目录
1、线性表
1.1、线性表的概念:
1.2、线性表数据的存储方式:
注意:
2、顺序表
2.1、概念
2.2、顺序表的存储结构
3、顺序表的各种操作函数实现
3.1、顺序表初始化
3.2、顺序表判满函数
3.3、顺序表扩容函数
3.4、插入数据--头插
3.5、插入数据--尾插
3.6、插入数据--按位置插
3.7、顺序表判空函数
3.8、删除数据--按位置删
3.9、删除数据--头删
3.10、删除数据--尾删
3.11、查找数据
3.12、删除数据--按值删除
3.13、清空顺序表
3.14、销毁顺序表
3.15、顺序表数据展示
4、总结
1、线性表
1.1、线性表的概念:
一段有n个元素的有限序列。有且只有一个开始结点,有且只有一个结束结点;除了开始结点外,其余结点只有唯一一个直接前驱;除了结束结点外,其余结点只有唯一一个直接后继,可以表示成{ a1,a2,a3...an-1,an }。
1.唯一的头
2.唯一的尾
3.除首尾结点外,其余结点只有唯一的前驱和后继
4.简而言之,表中元素的逻辑关系是一个接一个的。例如数组,字符串,栈和队列等。
1.2、线性表数据的存储方式:
线性表按照其数据的存储方式分为两种:
1.顺序表:数据结点之间,逻辑相邻,物理也相邻。
2.链表:数据结点之间,逻辑相邻,物理不一定相邻。
顺序表的所有存储单元由我们一次性malloc()获得,如数组一般,在扩容时是通过realloc()函数,所以其在内存中肯定是相邻的(不清楚为何相邻的读者可以点击查看动态内存开辟)。
链表的结点是在我们需要一个时,malloc()一个,如果第 n 个结点所在内存之后的大片内存都被其他程序占用着,那系统只能去其他地方找空闲内存为第 n+1 个结点开辟结点了,所以链表的结点在内存中可能相邻,也可能相隔很远。
注意:
此处的逻辑相邻指的是:数据的逻辑关系是一个接一个串联起来的。物理相邻指的是:数据在内存中存放的地址是相邻的(逻辑地址),并不是真正意义上的的物理地址相邻,例如数组,其每一个单元格的在内存中的地址(逻辑地址)是连续的。(没看懂或者有兴趣了解逻辑地址和物理地址的读者可以去搜索了解,或搜索“地址映射”)。
2、顺序表
2.1、概念
顺序表:用一组地址连续的存储单元依次存储线性表的数据元素,如数组一般。例如糖葫芦:

2.2、顺序表的存储结构
//顺序表存储空间的初始分配量
#define LIST_INIT_SIZE 10
//顺序表存储空间一次扩容的空间增量
#define LISTINCREMENT 5
typedef int ELEM_TYPE; //数据类型泛化
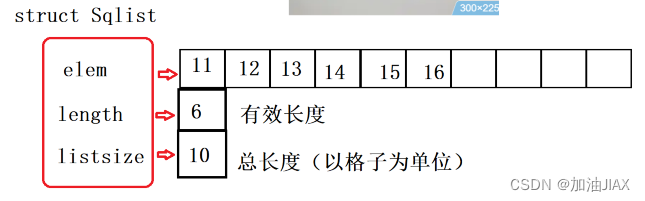
typedef struct Sqlist {
ELEM_TYPE* elem; //存储空间基址
int length; //有效数据长度
int listsize; //空间总大小
}Sqlist,*PSqlist;
1、对存储空间的初始大小(能保存多少个相同类型数据元素(单元格个数)),和一次扩容扩大多少存储单元格进行宏定义。方便后规范使用,可有可无。
2、进行数据类型泛化。后续代码对存储空间的开辟也是在此基础之上。此时,将int 型重命名为ELEMTYPE,后续保存存储空间起始地址的指针也以ELEMTYPE型定义,也就是 int* 型;为存储空间开辟内存时,一个单元格大小也就是一个ELEMTYPE型数据的大小(int型,4字节)。如果我们想另外使用这段代码开辟顺序表,保存double型数据,就只需要将数据类型泛化时的 int 改为 double 就行了(typedef int ELEMTYPE => typedef double ELEMTYPE)。
3、我们需要一个结点来保存顺序表这一段存储空间起始地址,如数组名一般,所以使用一个指针来保存。并且顺序表元素的访问和数组一样可以直接通过 顺序表名.elem[ i ] 来访问。
4、存储空间刚被开辟出来时,其中的值是随机值。我们无法判断我们是否在这个单元格存储过东西,或者其中的值是否有效。所以我们定义一个成员变量 length 用来保存有效数据个数,并且我们存储数据元素时,是从存储空间的起始位置开始,按顺序往后一个接一个保存,就如从数组的零号下标开始向后保存数据。每存一个数据,length+1;顺序表 length 长度之外的数据,我们视为无效数据。
5、我们为了避免浪费资源,起初开辟的存储空间大小有限。当要存储数据的个数大于存储空间的大小时,我们就需要扩容,防止非法访问。所以,我们使用成员变量 listsize 标记我们开辟了多大的存储空间,当length == listsize时,就意味着我们开辟的空间被存满了,需要扩容。
6、从上面的分析,我们可以看出来,顺序表具有三种属性:存储空间、有效元素个数、空间总大小。这三个属性互相之间有关联,所以我们才使用结构体类型保存这三种不同的属性(成员变量),将这三个属性合为一体,组成线性表。
7、struct Sqlist 为结构体类型,在上述代码中,我们对结构体类型重命名为 Sqlist ,结构体指针类型重命名为 PSqlist 。
3、顺序表的各种操作函数实现
函数的形参参数都是结构体指针。因为我们要对结构体本身进行各种操作,进行修改,所以不能只进行值传递,必须要进行地址传递。"->" 为结构体指针成员变量访问符,具有解引用功能,所以在函数中对解引用的指针进行操作,相当于对顺序表本身进行操作。
3.1、顺序表初始化
因为我们想达到可扩容的目的,普通数组无法满足需求,所以使用动态内存开辟,从堆区内申请一段内存来使用,可realloc()扩容。
//初始化
//将顺序表变量传指针进函数
void Init_Sqlist(PSqlist sq)
{
assert(sq!=NULL);//安全性处理
//开辟顺序表的数据存储空间
sq->elem = (ELEM_TYPE*)malloc(LIST_INIT_SIZE * sizeof(int));
//断言开辟成功,如果不成功就报错
assert(sq->elem != NULL);
//起始有效元素个数为0
sq->length = 0;
//顺序表存储空间的单元格数
sq->listsize = LIST_INIT_SIZE;
}
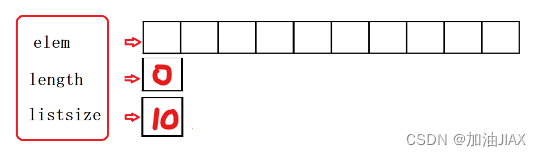
初始化完成后,顺序表可表示如下:(虽然此时将顺序表的单元格被表示为空白,但其中还是有初始化时产生的随机值,空白只代表没有有效数据)
3.2、顺序表判满函数
在向顺序表插入数据前,我们需要判断顺序表是否被存满,如果存满就要扩容。
判满操作,通过比较 length 与 listsize 是否相等就可以达到目的:如果 length==listsize,就意味着顺序表存满;并且length不会大于 listsize,因为我们在每次向表中存入数据时,都要进行判满,只要顺序表存满,就扩容,listsize就变大。
bool IsFull(PSqlist sq) {
assert(sq!=NULL);//安全性处理
return sq->length == sq->listsize;
}
3.3、顺序表扩容函数
void Inc(PSqlist sq) {
//计算扩容后的总大小(单元格总数)
int len = sq->listsize + LISTINCREMENT;
//扩容 //扩容失败返回NULL
//使用一个新指针获取扩容后的内存空间地址
//防止扩容失败,导致原内存空间丢失
ELEM_TYPE* p = (ELEM_TYPE*)realloc(sq->elem, len * sizeof(ELEM_TYPE));
//断言扩容成功,否则报错
assert(p != NULL);
//将扩容后的空间起始地址重新赋给sq
sq->elem = p;
//修改记录的总大小
sq->listsize = len;
}
3.4、插入数据--头插
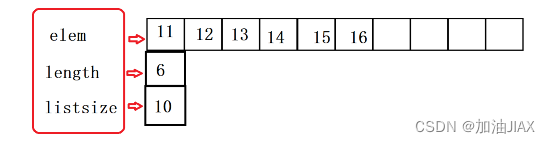
假设,顺序表已存储有如上数据,如果我们想在顺序表的头部(首部),也就是第0个单元格插入一个数据10,我们不能将10直接赋值给 elem[ 0 ],这就覆盖了原本的数据,所以我们要将插入前顺序表的所有元素向后移动一位,腾出第0位的位置,再将10放入。同时,将length+1。
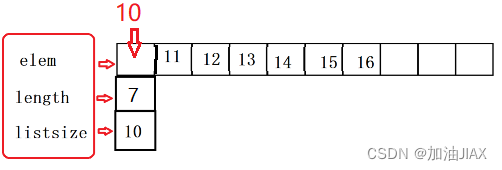
bool Insert_head(PSqlist sq, ELEM_TYPE val) {
assert(sq != NULL);//安全性处理
//满则扩容
if (IsFull(sq)) Inc(sq);
//从后往前将元素依次往后挪一位
for (int i = sq->length; i > 0; --i) {
sq->elem[i] = sq->elem[i - 1];
}
//插入
sq->elem[0] = val;
sq->length++;
return 1;
}
3.5、插入数据--尾插

尾插时,因为末尾的后一位是无效数据,所以可以直接在判满后,将数据直接存入sq->elem[sq->length] 位,再将sq->length++。
bool Insert_tail(PSqlist sq, ELEM_TYPE val) {
assert(sq != NULL);//安全性处理
//满则扩容
if (IsFull(sq)) Inc(sq);
//插入
sq->elem[sq->length] = val;
sq->length++;
return 1;
}
3.6、插入数据--按位置插
给定一个位置pos下标,将数据插入到pos下标处。判定pos需要 0 =< pos <=length,超出这个范围的,我们认为其无效。
按位置插,与头插类似。头插是将0号下标及后续的有效元素都向后挪一位;按位置插入,就是将pos下标及以后的有效数据都向后挪一位。
bool Insert_pos(PSqlist sq, int pos, ELEM_TYPE val) {
assert(sq != NULL);
if (pos > sq->length || pos < 0) return 0;
if (IsFull(sq)) Inc(sq);
//从
for (int i = sq->length; i > pos; --i) {
sq->elem[i] = sq->elem[i - 1];
}
sq->elem[pos] = val;
sq->length++;
return 1;
}
依此分析,当pos==0时,其实就是头插,当pos==length时,就是尾插。所以头插和尾插函数可以用按位置插函数特殊实现。
3.7、顺序表判空函数
在删除顺序表数据元素之前,我们需要判断顺序表中是否有数据,如果没有数据,就不能执行删除的动作。
顺序表中没有数据,就是没有有效数据,也就是sq.length==0。所以,我们只需要判断length是否等于0。
bool IsEmpty(PSqlist sq) {
//0为假,非0为真
return sq->length;
}
3.8、删除数据--按位置删
在删除一个结点的数据后,如果其后还有效数据,我们就要将后续所有有效数据向前挪动一位。
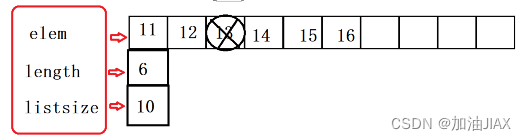
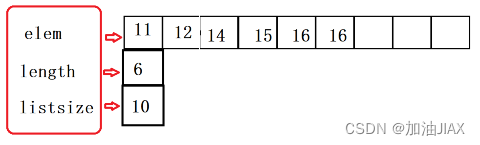
因为最终还是要将后续数据元素向前移动,所以,删除数据,我们可以直接看作将后续数据元素向前移动一位。再将数据有效个数-1,直接忽略最后一位16,将其视作无效数据。
bool Del_pos(PSqlist sq, int pos) {
assert(sq != NULL);
//如果顺序表为空,或者pos越界,删除失败
if (IsEmpty(sq) || pos >= sq->length || pos < 0) return 0;
//从pos位置往后,将数据依次往前挪一位
for (int i = pos; i < sq->length - 1; ++i) {
sq->elem[i] = sq->elem[i + 1];
}
sq->length--;
return 1;
}
3.9、删除数据--头删
与插入数据一样,如果待删除的数据位置为0号下标位置(pos==0),就是头删。所以可以直接调用按位置删函数。
bool Del_head(PSqlist sq) {
return Del_pos(sq, 0);
}
3.10、删除数据--尾删
待删除位置为 length-1 时,就是尾删。
bool Del_tail(PSqlist sq) {
return Del_pos(sq, sq->length - 1);
}
3.11、查找数据
找到数据值 val 在顺序表中第一次出现的位置(下标)。遍历顺序表,如果没有就返回-1。
int Search(PSqlist sq, ELEM_TYPE val) {
assert(sq != NULL);
for (int i = 0; i < sq->length; ++i) {
if (val == sq->elem[i]) return i;
}
return -1;
}
3.12、删除数据--按值删除
找到数据值 val 在顺序表中第一次出现的位置,将其删除(按位置删)。
bool Del_val(PSqlist sq, ELEM_TYPE val) {
assert(sq != NULL);
int index = Search(sq, val);
if (index == -1) return 0;
return Del_pos(sq, index);
}
3.13、清空顺序表
//清空(将数据清空,认为没有有效值)
void Clear(PSqlist sq) {
sq->length = 0;
}
3.14、销毁顺序表
将开辟的存储空间free()掉,再将数据有效个数与存储空间总大小置为0。
//销毁(将数据存储空间都释放掉)
void Destory(PSqlist sq) {
free(sq->elem);
sq->length = sq->listsize = 0;
sq -> elem = NULL;
}
3.15、顺序表数据展示
按照有效数据个数,将数据依次打印。
void Show(PSqlist sq) {
for (int i = 0; i < sq->length; ++i) {
printf("%-3d", sq->elem[i]);
}
}
4、总结
1、顺序表如数组一般,在内存中逻辑地址连续,并且与数组一样能够通过 [ ] 解引用,访问数据。
2、顺序表保存的数据元素都相同,所以在进行数据类型泛化后,只要将被泛化(重命名为ELEMTYPE)的数据类型改变,就可以使用原代码创建线性表,保存其他类型的数据。
3、对顺序表进行操作的函数都需要将顺序表的指针传入函数,对指针进行解引用,达到对顺序表进行修改的目的。
4、顺序表的操作需要挪动元素。插入元素时,向后挪动;删除时,想前挪动。时间复杂度平均为O(n),效率不高。但是,如果在尾部操作,就不需要挪动元素,效率极高(O(1))。
5、顺序表的使用场景:
适合的场景:支持直接访问(下标访问);插入和删除操作主要集中在尾部。
不适合的场景:在头部和中间位置,插入和删除操作较多;频繁的扩容,扩容代价高。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)