bnlearn官网推荐书目《Bayesian Networks With Examples in R》,下载了英文版pdf学习了一下,书还是比较浅显易懂的,没有读多少,暂时把自己看的部分整理+翻译到这里留存。欢迎大家交流
〇、 pdf下载地址
http://www.allitebooks.org/
Jesus!这么好的网站我怎么没有早点遇到!里面有各种各样的Turing或者O’Reilly出版社的pdf,其中就包含这一本Bayesian Networks With Examples in R。
阅读下文注意:
-
引用框中所有文字均是自翻的原文的翻译
-
引用框外的文字是博主自己的注释/理解/ 废话
-
【】里面的为英文原文
- 所有内容均会贴上书目页码
- 部分会贴上英文原文
一、例子介绍(P1)
下文举例子用的例子是“火车使用调查”这个例子,其目的是调查不同交通工具的使用模式,重点是汽车和火车。这些调查被用来评估不同社会群体的客户满意度,评估公共政策或城市规划。在我们当前的例子中,我们将Survey涉及的每个个体的以下六个离散变量展示出来:A代表年龄Age,S代表性别Sex,E代表教育水平高低Education,O代表职业Occupation,R代表居住的城市大小Residence,T代表个人偏爱的交通工具Travel。初始网络形状如下图:


二、概率表示(P7)
为了完成BN建模调查,我们现在将计算这些变量的联合概率分布。然而,直接使用全局分布是困难的;即使是像我们这样的小问题,其参数的数量也非常多。幸运的是,我们可以使用DAG中编码的信息将全局分布分解为一组更小的局部分布,每个分布对应一个变量。回想一下,弧表示直接依赖关系;如果有一条从一个变量到另一个变量的弧,则后者取决于前者。换句话说,没有弧连接的变量是条件独立的。所以可以分解如下:
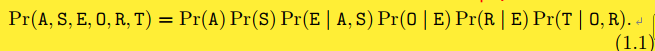
可见,每个变量只取决于它的父变量;它的分布是单变量的,并且有(相对)较少的参数。
注意下面这段话博主自己理解不是很准确,也是第一次见到(因为太菜了),贴出原文。
【Even the set of all the local distributions has, overall, fewer parameters than the global distribution. The latter represents a more general model than the former, because it does not make any assumption on the dependencies between the variables. In other words, the factorisation in Equation (1.1) defines a nested model or a submodel of the global distribution.】
总体而言,即使是所有局部分布的参数也比全局分布的少。后一种模型比前一种模型更一般,因为它没有对变量之间的依赖关系做出任何假设。换句话说,方程(1.1)中的因式分解定义了全局分布的一种嵌套模型或者说子模型。
三、Network Score (P17底部)
连续的打分与离散的有许多相似之处。
博主个人研究需要,重点在连续部分,但是由于连续和离散本是同根生,所以仍然要从离散看起。
与条件独立测试不同,网络测试的分数集中在DAG整体上,反映了DAG对数据的拟合程度。【They are goodness-of-fit statistics measuring how well the DAG mirrors the dependence structure of the data 】同样,有几个分数是常用的。其中一个是贝叶斯信息准则(BIC),在我们的Survey网络中采用了这种形式
Survey是文章中的一个例子,是一个贝叶斯网络结构。R类型为bn。可见 一、例子介绍(P1)

其中n为样本量;d为整个网络的参数个数(也就是21);dA、dS、dE、dO、dR、dT是与每个节点相关联的参数个数每个局部分布均为正态分布
在R中可以用如下方式调用 
或许你注意到了第二句代码中 iss = 10 这个参数,ISS是imaginary sample size的缩写,它的背景是:(我们认为)分配给先验分布的权重与一个假想样本的大小(也就是ISS)有关,对于小 的iss值或大的观测样本,bde和bic分数相似 。
ISS这个参数我也没用过,也没研究过,希望有大佬可以甩链接给我开开眼。QAQ。这里再搬一下前面的关于ISS的解释(见P12)。可能有些绕口。
后验分布的估计值是从条件概率表的均匀先验计算得到的。ISS值就是在控制先验分布和数据的权重,也就是先验分布的假想样本的大小。
ISS除以条件概率表中的单元格数(因为先验是均匀的的 ),然后用经验频率加权平均值来计算后验估计。
ISS的值通常被选得很小,通常在1到15之间,使先验分布很容易被数据支配。 而增大ISS会让后验分布变得平缓
四、 添加一条边对网络分值的影响(P19)
这一部分提到的函数arc.strength,对观察网络变化很有帮助,再夸一次bnlearn。
毫无疑问,从已经学习好的网络中移除任何一条弧都会让bic分数下降。我们可以用arc.strength这个函数来证明:当该弧被移除后,对网络分数造成的改变定义为弧的“strength”。

很显然,上面的网络和下面那个网络相比,上面的那个网络才是好的,因为它的acr.strength都是负数,也就是说去掉这个边会使网络整体的bic打分降低