文章目录
- 1. SqueezeNet
- 2. ShuffleNet
-
- 3. MobileNet
-
- 4. GhostNet
-
1. SqueezeNet
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size
考虑到卷积层的参数量为
C
i
n
∗
C
o
u
t
∗
K
∗
K
C_{in}*C_{out}*K*K
Cin∗Cout∗K∗K,显然,为了减少参数量,可以从输入输出通道数和卷积核尺寸两个角度出发:
- 使用更多的1×1卷积
- 减小3×3卷积的输入核输出通道数
根据以上两个基本原则,SqueezeNet中设计了一个Fire module,squeeze中只使用了1×1卷积,以较少的参数量为代价降低通道数,然后在expand中使用1×1和3×3扩展通道数。

class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
2. ShuffleNet
2.1 v1
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
提出问题:对于深度可分离卷积,1×1占用的计算量太大
解决方案:既然3×3卷积可以通过分组减小计算量,那么1×1也可以设置为分组卷积
引出新问题:如果多个组卷积堆叠在一起,就有一个副作用----来自某个通道的输出只来自输入通道的一小部分,如下图(a)所示,导致不同组之间无信息交流。
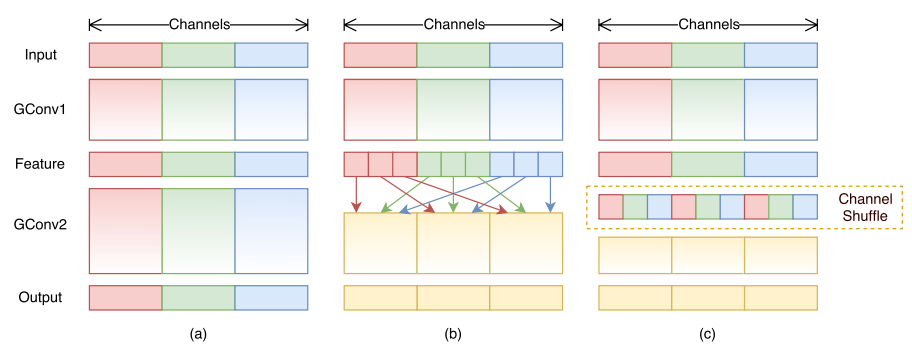
进一步的解决方案:将每个组中的通道划分为几个子组,然后向下一层中的每个组提供不同的子组,如上图(b)所示,此时不同组之间进行了信息的交流。
究极解决方案:使用channel shuffle操作,即reshape->transpose->flatten,简单的操作就能均匀打乱通道。

def channel_shuffle(x, groups):
b, n, h, w = x.size()
channels_per_group = n // groups
x = x.view(b, groups, channels_per_group, h, w)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(b, -1, h, w)
return x
基于以上改进,设计了新的残差单元----ShuffleNet Units,(a)为使用了标准的深度可分离卷积的残差单元,(b)为使用了1×1组卷积和channel shuffle的新残差单元,(c)为stride=2时的新残差单元,在shotcut分支采用了stride=2的AVG Pool而不是1×1卷积,并且使用concat代替add操作,能够以较低的成本扩充通道数。
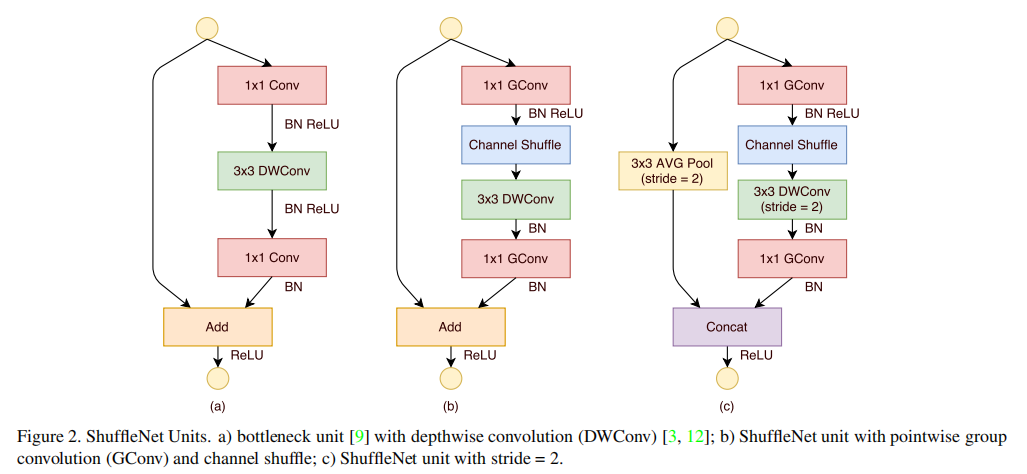
2.2 v2
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
提出问题:神经网络架构的设计是由间接度量(如FLOPs)来指导的,但是实验表明,具有相似FLOPs的网络具有不同的速度(如下图所示),因此,使用FLOPs作为计算复杂度的唯一度量是不够的,可能会导致次优设计。
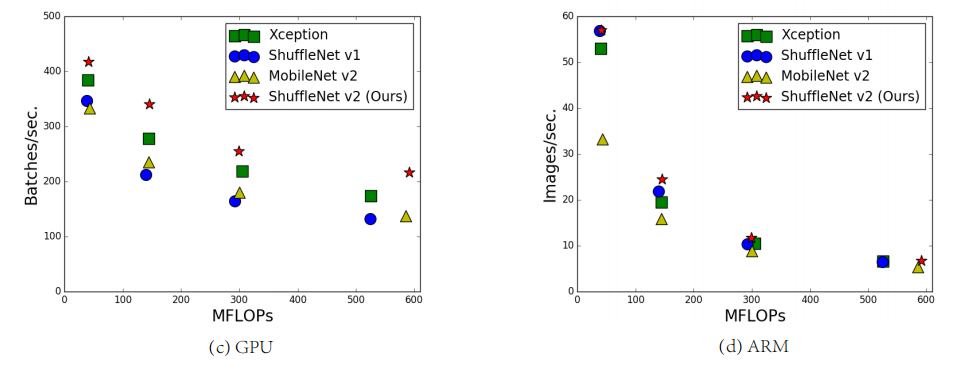
间接(FLOPs)和直接(速度)指标之间的差异可以归结于两个主要原因:
- 内存访问成本(MAC)和并行度:组卷积等高MAC操作(分组会导致读写操作成倍增加)可能会成为GPU的瓶颈;并行度高的模型比其他并行度低的模型快得多。
- 根据平台的不同,具有相同流程的操作可能有不同的运行时间,如GPU和ARM
解决方案:对于有效的网络架构设计,应该考虑两个原则。首先,应该使用直接度量(例如,速度),而不是间接度量(例如,FLOPs)。其次,这些指标应该在目标平台上进行评估。
贡献:
(1)推导了四种高效网络设计的指导方针
-
G1: 输入输出通道数相等可尽量降低内存访问成本(MAC):轻量级网络中常使用深度可分离卷积,其中点卷积计算复杂度最大,因此以点卷积为例进行分析。假设输入输出通道数分别为
C
i
n
C_{in}
Cin和
C
o
u
t
C_{out}
Cout,特征图尺寸为
H
×
W
H×W
H×W,在bias=False的情况下,浮点运算次数
B
=
H
×
W
×
C
o
u
t
×
C
i
n
B=H×W×C_{out}×C_{in}
B=H×W×Cout×Cin;假设计算设备中的缓存大到足以存储features和weight,
M
A
C
=
H
×
W
×
(
C
o
u
t
+
C
i
n
)
+
C
o
u
t
×
C
i
n
MAC=H×W×(C_{out}+C_{in})+C_{out}×C_{in}
MAC=H×W×(Cout+Cin)+Cout×Cin。在固定FLOPs的情况下,根据均值不等式有:
 因此,MAC有一个由FLOPs给出的下界。当输入通道和输出通道的数量相等时,MAC达到下界。
因此,MAC有一个由FLOPs给出的下界。当输入通道和输出通道的数量相等时,MAC达到下界。
-
G2: 过度的组卷积会增加MAC:对于分组卷积,浮点运算次数
B
=
(
H
×
W
×
C
o
u
t
×
C
i
n
)
/
g
B=(H×W×C_{out}×C_{in}) / g
B=(H×W×Cout×Cin)/g,MAC与FLOPs的关系如下:
 显然,固定FLOPs时,MAC随着分组数g的增大而增大。
显然,固定FLOPs时,MAC随着分组数g的增大而增大。
-
G3: 网络碎片化降低并行度:虽然多分支这种碎片化的结构已被证明有利于提升网络性能,但它可能会降低效率,因为它对像GPU这样具有强大并行计算能力的设备不友好。还引入了额外的开销,如内核启动和同步。
-
G4: 元素级操作是不可忽略的:在如shufflenet-v1和mobilenet-v2这样的轻量级模型中,元素级操作占用了相当多的时间,特别是在GPU上。元素级操作包括ReLU、Add等,虽然FLOPs很小,但是MAC较高。
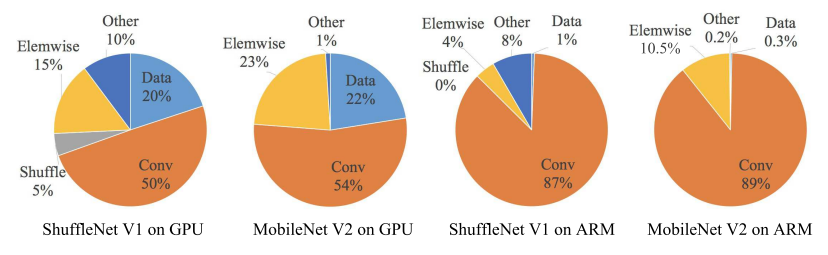
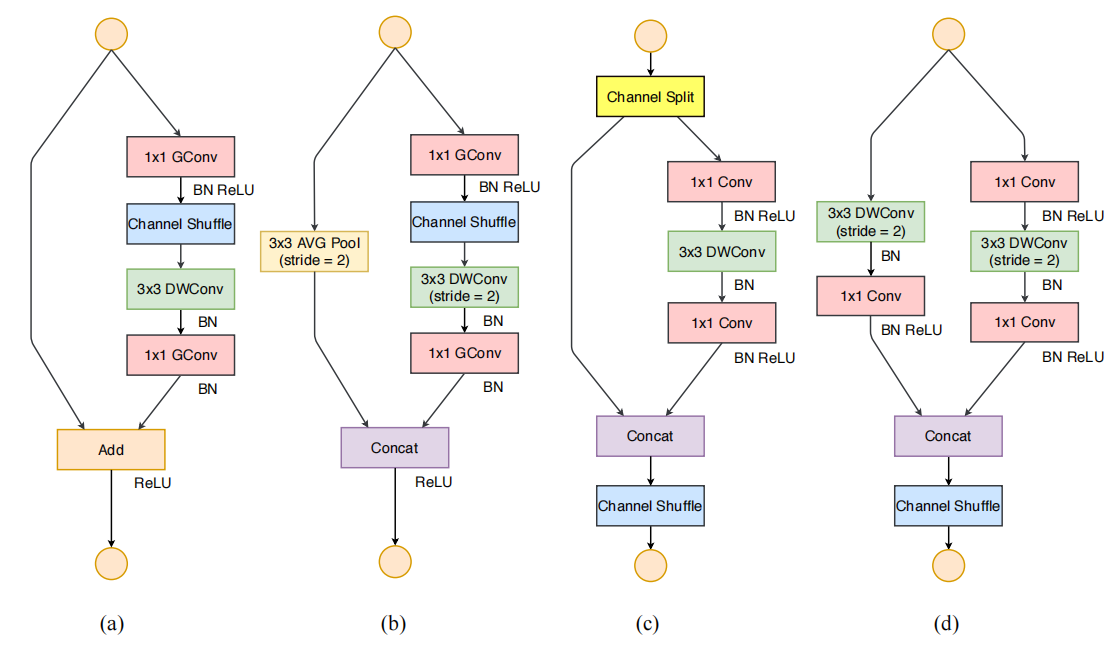
(2)基于推导的四种高效网络设计的指导方针,设计了新的轻量级残差模块(如下图,a、b是v1中的单元结构,c、d是v2中的单元结构):通过channel split保证输入输出通道数相等,符合G1; 将1×1分组卷积替换为标准的1×1卷积,符合G2和G3(因为分组卷积是碎片化结构);将Add替换为Concat,并去掉了最后的ReLU,替换为channel shuffle,符合G4。
3. MobileNet
3.1 v1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
提出了深度可分离卷积,能够大幅减少参数量和计算量:
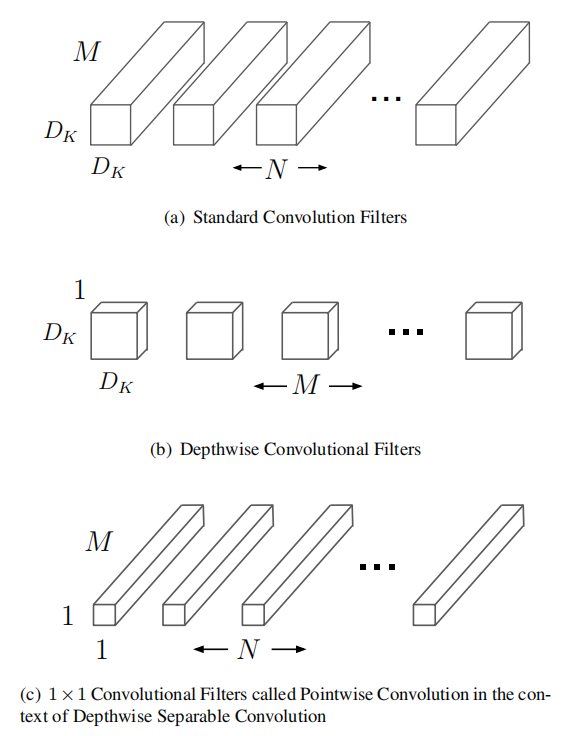
假设输入通道和输出通道数分别为
N
N
N和
M
M
M,卷积核尺寸为
D
K
×
D
K
D_K×D_K
DK×DK,输出特征图尺寸为
D
F
×
D
F
D_F×D_F
DF×DF,那么标准卷积的计算量为:
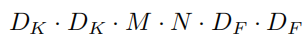
深度可分离卷积的计算量为:
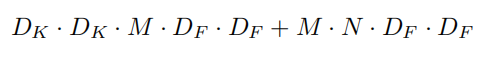
计算量降低了:
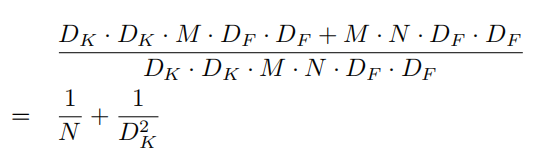
有一点需要注意,由于Depthwise卷积使用了分组卷积,因此适用于移动端等流水线型平台,对GPU不友好。
3.2 v2
MobileNetV2: Inverted Residuals and Linear Bottlenecks
3.3 v3
Searching for MobileNetV3
4. GhostNet
4.1 v1
GhostNet: More Features from Cheap Operations
提出了轻量级模块Ghost module,简单来说,其实就是将深度可分离卷积倒过来,先PW卷积再DW卷积,只是减少了PW卷积数量,然后通过identity补上通道数,从而既能扩展输出通道数又能减少参数量和计算量。
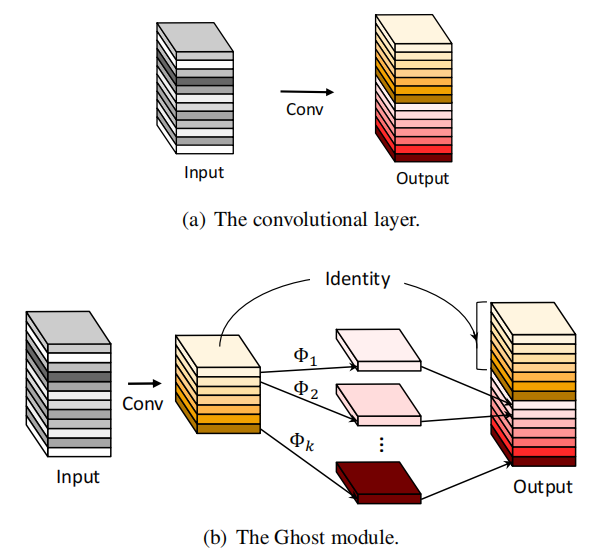
4.2 v2
GhostNetV2: Enhance Cheap Operation with Long-Range Attention
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)