前言
算法的效率
虽然计算机能快速的完成运算处理,但实际上,它也需要根据输入数据的大小和算法效率来消耗一定的处理器资源。要想编写出能高效运行的程序,我们就需要考虑到算法的效率。
算法的效率主要由以下两个复杂度来评估:
时间复杂度:评估执行程序所需的时间。可以估算出程序对处理器的使用程度。
空间复杂度:评估执行程序所需的存储空间。可以估算出程序对计算机内存的使用程度。
设计算法时,一般是要先考虑系统环境,然后权衡时间复杂度和空间复杂度,选取一个平衡点。不过,时间复杂度要比空间复杂度更容易产生问题,因此算法研究的主要也是时间复杂度,不特别说明的情况下,复杂度就是指时间复杂度。
本文只分析时间复杂度
什么是时间复杂度
了解时间复杂度之前,先了解时间频度
时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
在时间频度不相同时,时间复杂度有可能相同,如T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n2)。
一句话:T(n)就是时间频度,表示算法执行的次数
问题:T(n)随着n的改变而改变
时间复杂度
时间复杂度 在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
时间复杂度怎么算
基本操作即算法中的每条语句(以;号作为分割),语句的执行次数也叫做语句的频度。在做算法分析时,一般默认为考虑最坏的情况。
1、计算出每条语句执行次数T(n)
求出代码中每条语句执行的次数
在做算法分析时,一般默认为考虑最坏的情况。
2、计算出T(n)的数量级
求T(n)的数量级,只要将T(n)进行如下一些操作:
忽略常量
低次幂和最高次幂的系数
令f(n)=T(n)的数量级。
3、用大O来表示时间复杂度
当n趋近于无穷大时,如果lim(T(n)/f(n))的值为不等于0的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n))。
只保留最高阶项,最高阶项存在且不是1,则去除与这个项相乘的常数。
前面提到的时间频度T(n)中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律,为此我们引入时间复杂度的概念。一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数,记作T(n)=O(f(n)),它称为算法的渐进时间复杂度,简称时间复杂度。
T(n)/f(n)的极限值为不等于零的常数什么意思?
首先你要知道T(n)是f(n)忽略常量、低次幂和最高次幂的系数。只保留能代表数量级的项。
所以T(n)肯定是小于等于f(n)的
那么,如果T(n)/f(n)的极限值等于0,那么就是说f(n)的增长趋势比T(n)大太多,那么就说明他们俩不是一个数量级的。
不是一个数量级什么意思呢?
就好比你玩LOL,你是黄铜1,他是黄铜3,虽然你比他高一点,但你们俩还是黄铜,是一个数量级的。。。大多数时候,通过段位就能判断你的水平,不会在意是你在你段位是1还是5。这里算法的时间复杂度也是一样,只保留核心项,其他的都去掉。
什么时候不是一个数量级呢?等你上白银或者黄金的时候,那就不是一个数量级的。。。
一个算法的执行时间与哪些因素有关
衡量一个算法的好坏不能简单的从这个算法所花费的时间来衡量。因为这个时间受多种因素影响。一般来说一个算法花费的时间有以下4点
- 计算机执行的速度->硬件层面
- 编译产生的代码质量->软件层面
- 算法的好坏(算法使用的策略)
- 问题规模
在给定软硬件环境下,其实就是你在自己电脑上写算法的时候,算法执行时间只受算法本身的好坏和要处理的问题的规模影响。这样就将4个影响因素减少为2个,简化了问题。
我们继续分析,
给定问题规模n之后,优秀的算法可能执行几次就搞定了,一般的算法可能执行很多很多次才搞定;
当给定算法时,问题规模n很小时,可能执行几次就搞定,而n很大时,就得执行很多次了。
所以算法优劣和问题规模n改变时,执行次数(基本操作数)将改变,所以执行次数就是算法优劣和问题规模n的函数。
既然执行时间受算法好坏和问题规模n的影响,那么执行时间就是它俩的函数。
要比较两个函数的增长情况,最好的办法是比较函数的一阶导,这样最精确,但是考虑到很多时候只需要大体了解算法的优劣就可以了,所以我们就直接考察对增长速度影响最大的一项,这一项就是函数的最高阶数。为了说明最高阶数对函数增长影响最明显,我们看两幅图。
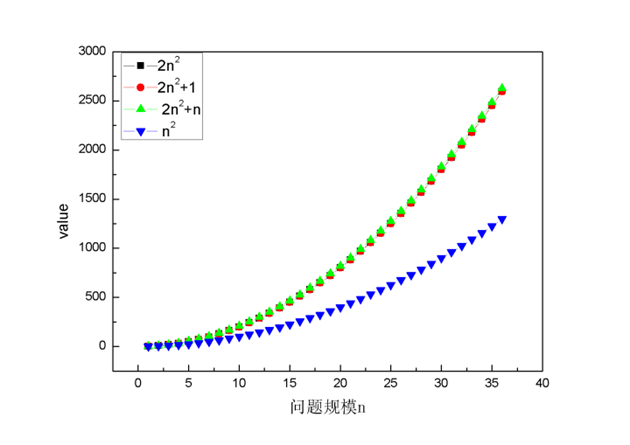
图中4条曲线分别表示4种不同的执行次数表达式,从图中可以看出,只要最高项的阶数相同,4种表达式值受其他项的影响很小,随着n增大,几乎可以忽略不计,甚至可以忽略与最高项相乘的常数。
既然可以只考虑最高项的阶数,以简化问题,达到估算的目的,为何不这样做呢?
那总得给这种情况一个恰当的表示方式吧?和其他领域一样,还得用符号来表示,这个符号就是大名鼎鼎的大O符号。
推导大O阶有一下三种规则:
-
用常数1取代运行时间中的所有加法常数
- 只保留最高阶项
- 去除最高阶的常数
一般我们我们评估一个算法都是直接评估它的最坏的复杂度。
时间复杂度是一个量级的概念,而不是具体的值,比如O(5n)的量级是n,因为这个时间复杂度函数内最高量级是变量n的一次方
常见时间复杂度
下图来自维基百科

常数级别O(1)

O(1):算法复杂度和问题规模无关。换句话说,哪怕你拿出几个PB的数据,我也能一步到位找到答案。
理论上哈希表就是O(1)。因为哈希表是通过哈希函数来映射的,所以拿到一个关键字,用哈希函数转换一下,就可以直接从表中取出对应的值。和现存数据有多少毫无关系,故而每次执行该操作只需要恒定的时间(当然,实际操作中存在冲突和冲突解决的机制,不能保证每次取值的时间是完全一样的)。
执行次数
N=10,大约执行1次
N=100,大约执行1次
N=1000,大约执行1次
N=10000,大约执行1次
对数级别O(logN)
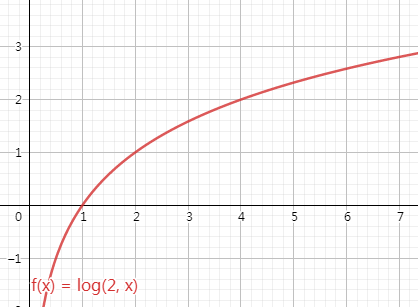
Tips:log的底数在大O符号的中是省去的。常见的底数为2
O(logN):算法复杂度和问题规模是对数关系。换句话说,数据量大幅增加时,消耗时间/空间只有少量增加(比如,当数据量从2增加到2^64时,消耗时间/空间只增加64倍)
执行次数
底数为2的情况
N=10,大约执行3次
N=100,大约执行7次
N=1000,大约执行10次
N=10000,大约执行13次
代码
int number = 1; // 语句执行一次
while (number < n) { // 语句执行logn次
// 这里的2是log的底数
// 底数在大O符号中是省去的
number *= 2; // 语句执行logn次
}
线性级别O(N)
O(n):算法复杂度和问题规模是线性关系。换句话说,随着样本数量的增加,复杂度也随之线性增加
执行次数
N=10,大约执行10次
N=100,大约执行100次
N=1000,大约执行1000次
N=10000,大约执行10000次
代码
int i =0; // 语句执行一次
while (i < n) { // 语句执行n次
print(i); //语句执行n次
i++; // 语句执行n次
}
这个算法中代码总共执行了 3n + 1次,根据规则 2->3,因此该算法的时间复杂度是O(n)。
线性对数级别O(NlogN)
O(logn)的算法复杂度,典型的比如二分查找。设想一堆试卷,已经从高到底按照分数排列了,我们现在想找到有没有59分的试卷。怎么办呢?先翻到中间,把试卷堆由中间分成上下两堆,看中间这份是大于还是小于59,如果大于,就留下上面那堆,别的丢掉,如果小于,就留下下面那堆,丢掉上面。然后按照同样的方法,每次丢一半的试卷,直到丢无可丢为止。
假如有32份试卷,你丢一次,还剩16份 ,丢两次,还剩下8 份,丢三次,就只剩下4份了,可以这么一直丢下去,丢到第五次,就只剩下一份了。而  。也就是我们一次丢一半,总要丢到只有一份的时候才能出结果,如果有n份,那么显然我们就有:
。也就是我们一次丢一半,总要丢到只有一份的时候才能出结果,如果有n份,那么显然我们就有:

也就是大约需要  次,才能得出“找到”或者“没找到”的结果。当然你说你三分查找,每次丢三分之二可不可以?当然也可以,但是算法复杂度在这里是忽略常数的,所以不管以2为底,还是以什么数为底,都统一的写成 log(n)的形式。
次,才能得出“找到”或者“没找到”的结果。当然你说你三分查找,每次丢三分之二可不可以?当然也可以,但是算法复杂度在这里是忽略常数的,所以不管以2为底,还是以什么数为底,都统一的写成 log(n)的形式。
理解了这一点,就可以理解快速排序为什么是 O(nlogn)了。比如对一堆带有序号的书进行排序,怎么快呢?就是随便先选一本,然后把号码大于这本书的扔右边,小于这本书的扔左边。因为每本书都要比较一次,所以这么搞一次的复杂度是 O(n),那么快排需要我们搞多少次呢?这个又回到了二分查找的逻辑了,每次都把书堆一分为二,请问分多少次手里才能只剩下一本书呢?答案还是 logn。而从代码的角度来说,在到达大小为一的数列之前,我们也是需要作 logn次嵌套的调用。
执行次数
底数为2的情况
N=10,大约执行33次
N=100,大约执行664次
N=1000,大约执行9966次
N=10000,大约执行132877次
平方级别O(N^2)
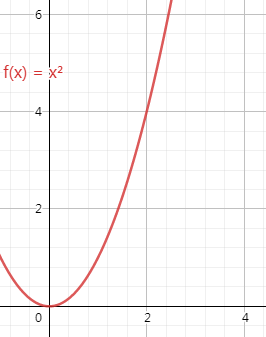
O(n^2)计算的复杂度随着样本个数的平方数增长。这个例子在算法里面,就是那一群比较挫的排序,比如冒泡等等。
执行次数
N=10,大约执行100次
N=100,大约执行10000次
N=1000,大约执行1000000次
N=10000,大约执行100000000次
代码
for (int i = 0; i < n; i++) { // 语句执行n次
for (int j = 0; j < n; j++) { // 语句执行n^2次
print('I am here!'); // 语句执行n^2
}
}
上面的嵌套循环中,代码共执行 2*n^2 + n,则f(n) = n^2。所以该算法的时间复杂度为O(n^2 )
指数级别O(2^N)
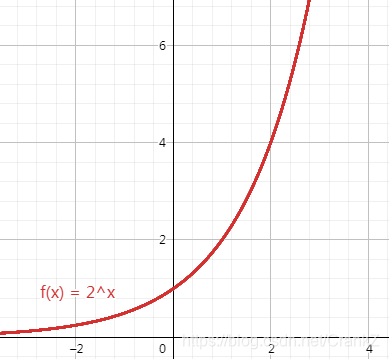
如果一个算法的运行时间是指数级的(exponential),一般它很难在实践中使用
执行次数
N=10,大约执行1024次
N=100,大约执行2^100次
N=1000,大约执行2^1000次
N=10000,大约执行2^10000次
排序算法计算
这里并不是详细讲排序算法,只讲他们的复杂度是什么算出来的。
来自:https://www.zhihu.com/question/21387264/answer/422740592
冒泡排序
对于数组中的每一个数,我们比较它和右边的邻居的大小关系,邻居小则交换。从数组的最右端开始,最后一个数(array[n - 1])没有右邻居,所以我们从倒数第二右(array[n - 2])开始,它最多跟最后一个数比较并交换 1 次;接下来是 array[n - 3],它右边有 2 个邻居,所以它最多比较并交换 2 次……以此类推,直到最左边的数 array[0],它右边有 n - 1 个邻居,所以它最多比较并交换 n - 1 次。综上所述,算法的总比较次数就是  。忽略系数,所以它具有
。忽略系数,所以它具有  的时间复杂度。
的时间复杂度。
选择排序。我们每次从数组中选出一个最小值并放在最左边。第一轮从 n 个数里选出一个最小值,所以我们需要挨个比较 n 个数;第二轮从 n - 1 个数里选出一个最小值,我们需要挨个比较 n - 1 个数……以此类推,算法的总比较次数就是  。忽略系数和低阶项,我们说它的时间复杂度是 。
。忽略系数和低阶项,我们说它的时间复杂度是 。
归并排序
这是一个分治的过程,并且我们通常使用递归来实现。为了分析递归,我们应该画出递归树,举例如下:
Split 0 8 7 6 5 4 3 2 1
Split 1 8 7 6 5 | 4 3 2 1
Split 2 8 7 | 6 5 | 4 3 | 2 1
Split 3 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1
------------------------------------------
Merge 0 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1
Merge 1 7 8 | 5 6 | 3 4 | 1 2
Merge 2 5 6 7 8 | 1 2 3 4
Merge 3 1 2 3 4 5 6 7 8
将整个归并排序分为分割和合并两个过程来看。
分割过程
对于分割过程(分割线以上),每分割一次,我们就会分别对左右两部分执行相同的逻辑,即递归调用这两部分。所以我们来看分割部分一共有多少次函数调用:split 0 层有 1 次函数调用;split 1 层是第 1 次分割,对左右两半分别调用 1 次函数,因此该层一共有 2 次函数调用;以此类推,split 2 层有 4 次调用、split 3 层有 8 次调用……所以整个分割过程一共调用了  次函数(首项为 1、公比为 2、末项为 n 的等比数列求和)。忽略系数和常数项,分割过程具有
次函数(首项为 1、公比为 2、末项为 n 的等比数列求和)。忽略系数和常数项,分割过程具有  的时间复杂度。
的时间复杂度。
合并过程
再来看合并过程(分割线以下)。对于两个排好序的子部分,将其合并需要对两个子部分中的每一个数逐一比较。因此,merge 0 层我们需要合并 8 组,每组只有一个数,不妨算作“逐一比较”1 次,所以该层的总比较次数为 8 次;类似地,merge 1 层有 4 组,组与组之间两两比较,该层的总比较次数为 4 x 2 = 8 次……以此类推,合并过程中每层都需要比较 n 次,总层数为  ,所以总比较次数就是
,所以总比较次数就是  。忽略底数和低阶项,我们就得到了合并过程的时间复杂度
。忽略底数和低阶项,我们就得到了合并过程的时间复杂度  。
。
所以对于整个归并排序,总时间复杂度为分割+合并,即  ,忽略低阶项,就是 。
,忽略低阶项,就是 。
快速排序
也是一个分治的过程。这里重点强调最坏复杂度 和平均复杂度 是怎么算出来的。快排的过程可以概括为,先从数组里随机选出一颗“钉子”(pivot),遍历整个数组,将这颗钉子放到自己应有的位置上,而且此时此刻,钉子左边那一半虽然还没排好序,但它们全部都比钉子小,同理钉子右边那一半全部都比钉子大但也还没排好序。接下来,我们分别对钉子的左右两部分执行刚才的逻辑,即递归调用快排过程,直到不能再分割为止。所以我们不难发现,随机选择的钉子就是整个快排最大的变数。
最差情况
Quick sort: worst case scenario
Layer 0 [8 7 6 5 4 3 2 1]
p
Layer 1 1 [8 7 6 5 4 3 2]
p
Layer 2 1 2 [8 7 6 5 4 3]
p
......
*p: the pivot
快排的最坏情况就是,假设我们每一次挑出来的钉子都非常不走运,该轮遍历完后这颗钉子恰好位于数组的一端,此时分别递归钉子的左右两边就会变成只能递归一边,因为另一边是空的。换言之,在这种次次不走运的极端情况下,每轮挪钉子的过程就退化成了一个选择排序。前面我们已经分析过选择排序的时间复杂度是 ,因此快排的最坏时间复杂度是 。
平均情况
Quick sort: average scenario
Layer 0 [11 10 9 8 7 6 5 4 3 2 1]
p
Layer 1 [5 4 3 2 1] 6 [11 10 9 8 7]
p p
Layer 2 [2 1] 3 [5 4] 6 [8 7] 9 [11 10]
p p p p
......
*p: the pivot
快排的平均情况就是,假设我们每一次挑出来的钉子不偏不倚,遍历完后正好位于数组的正中央,显然这一轮遍历了 n 个元素。接下来,分别递归钉子的左右两边,即分别遍历两组 n/2 个元素,该轮总计遍历了 2 x n/2 = n 个元素……以此类推,每次递归钉子都在正中间,每层我们都要遍历 n 个元素,每次递归都是均匀二分,那么就像上面的归并排序一样,一共会有 层,所以在这种情况下整个算法一共遍历 次,也就是 的时间复杂度。
堆排序
虽然总体复杂度也是 ,但它的建堆过程是 ,很多人在这里犯错。接下来我们用高一数学推导建堆过程的时间复杂度。
首先将原数组用堆结构表示出来,例如下图的二叉堆:
Layer 0 15
Layer 1 14 13
Layer 2 12 11 10 9
Layer 3 8 7 6 5 4 3 2 1
建堆(heapification)过程概括来讲,就是从当前堆的最后一个父节点开始,检查该父节点是否与其左右子节点满足堆序性(heap property),不满足则一路向下交换,并挨个对每一个父节点重复这个过程。从图中我们很容易看出 n 个元素组成的堆一共有  层。仔细观察不难发现,排位靠下的父节点,只需要较少的次数就能换到最下面;而靠上的父节点,则要交换更多次才能换到最下面。在最坏情况下,假设所有父节点都需要换到最下面,为方便起见我们令堆的总层数
层。仔细观察不难发现,排位靠下的父节点,只需要较少的次数就能换到最下面;而靠上的父节点,则要交换更多次才能换到最下面。在最坏情况下,假设所有父节点都需要换到最下面,为方便起见我们令堆的总层数  ,可得
,可得
Layer 0 有  个父节点,换到最底(最坏情况)需要交换
个父节点,换到最底(最坏情况)需要交换  次;
次;
Layer 1 有  个父节点,换到最底需要交换
个父节点,换到最底需要交换  次;
次;
……
倒数第二层有  个父节点,换到最底需要交换 1 次;
个父节点,换到最底需要交换 1 次;
最后一层全是叶子节点,不交换。
综上可得建堆过程的总交换次数

不难看出,这是一个我们在高中已经玩烂了的差比数列(等比x等差的数列),错位相减即可求得该数列的和:

以上两式相减得

![=-(t-1)+[2^1+2^2+...+2^{t-2}+2^{t-1}]](https://www.zhihu.com/equation?tex=%3D-%28t-1%29%2B%5B2%5E1%2B2%5E2%2B...%2B2%5E%7Bt-2%7D%2B2%5E%7Bt-1%7D%5D)

代入  可得建堆过程的总交换次数
可得建堆过程的总交换次数

忽略低阶项和常数项,建堆的时间复杂度为 。
nlogn,难道这是排序算法的极限了吗?
很遗憾,nlogn已经是比较排序算法的极限了。
具体可以看知乎的讨论https://www.zhihu.com/question/24516934
参考
https://blog.csdn.net/u010402786/article/details/51435735
https://juejin.im/post/58d15f1044d90400691834d4
https://www.zhihu.com/question/21387264
https://www.zhihu.com/question/20196775
https://blog.csdn.net/zolalad/article/details/11848739
https://www.cnblogs.com/gaochundong/p/complexity_of_algorithms.html
https://blog.csdn.net/u010402786/article/details/51435735