我对整个领域有点陌生,因此决定研究 MNIST 数据集。我几乎改编了整个代码https://github.com/pytorch/examples/blob/master/mnist/main.py,只有一个重大变化:数据加载。我不想使用 Torchvision 中预加载的数据集。所以我用了CSV 格式的 MNIST.
我通过继承 Dataset 并创建一个新的数据加载器来加载 CSV 文件中的数据。
这是相关代码:
mean = 33.318421449829934
sd = 78.56749081851163
# mean = 0.1307
# sd = 0.3081
import numpy as np
from torch.utils.data import Dataset, DataLoader
class dataset(Dataset):
def __init__(self, csv, transform=None):
data = pd.read_csv(csv, header=None)
self.X = np.array(data.iloc[:, 1:]).reshape(-1, 28, 28, 1).astype('float32')
self.Y = np.array(data.iloc[:, 0])
del data
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
item = self.X[idx]
label = self.Y[idx]
if self.transform:
item = self.transform(item)
return (item, label)
import torchvision.transforms as transforms
trainData = dataset('mnist_train.csv', transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,), (sd,))
]))
testData = dataset('mnist_test.csv', transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,), (sd,))
]))
train_loader = DataLoader(dataset=trainData,
batch_size=10,
shuffle=True,
)
test_loader = DataLoader(dataset=testData,
batch_size=10,
shuffle=True,
)
However this code gives me the absolutely weird training error graph that you see in the picture, and a final validation error of 11% because it classifies everything as a '7'.
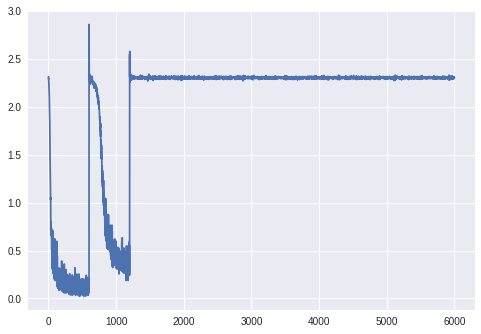
我设法将问题追溯到如何标准化数据,如果我使用示例代码中给出的值(0.1307和0.3081)进行transforms.Normalize,并以“uint8”类型读取数据,那么它可以完美地工作。
请注意,有很数据差异最小这是在这两种情况下提供的。对 0 到 1 的值按 0.1307 和 0.3081 进行归一化与对 0 到 255 的值按 33.31 和 78.56 进行归一化具有相同的效果。这些值甚至基本相同(黑色像素在第一种情况下对应于 -0.4241,在第一种情况下对应于 -0.4242)在第二)。
如果您想查看可以清楚地看到此问题的 IPython Notebook,请查看https://colab.research.google.com/drive/1W1qx7IADpnn5e5w97IcxVvmZAaMK9vL3
我无法理解是什么导致了这两种略有不同的数据加载方式的行为如此巨大的差异。任何帮助将不胜感激。