每一台服务器上都要做1、2
1、关闭防火墙
查看防火墙状态:
systemctl status firewalld
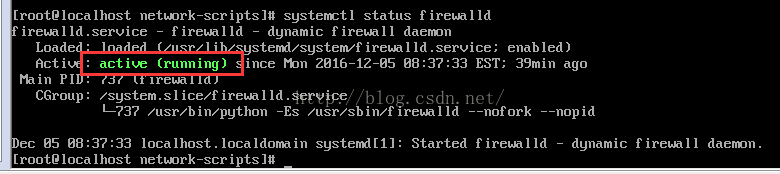
关闭防火墙:
systemctl disable firewalld
systemctl stop firewalld
查看防火墙状态
2、关闭SELinux
查看SELinux状态:
sestatus
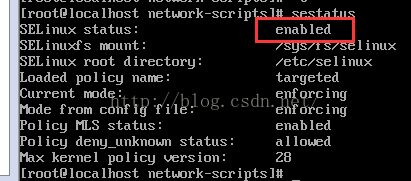
关闭SELinux
#临时关闭,不用重启机器:
setenforce 0
#永久关闭,需要重启机器:
vi /etc/sysconfig/selinux
#下面为selinux文件中需要修改的元素
SELINUX=disabled
临时关闭与永久关闭配合可暂时不用重启机器。达到永久生效的效果。
但不重启机器查看SELinux状态,还会是开启状态。
若要验证是否配置成功,需要reboot重启。
查看是否成功: