并查集(Union-Find)是解决动态连通性问题的一类非常高效的数据结构。本文中,我将尽我所能用最简单,最清晰的逻辑展示出并查集的构造过程,同时还将对其中的关键步骤给出相应的Python代码。
动态连通性
可以想象一张地图上有很多点,有些点之间是有道路相互联通的,而有些点则没有。如果我们现在要从点A走向点B,那么一个关键的问题就是判断我们能否从A走到B呢?换句话说,A和B是否是连通的。这是动态连通性最基本的诉求。现在给出一组数据,其中每个元素都是一对“点”,代表这对点之间是联通的,我们需要设计一个算法,让计算机依次读取这些数据,最后判断出其中任意两点是否连通。注意,并查集所涉及的动态连通性只是考虑“是否连通”这一二值判别问题,而不涉及连通的路径到底是什么。后者不在本文的考虑范围之内。
举个例子,比如下图。为了简单起见,我们以整数 0~9 表示图中的10个点,然后给出两两连通的数据如下:[(4, 3), (3, 8), (6, 5), (9, 4), (2, 1), (8, 9), (5, 0), (7, 2), (6, 1), (6, 7)]
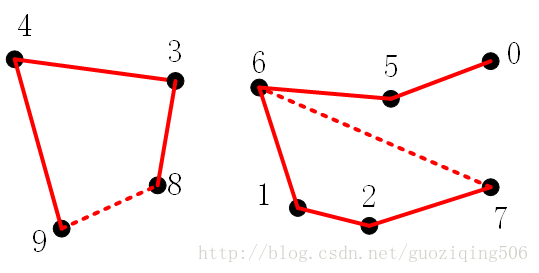
我们将这些“点对”依次通过画图连接的方式在图中表示出来。当然,如果其中某“对”点本身就是连通的,比如点对
(8,9)
,还有
(6,7)
在连接前就已经是连通的,我们可以自动忽略这种情况。通过这张图,可以直观的看出,有些点对,像0与1是相互连通的,而有些像0与9是不连通的。现在的问题是,如何让计算机读取这些数据来构建一种数据结构(合并连通点),然后在这种数据结构上高效的做出对某个点对是否连通的判断(查询连通性)。这也就是并查集名字的由来了。
为了实现上面所描述的功能,一个简单的思路就是分组。也就是说,我们可以把相互连通的点看成一个组,如果现在查询的点对分别在不同的组中,则这个点对不连通,否则连通。下面我们先来简单分析一下这种操作的具体过程,分“并”和“查”两个方面来分析。为了方便描述,我这里先举一个例子:比如上图的10个点,现在就令每个点的值为其初始组别,我们可以得到下面这个表:
| element | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| group number | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
现在,“并”的操作可以这样来描述:观察第一个点对
(4,3)
,于是先找到点4和3,发现所在组别不一样,再将点4和3的组别都变成3(当然都变成4也行,这个随意设计),然后就产生了如下的表:
| element | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| group number | 0 | 1 | 2 | 3 | 3 | 5 | 6 | 7 | 8 | 9 |
而“查”的操作其实就是“并”操作的第一步:找到点对中两个点所在的组别,看是否相同。
也就是说,并查集的两类基本操作中,都涉及了“根据点找组别”的过程,因此我们先给出一个高效的“查”的算法。我把它叫做Quick-Find 算法。
Quick-Find 算法
设计高效的查询算法非常简单,从上面的表格我们就能联想到,这种元素和组别之间的一一对应关系可以用“键值对”的存储方式实现。我直接给出Python的实现代码,非常简单。
def con_eleGroupNum(eleList):
"""
construct the element-group number map
:param eleList: the list of distinct elements
:return: the dictionary with the form {element: group number}
"""
result = {}
num = 1
for i in eleList:
result[i] = num
num += 1
return result
这样,因为可以直接找到“键”,并通过“键”访问其对应的值,所以查询的复杂度为
O(1)
,perfect!
但是如果是并呢?这就有点麻烦了,因为不知道到底是哪些“键”(点)对应着某个“值”(组别),所以需要对整个列表进行遍历,逐一修改。假设现在有
N
个点,需要添加的路径由M个点对组成,那么“并”的时间复杂度为
O(MN)
。这是个平方级别的时间复杂度,显然,在数据量极大的情况下,平方级别的算法是有问题的。下面的代码展示了根据一个点对修改组别(合并)的过程,我们以每次点对元素的最小值为新的组别:
def change_GroupNum(pairGroupNum, eleGroupNum):
"""
connect
:param pairGroupNum: the two group numbers of the pair of elements
:param eleGroupNum: the dictionary with the form {element: group number}
:return: None
"""
newGroupNum = min(pairGroupNum)
for i in eleGroupNum:
if eleGroupNum[i] == pairGroupNum[0] or eleGroupNum[i] == pairGroupNum[1]:
eleGroupNum[i] = newGroupNum
def quick_find(elePair, eleGroupNum):
"""
find and connect
:param elePair: the pair of elements
:param eleGroupNum: the dictionary
:return: None
"""
pairGroupNum = (eleGroupNum[elePair[0]], eleGroupNum[elePair[1]])
change_GroupNum(pairGroupNum, eleGroupNum)
Quick-Union 算法
为了解决这种低效的并,我们需要重新考虑一下这个问题。现在的关键在于如何能快速地通过一个点找到其相应的组别和这个组中的所有点,并且批量改变这些点的组别。显然,这里面设计了数据的存储和更新,我们考虑从设计新的数据结构入手。既然简单的键值对无法解决,那么别的数据结构呢?链表,树,图?琢磨一下,你会发现树结构其实很适合:比起链表和图,树结构有一个非常“显眼”的根节点,我们可以用它来代表这个树所有节点的组别,修改了根节点,就相当于是修改了全树,此外,树的层次化结构决定了由一个节点查询到组别的过程也是非常高效的。
用树结构实现并查集的算法思路可以如下描述,假设现在要添加多个路径(点对):
初始化:每个点看做一棵树,当然这是一棵只有根节点的树,存储了这个节点本身的值作为组别(你也可以令其他不会产生冲突的记号做组别);
查询:对于点对
(a,b)
,通过
a
和b向其根节点回溯(当然初始时就是它们本身),判断其所在组别;
合并:若不在同一组别,令其中一个点(比如
a
吧)所在树的根节点成为另一个点(比如b)的根节点的孩子。这样即便再查询到
a
,通过上面的查询过程,程序也会最终判断得到的是现在b的根节点所在的组别,相当于是改变了
a
所在组的全部元素的组别;
这样,在计算过程中的所有树其实就是一棵多叉树。然而我们发现,现在产生了一个新的问题,那就是因为查询算法也改了,导致现在Quick-Union的查询过程效率好像不那么令人满意了。甚至在最坏的情况下,这样的多叉树退化成了一个链表(不具体说了,大家想想应该能明白)。
但是没办法啊,因为你要找树根,怎么着复杂度也得是O(H)的,其中
H
是树高。那再想想,能不能尽可能地降低这里的树高呢?也就是说在产生树和合并树的时候就尽量使得每棵树都是“扁平化”的。
大树小树的合并技巧
先看看树的合并,对于我们上面说的这种合并(一棵树的根直接变成另一棵树根的孩子),有一个基本的原则是小树变成大树的子树,会比大树变成小树的子树更加不易增加树高,这一点通过下面的图就能看出来。所以我们可以在生成树的时候,令根节点存储一个属性 weight,用来表示这棵树所拥有的节点数,节点数多的是“大树”,少的就是“小树”。
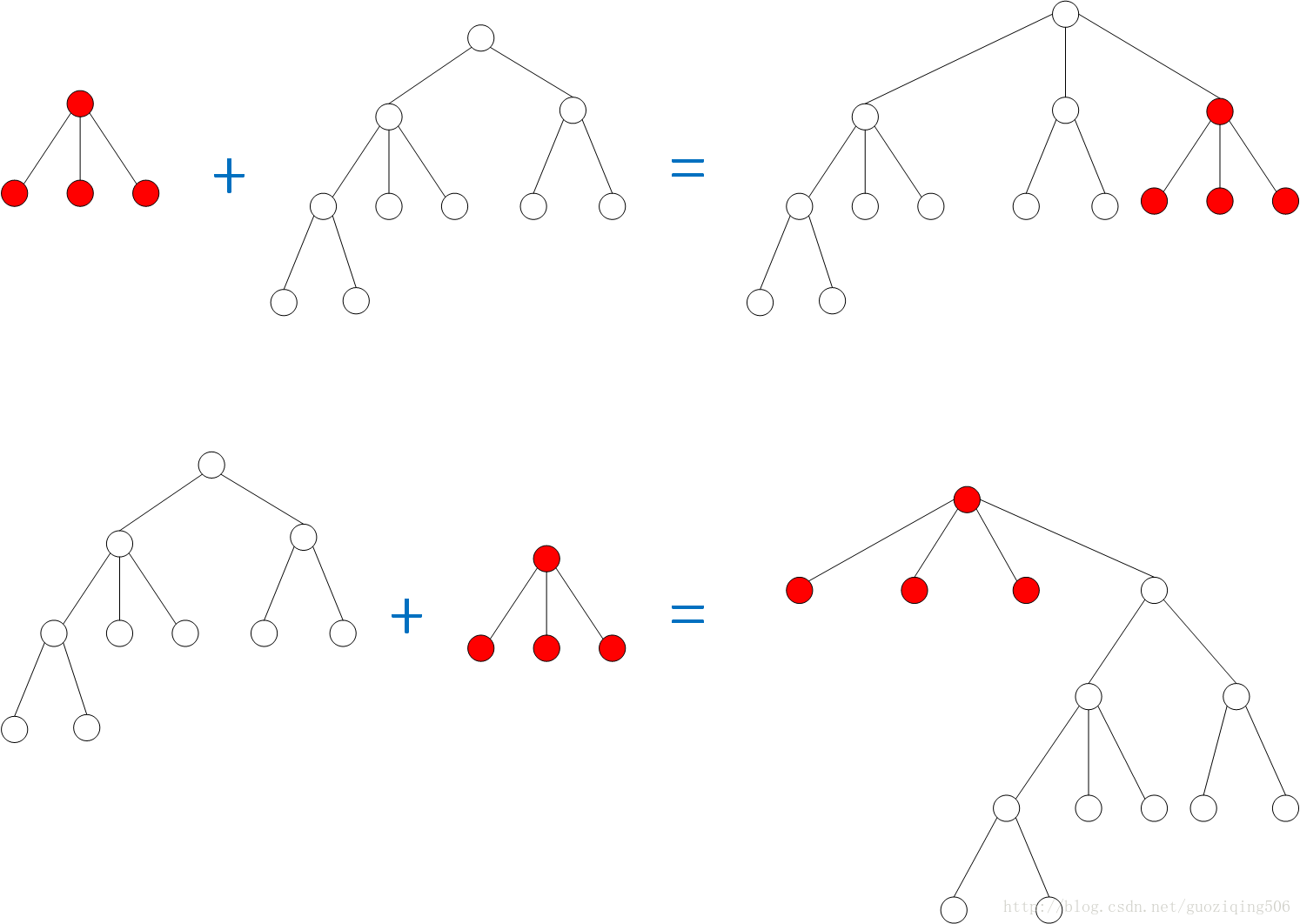
压缩路径
再看看树的生成,这一点就要在查询过程中做文章了,因为每次我们是从树的一个节点回溯到其根节点,所以一个最直接的办法是,将这条路径上的所有中间节点记录下来,全部变成根节点的子节点。但是这样一来会增加算法的空间复杂度(反复开辟内存和销毁)。所以一个备选的思路是每遍历到一个节点,就将这个节点变成他的爷爷节点的孩子(和其父节点在同一层了)。相当于是压缩了查询的路径,这样,频繁的查询当然会导致树的“扁平化”程度更彻底。
代码展示
经过上面大小树的合并原则以及路径的压缩,其实“并”和“查”两种操作的时间复杂度都非常趋近于O(1)了。下面我给出一些关键函数的代码。完整的代码参加我的github主页:https://github.com/guoziqingbupt/Union-Find
class UFTreeNode(object):
def __init__(self, num):
self.num = num
self.children = []
self.parent = None
self.weight = 1
def genNodeList(eleList):
"""
generating the node of each element
:param eleList: the list of elements
:return: a dictionary formed as {element: corresponding node}
"""
result = {}
for ele in eleList:
result[ele] = UFTreeNode(ele)
return result
def locPair(elePair, eleNodeMap):
"""
locate the positions of the pair of elements
:param elePair:
:param eleNodeMap: a dictionary formed as {element: corresponding node}
:return: the two nodes of the pair of elements
"""
return [eleNodeMap[elePair[0]], eleNodeMap[elePair[1]]]
def backtracking(node):
"""
1. find the root of a node
2. cut down the height of the tree
:param node:
:return: the root of node
"""
root = node
while root.parent:
cur = root
root = root.parent
if cur.parent.parent:
grandfather = cur.parent.parent
grandfather.children.append(cur)
return root
def quickUnion(elePair, eleNodeMap):
"""
union process
:param elePair:
:param eleNodeMap:
:return:
"""
nodePair = locPair(elePair, eleNodeMap)
root_1, root_2 = backtracking(nodePair[0]), backtracking(nodePair[1])
if root_1 is not root_2:
if root_1.weight >= root_2.weight:
root_1.weight += root_2.weight
root_1.children.append(root_2)
root_2.num = root_1.num
else:
root_2.weight += root_1.weight
root_2.children.append(root_1)
root_1.num = root_2.num
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)