调用sklearn模型的时候 报错“Unknown label type: ‘continuous’ “的解决办法
刚刚掌柜在进行模型预测的时候遇到这样的报错:

为什么会这样呢?掌柜搜过类似问题的解法,发现在StackOverflow上面有个解释的很清楚:

原来是因为目标列是真实地数字,不能作为分类问题的标签进行运算。那么问题又来了:为什么不能作为分类标签呢? 再看下面那句话,其实也是sklearn官方文档中地原话:
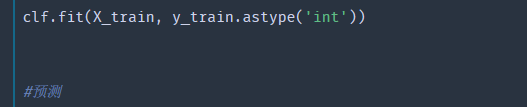
 哦,原来在用sklearn做分类任务的时候,y 应该是整数或者字符串型的向量。至此,这个问题终于得到解答😀,下面解决的办法就很简单了,直接在y输入变量的后面加上转换数据类型为int或者string即可:
哦,原来在用sklearn做分类任务的时候,y 应该是整数或者字符串型的向量。至此,这个问题终于得到解答😀,下面解决的办法就很简单了,直接在y输入变量的后面加上转换数据类型为int或者string即可:
参考资料:
sklearn官方文档
StackOverflow:Unknown label type: ‘continuous’
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)