在实例分割中,每个像素组对应一个 instance。
但是,以前的方法通过额外的步骤 [22、30、44] 而不是内核来分隔实例。
本文是第一项探索语义分割中的内核概念是否同样适用于实例分割以及更普遍的全景分割的研究。
为了通过内核分离实例,K-Net 中的每个内核最多只能分割图像中的一个对象 (图 1-(b))。
通过这种方式,K-Net 区分实例并同时执行分割,无需额外步骤即可一次完成实例分割。
为简单起见,我们在本文中将这些内核称为语义内核和实例内核,分别用于语义和实例分割。
实例内核和语义内核的简单组合可以自然地进行全景分割,将像素分配给实例 ID 或一类东西 (图 1-(c))。
3.2 Group-Aware Kernels
尽管 K-Net 很简单,但直接通过内核分离实例并非易事。
因为实例内核需要区分图像内部和图像之间的尺度和外观不同的对象。
没有像语义类别这样的共同和明确的特征,实例内核需要比静态内核更强的判别能力。
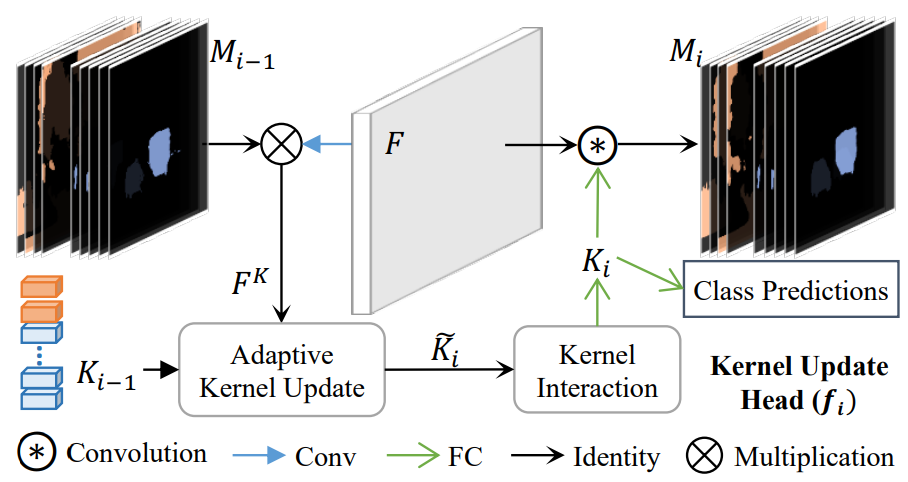
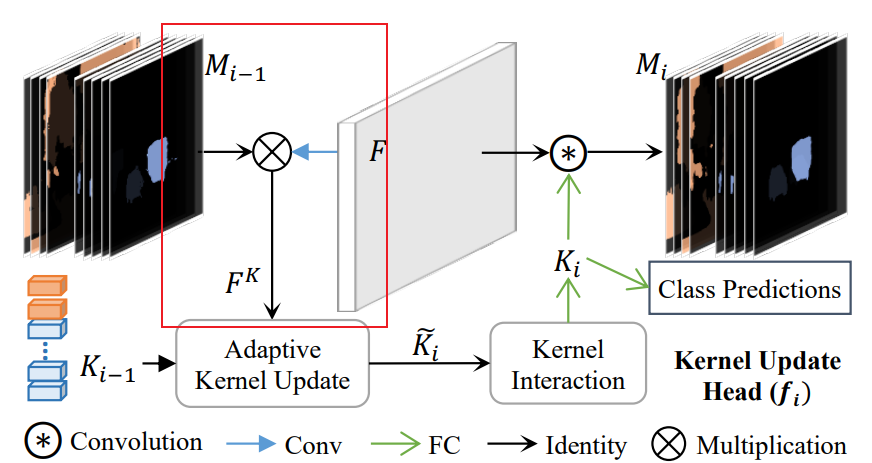
为了克服这一挑战,我们提供了一种方法,通过Kernel更新头使 Kernel 以其相应的像素组为条件 进行更新,如图 2 所示。
Kernel更新头 有3个关键步骤:
- Group feature assembling
- Adaptive kernel update
- kernel interaction
首先,使用掩模预测
M
i
−
1
M_{i-1}
Mi−1 组装每个像素组的组特征
F
K
F_K
FK,也就是这部分,
由于每个单独组的内容将它们彼此区分开来,因此使用
F
K
F_K
FK自适应地更新它们对应的内核
K
i
−
1
K_{i−1}
Ki−1。
之后,内核相互交互 (Kernel Interaction) 以对图像上下文进行综合建模。
最后,获得的Group-aware kernels
K
i
K_i
Ki对feature map
F
F
F进行卷积以获得更准确的mask预测
M
i
M_i
Mi。
如图3所示,这个过程可以迭代进行,因为更精细的划分通常会减少组特征中的噪声,从而产生更具辨别力的内核。
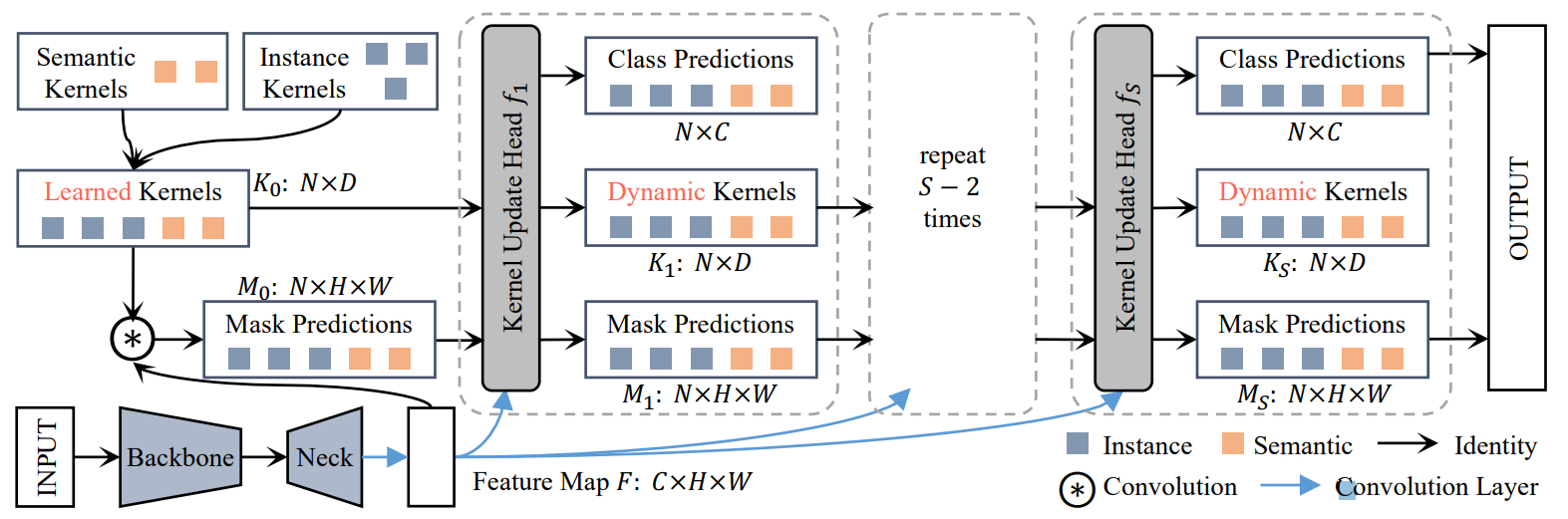
该过程可以形式化为:
K
i
,
M
i
=
f
i
(
M
i
−
1
,
K
i
−
1
,
F
)
K_i, M_i = f_i( M_{i-1}, K_{i-1}, F )
Ki,Mi=fi(Mi−1,Ki−1,F)
值得注意的是,具有迭代细化的Kernel更新头是通用的(语义分割与实例分割都可以用),因为它不依赖于内核的特性。 因此,它不仅可以增强实例内核,还可以增强语义内核。
我们详细说明这三个步骤如下。
Group Feature Assembling
内核更新头 首先组装每个组的特征,稍后将采用这些特征以使内核 具有组意识(group-aware)。
由于
M
i
−
1
M_{i-1}
Mi−1中每个Kernel的掩码本质上定义了一个像素是否属于内核的相关组,我们可以通过将特征图
F
F
F与
M
i
−
1
M_{i-1}
Mi−1相乘来为
K
i
−
1
K_{i-1}
Ki−1组装特征
F
K
F_K
FK 为
F
K
=
∑
u
H
∑
v
W
M
i
−
1
(
u
,
v
)
⋅
F
(
u
,
v
)
,
F
K
∈
R
B
×
N
×
C
F^K = \sum_{u}^{H} \sum_{v}^{W} M_{i-1}(u,v) \cdot F(u, v), \ F^K \in R^{B\times N \times C}
FK=u∑Hv∑WMi−1(u,v)⋅F(u,v), FK∈RB×N×C
(只是单独的相乘??)
Adaptive Feature Update
自适应特征更新。 内核更新头然后使用获得的
F
K
F_K
FK更新内核 Kernel 以提高内核的表示能力。
由于掩模
M
i
−
1
M_{i-1}
Mi−1可能不准确,这种情况更常见,因此每个组的特征也可能包含来自其他组的像素引入的噪声。
为了减少噪声对组特征的不利影响,我们设计了一种自适应内核更新策略。
具体来说,我们首先在
F
K
F_K
FK和
K
i
−
1
K_{i−1}
Ki−1之间进行逐元素乘法,如下所示:
F
G
=
ϕ
1
(
F
K
)
⊗
ϕ
2
(
K
i
−
1
)
,
F
G
∈
R
B
×
N
×
C
F^G = \phi_1(F^K) \otimes \phi_2 (K_{i-1}) , F^G \in R^{B\times N \times C}
FG=ϕ1(FK)⊗ϕ2(Ki−1),FG∈RB×N×C
ϕ
1
\phi_1
ϕ1与
ϕ
2
\phi_2
ϕ2都是线性转换
接下来,Head会学习两个门:
G
F
G^F
GF与
G
K
G^K
GK,该门去学习新核
K
~
\tilde{K}
K~的权重系数,具体来说:
G
K
=
σ
(
ψ
1
(
F
G
)
)
G
F
=
σ
(
ψ
2
(
F
G
)
)
G^{K} = \sigma( \psi_1 (F^G) ) \\ G^F = \sigma( \psi_2 (F^G) )
GK=σ(ψ1(FG))GF=σ(ψ2(FG))
新核的计算:
K
~
=
G
F
⊗
ψ
3
(
F
K
)
+
G
K
⊗
ψ
4
(
K
i
−
1
)
\tilde{K} = G^F \otimes \psi_3(F^K) + G^K \otimes \psi_4(K_{i-1})
K~=GF⊗ψ3(FK)+GK⊗ψ4(Ki−1)
⊗
\otimes
⊗ 是element-wise multiplication,诶,那上边儿的
⋅
\cdot
⋅ 是啥??
其中,
ψ
n
\psi_n
ψn是一些不同的FC层+LN,
K
~
\tilde{K}
K~是接下来要用在Kernel Interaction中。
此处学习的门起着类似于 Transformer [52] 中的自我注意机制的作用,其输出被计算为值的加权和。
在 Transformer 中,分配给每个值的权重通常由Q和K点积计算得出。
类似地,Adaptive Kernel Update 本质上是对内核特征
K
i
−
1
K_{i−1}
Ki−1 和组特征
F
G
F^G
FG 进行加权求和。
它们的权重
G
K
G^K
GK 和
G
F
G^F
GF 是通过逐元素乘法计算的,这可以看作是另一种相容函数(compatibility function)。
Kernel Interaction
内核之间的交互对于将来自其他组的上下文信息告知每个内核非常重要。
此类信息允许内核隐式建模和利用图像组之间的关系。
为此,我们添加了一个内核交互过程,以在给定更新内核
K
~
\tilde{K}
K~的情况下获得新内核
K
i
K_i
Ki。 在这里,我们简单地采用 Multi-Head Attention [52],然后是前馈神经网络,这在之前的工作中已被证明是有效的 [4, 52]。
然后使用内核交互的输出
K
i
K_i
Ki通过
M
i
=
g
i
(
K
i
)
∗
F
M_i = g_i(K_i) ∗ F
Mi=gi(Ki)∗F生成新的掩码预测,其中
g
i
g_i
gi是一个 FC-LN-ReLU 层,后面跟着一个 FC 层。
K
i
K_i
Ki还将用于预测实例和全景分割中的分类分数。
3.3 Training Instance Kernels
虽然每个语义内核(semantic kernel)都可以分配给一个常量语义类,但缺乏明确的规则来将不同数量的目标分配给实例内核(instance kernels)。
在这项工作中,我们采用二分匹配策略并设置预测损失 [4, 47] 以端到端的方式训练实例内核。(应该有一篇会引用DETR吧)
与之前依赖框的工作 [4, 47] 不同,实例内核的学习是纯粹的掩码驱动的(mask-driven),因为 K-Net 的推理自然是无框的。
Loss Functions
实例 Kernel 的损失函数:
K
K
=
λ
c
l
s
+
L
c
l
s
+
λ
c
e
+
L
c
e
+
λ
d
i
c
e
+
L
d
i
c
e
K_K = \lambda_{cls} + L_{cls} + \lambda_{ce} + L_{ce} + \lambda_{dice} + L_{dice}
KK=λcls+Lcls+λce+Lce+λdice+Ldice
Focal Loss是分类loss,后者是CE Loss和Dice Loss
Given that each instance only occupies a small region in an image
鉴于每个实例只占据图像中的一个小区域,CE 损失不足以处理掩码的高度不平衡学习目标。
因此,我们follow之前的工作 [50、55、56] ,应用 Dice 损失 [42] 来处理这个问题。
Mask-based Hungarian Assignment
我们采用 [4, 47] 中使用的匈牙利匹配策略进行目标分配,以端到端的方式训练 K-Net。
它根据匹配成本(matching cost)在预测实例掩码和真实 (GT) 实例之间建立一对一映射。
The matching cost is calculated between the mask and GT pairs in a similar manner as the training loss.
匹配成本(matching cost)与训练loss的计算类似
3.4 Applications to Various Segmentation Tasks
Panoptic Segmentation
对于全景分割任务,Kernel 有实例Kernel
K
0
i
n
s
K_0^{ins}
K0ins和语义Kernel
K
0
s
e
m
K_0^{sem}
K0sem. 本文采用语义FPN来生产高分辨率的特征图
F
F
F, 同时我们在其中添加了位置编码来增强位置信息。
具体来说,给定由 FPN [36] 生成的特征图 P2、P3、P4、P5,根据 P5 的特征图大小计算位置编码,并将其与 P5 相加。
然后使用语义 FPN [28] 生成最终的特征图。
由于语义分割主要依靠语义信息进行逐像素分类,而实例分割更喜欢准确的定位信息来分离实例,我们使用两个独立的分支来生成特征
F
i
n
s
F^{ins}
Fins 和
F
s
e
m
F^{sem}
Fsem,以与
K
0
i
n
s
K^{ins}_0
K0ins 和
K
0
s
e
m
K^{sem}_0
K0sem 进行卷积,以分别生成实例和语义掩码
M
0
i
n
s
M^{ins}_0
M0ins 和
M
0
s
e
m
M^{sem}_0
M0sem。
(Notably)值得注意的是,最初没有必要从不同的分支生产“thing”和“stuff”掩码来产生合理的性能。
这样的设计与以前的做法 [28, 56] 一致,并且根据经验产生更好的性能 (大约提升1% PQ值)

为了产生最终的全景分割结果,我们按照 MaskFormer [12] 的混合顺序 paste thing and stuff masks。
To produce the final panoptic segmentation results, we paste thing and stuff masks in a mixed order following MaskFormer [12].
我们还发现在 K-Net 中有必要首先根据分类分数对掩码的粘贴顺序进行排序,以进一步过滤掉置信度较低的掩码预测。
这种方法在经验上比以前的分别粘贴thing和stuff掩码的策略表现更好(大约 1% PQ)[28、34]。
Instance Segmentation
在类似的框架中,我们简单地删除了内核和掩码的连接过程来执行实例分割。
我们没有删除语义分割分支,因为语义信息仍然是实例分割的补充。
请注意,在这种情况下,语义分割分支不使用额外的标注。
语义分割的GT标签是通过将实例掩码转换为其相应的类标签来构建的。
Semantic Segmentation
由于 K-Net 不依赖于特定的模型表示体系结构,因此 K-Net 可以通过简单地将其内核更新头附加到任何依赖语义内核的现有语义分割方法 [8、40、59、69] 来执行语义分割。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)