一、 前期准备工作
step1:安装JDK1.8
关于jdk的安装比较简单,不过需要注意配置环境变量
step2:安装zookeeper单机版
因为kafka的运行需要在zookeeper的基础上进行,因此我们只需要简单的安装一个单机版的zookeeper即可。
目录结构如下:
- E:\zookeeper\data
- E:\zookeeper\zookeeper-3.4.12
1. 下载zookeeper 3.4.12 下载地址
2. 解压缩即可,具体的存放位置是E:\zookeeper\zookeeper-3.4.12
3. 进入目录E:\zookeeper\zookeeper-3.4.12\conf 对配置文件进行修改,复制zoo_sample.cfg文件并重命名为zoo.cfg,添加如下代码。
dataDir=e:\\zookeeper\\data
server.1=your IP:2888:3888
4.在bin文件夹下双击zkServer.cmd启动zookeeper
5.将bin文件夹目录添加到系统path中
step3: 安装Gradle-5.4
1 下载gradle 下载地址 ,注意选择binary-only
2 解压缩即可,并将bin文件夹目录添加到系统path中
step4:安装scala-2.11.12
1.下载scala下载地址,注意windows安装可以下载.msi文件格式的,下载之后根据提示直接安装(类似于普通app安装手法)
2. 将bin文件夹目录添加到系统path中
二、 将kafka源代码部署到编辑器IDEA并测试
step1:将kafka源码部署到IDEA
本次使用的编辑器是IntelliJ IDEA编辑器,使用的具体方法直接从git上克隆源代码。
具体的克隆源代码方法参考博客
然后在IDEA编辑器Terminal中执行:gradle idea
当然也可以自己离线下载源码包,然后进入源码根目录,执行命令gradle idea也可以,最后将编译好的文件导入IDEA即可。
导入IDEA之后的目录结构如下所示:

源码最主要的部分是core模块的内容
| 模块名 |
说明 |
| admin |
kafka的管理员模块,操作和管理其topic,partition相关,包含创建,删除topic,或者拓展分区等。 |
| api |
主要负责数据交互,客户端与服务端交互数据的编码与解码。 |
| cluster |
这里包含多个实体类,有Broker,Cluster,Partition,Replica。其中一个Cluster由多个Broker组成,一个Broker包含多个Partition,一个Topic的所有Partition分布在不同的Broker中,一个Replica包含都个Partition。 |
| common |
这是一个通用模块,其只包含各种异常类以及错误验证。 |
| consumer |
消费者处理模块,负责所有的客户端消费者数据和逻辑处理。 |
| controller |
此模块负责中央控制器的选举,分区的Leader选举,Replica的分配或其重新分配,分区和副本的扩容等。 |
| coordinator |
负责管理部分consumer group和他们的offset。 |
| log |
这是一个负责Kafka文件存储模块,负责读写所有的Kafka的Topic消息数据。 |
| message |
封装多条数据组成一个数据集或者压缩数据集。 |
| metrics |
负责内部状态的监控模块。 |
| network |
该模块负责处理和接收客户端连接,处理网络时间模块。 |
| security |
负责Kafka的安全验证和管理模块。 |
| serializer |
序列化和反序列化当前消息内容。 |
| server |
该模块涉及的内容较多,有Leader和Offset的checkpoint,动态配置,延时创建和删除Topic,Leader的选举,Admin和Replica的管理,以及各种元数据的缓存等内容。 |
| tools |
阅读该模块,就是一个工具模块,涉及的内容也比较多。有导出对应consumer的offset值;导出LogSegments信息,以及当前Topic的log写的Location信息;导出Zookeeper上的offset值等内容。 |
| utils |
各种工具类,比如Json,ZkUtils,线程池工具类,KafkaScheduler公共调度器类,Mx4jLoader监控加载器,ReplicationUtils复制集工具类,CommandLineUtils命令行工具类,以及公共日志类等内容。 |
step2: 对Kafka源码编译执行
1.首先双击E:\zookeeper\zookeeper-3.4.12\bin目录下的zkServer.cmd启动zookeeper(不能关闭执行框,否则就关闭服务了),执行结果如下。
2. 在idea中安装scala插件,Settings->plugins->scala 查看版本是2018.2.11,确保gradle.properties配置文件中的scalaVersion与安装的一致
3. 在kafka服务端使用log4j输出日志,启动前需要把log4j.properties配置文件放置到core\src\main\scala路径下,如果编译之后还是无法打印log信息,将文件在复制一份到core\out\production\classes\目录下,然后运行程序,这样才能正确输出日志信息,此log4j.properties文件可以从config目录中获取。
4. 修改kafka/config/server.properties文件,添加或修改如下两处代码。
#自己选择一个合适的输出log的文件夹即可,注意在window系统下新建的文件夹最好不要命名带空格,例如"IDEA workspace" ,中间有空格可能会导致IDEA发生java.nio.file.NoSuchFileException: F:IDEA ,其实是命名当中的空格后面的内容没有识别才会出现文件无法找到的错误,被坑了,谨记
log.dirs=F:\\IDEA\\log
#请自己将你本机的IP地址填入
zookeeper.connect=your IP:2181
5 配置run/debug configuration
点击run->run/debug configrations或者edit configrations
点击+号,选择Application
进行如下的配置:
(1)启动kafka系统的配置

(2)创建topic的配置

(3)console口生产数据的配置

(4)console口消费数据的配置

- 点击IDEA的
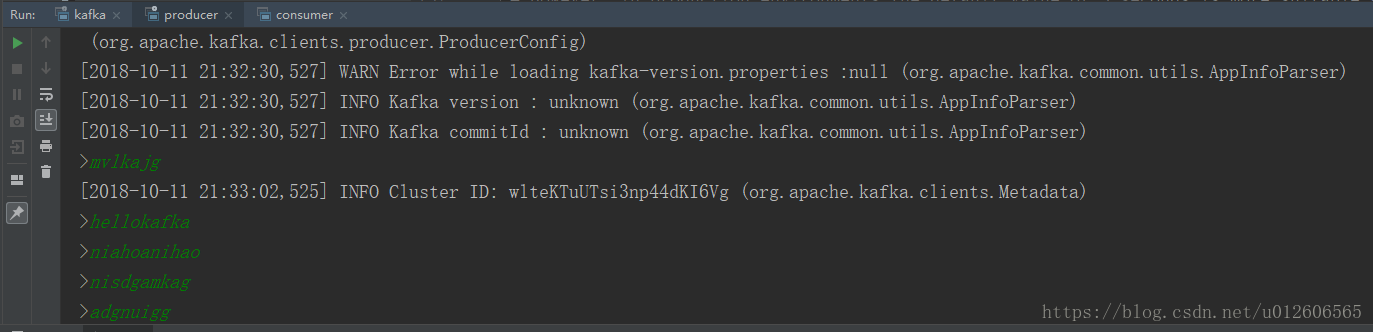
run,分别执行kafka、consumer、producer,同时在producer的控制台中输入数据,可以在consumer的控制台中收到。

三、 将修改过的Kafka源代码发布成binary 版本
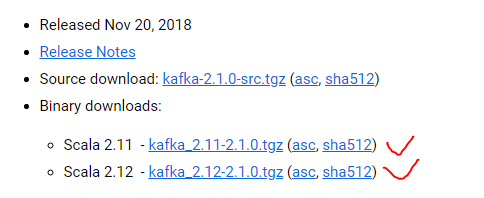
通常我们在linux运行kafka集群,使用的是binary版本,分别分为Scala2.11和Scala2.12版本的,如下图所示
step1:执行命令
在IDEA编辑器Terminal中执行:
gradle wrapper-
gradlew releaseTarGz或者./gradlew releaseTarGz
gradle wrapper命令:
下载 wrapper 包,命令执行成功后,会在 kafka 源码包的 gradle 目录下生 成一个 wrapper 目录,其中包括gradle-wrapper.jar和gradle-wrapper.properties两个文件
gradlew releaseTarGz命令:
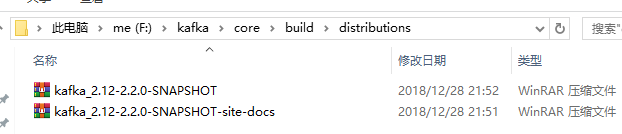
编译完之后将会在core/build/distributions/里面生成 kafka_2.12-2.2.0-SNAPSHOT.tgz 压缩包文件,这个和从网上下载的一样,可以直接用。
四、错误总结
错误一
出现:SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
解决:参考错误提示网址
具体做法:
1.下载相应的jar包,slf4j-log4j12.jar + Log4j.jar
2.导入jar包
具体的IDEA操作如下:
(1)File -> Project Structure -> Modules
(2)找到 core,core_main,打开 dependencies,点击 +,添加 sl4j-log4j12.jar、log4j. jar
错误二
出现:在producer的控制台上输入但是在consumer上没有收到消息
解决:端口和防火墙的问题
具体做法:
1.保证计算机的防火墙关闭
2.在设置run/debug configurations的时候需要保证端口相同,这个可以自己试试
错误三
出现:java.nio.file.NoSuchFileException: F:IDEA
解决:windows项目文件夹命名中带有空格
具体过程:原先的windows项目命名是IDEA worksapce,然后执行kafka的时候发现出现错误,并且提示找不到文件,因此将windows项目重命名为IDEA,再次执行,启动成功。
建议:文件夹的命名尽量使用英文并且不要带空格等不易识别的字符
错误四
出现:执行源码(即第二模块下的step2的第五步)出现错误,消费者无法执行
解决:这个问题与错误二类似,是填写的run/debug configures有问题
具体过程:请注意新版本的kafka和旧版本的kafka使用的命令是不一样的,例如旧版本的消费者使用--zookeeper参数指定zookeeper的地址,但是对于新版本的消费者需要使用--bootstrap-server参数指定broker的主机名和端口。
建议:关注kafka版本变化,使用对应版本的命令和功能。
错误五
出现:在ubuntu16.04上执行kafka_2.12-2.2.0-SNAPSHOT,出现如下错误
-bash: ./kafka-server-start.sh: /bin/bash^M: 解释器错误: 没有那个文件或目录
解决:参考博客,可以使用该博客的方法解决,但是以后会出现很多这样的情况,最后决定将所有的项目重新迁移到ubuntu系统上进行
具体过程:这个文件在Windows 下编辑过,在Windows下每一行结尾是\n\r,而Linux下则是\n
错误六
出现:将项目迁移到ubuntu系统上在idea编辑器上进行编译,执行命令gradle idea的时候出现如下错误
lala@lala-Lenovo:~/test/kafka$ gradle idea
To honour the JVM settings for this build a new JVM will be forked. Please consider using the daemon: https://docs.gradle.org/2.10/userguide/gradle_daemon.html.
FAILURE: Build failed with an exception.
* Where:
Build file '/home/lala/test/kafka/build.gradle' line: 57
* What went wrong:
A problem occurred evaluating root project 'kafka'.
> Failed to apply plugin [id 'org.owasp.dependencycheck']
> Could not create task of type 'Analyze'.
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output.
BUILD FAILED
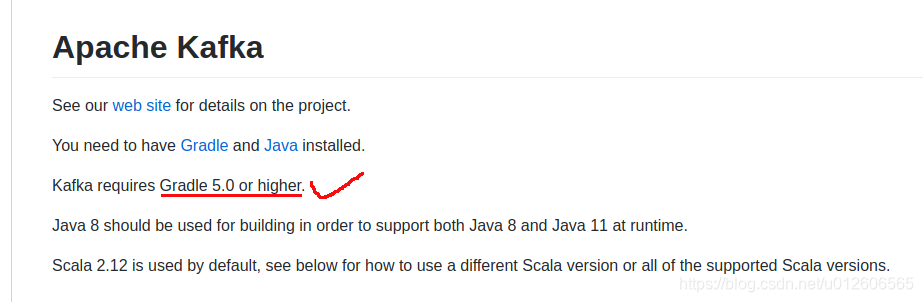
出现这个的原因是在ubuntu上安装的gradle版本太低(使用命令sudo apt-get install gradle,安装的是2.7版本),但是kafka要求(参照)5.0以上,因此重新安装了gradle,执行成功
错误七
出现:执行run-kafka时候(即第二模块下的step2的第6步),出现错误如下
log4j:ERROR setFile(null,true) call failed.
java.io.FileNotFoundException: /logs/server.log (没有那个文件或目录)
at java.io.FileOutputStream.open0(Native Method)
at java.io.FileOutputStream.open(FileOutputStream.java:270)
.......(省略)
at kafka.utils.Logging.$init$(Logging.scala:47)
at kafka.Kafka$.<init>(Kafka.scala:30)
at kafka.Kafka$.<clinit>(Kafka.scala)
at kafka.Kafka.main(Kafka.scala)
log4j:ERROR Either File or DatePattern options are not set for appender [stateChangeAppender].
解决:参考stack overflow
将log4j.propertties中有关路径的地方改成绝对路径即可
log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.kafkaAppender.File=${kafka.logs.dir}/logs/server.log //更改此行
log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stateChangeAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.stateChangeAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/logs/state-change.log //更改此行
log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.requestAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.requestAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.requestAppender.File=${kafka.logs.dir}/logs/kafka-request.log //更改此行
log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.cleanerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.cleanerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.cleanerAppender.File=${kafka.logs.dir}/logs/log-cleaner.log //更改此行
log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.controllerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.controllerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.controllerAppender.File=${kafka.logs.dir}/logs/controller.log //更改此行
log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.authorizerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.authorizerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.authorizerAppender.File=${kafka.logs.dir}/logs/kafka-authorizer.log //更改此行
log4j.appender.authorizerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.authorizerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
错误八
出现:执行gradlew releaseTarGz时候,出现错误如下
gradlew releaseTarGz
未找到 'gradlew' 命令,您要输入的是否是:
命令 'gradle' 来自于包 'gradle' (universe)
gradlew:未找到命令
解决:将命令改成./gradlew releaseTarGz
原因:windows版本的命令和linux下的命令不尽相同
有什么错误的地方请尽情的指出,也欢迎交流,完毕!