正文
主要是用于分析数据的Pandas库
先学习两个数据类型DataFrame和series
进一步学习利用Pandas进行摘要的方法, 提取数据的特征
1 pandas库
1.1 pandas库
pandas库是处理和分析数据最好的库
提供高性能易用数据类型和分析工具
引用
Pandas基于NumPy实现, 常与NumPy和Matplotlib一同使用
示范小例
得到的Series数据, 左边的是索引, 右边的数据

Pandas有两个数据类型: Series(相当于一维数据类型)和DataFrame(二维到多维的数据类型)
基于上述数据类型的各类操作有:
基本操作, 运算操作, 特征类操作, 关联类操作
NumPy与Pandas的区别
NumPy: 基础数据类型; 关注数据结构(维度)的表达; 维度, 数据间关系
Pandas: 扩展数据类型; 关注数据的应用表达(提取, 运算); 数据与索引间关系
1.2 Series类型
Series类型由一组数据及与之相关的数据索引组成

Series数据类型的组成是索引+数据
如果不指定索引, 会自动生成索引, 是从0开始逐渐递增的序列
可以在生成Series的时候指定index来自定义索引
当指定索引的序列是第二个参数的时候, 可以直接输入序列, 不必写全 index=序列


可以通过别的数据来创建Series类型数据
列表, 标量值, 字典, ndarray, 其他函数
1) 从标量创建
使用标量创建所有的值都是该标量, index=不能省略

2) 从字典类型创建
如果不指定index, 那么字典的key就是Series的索引, value就是Series的值
如果指定index, 则Series的值会根据index的内容比对字典中的键, 查看键对应的值作为Series的值
如果index中的值不在字典中, 那么值就设为NaN

3) 从ndarray类型创建
所需要的ndarray必须是一个一维数组

4) 从ndarray中创建

1.3 Series类型的基本操作
Series类型是由索引和值组成
因而基本操作类似字典和ndarray的操作
1) 获得索引和值
Series数据.index 获得它对应的所有索引
Series数据.values 获得它对应的所有值
其中索引是object类型, 是一个专门的索引类型
值是numpy数据类型

2) 根据键获得值
Series数据[ 索引或者索引列表 ] (类似于字典的处理)
其中需要注意的是, 如果自定义了索引, 那么可以通过自定义索引来获得值, 亦可以通过原始索引(0,1,2…)获得值
获得多个值的时候可以在中括号中传入一个索引列表
但是注意, 索引列表中要么是自定义索引, 要么是原始索引, 不能混用

可以通过切片的方式获得值

同样基于字典的性质, 还可以使用关键字in和方法get等
关键字in判断的是自定义索引

利用numpy的处理来过滤数据

3) 对值的操作
Series数据采用随时修改立即生效
基本上都是通过索引来指定修改的值

由于Series数据的值是numpy的值, 因此同样可以使用numpy的操作来处理Series的数据

4) 对齐操作
还可以进行对齐操作 +
生成的结果是一个Series数据, 索引是所有索引的并集
只计算索引交集部分的值进行相加, 其余部分的索引对应的值为NaN

5) 对名字的操作
Series数据的数据对象本身和索引都有一个名字, 存储在 .name 中, 可以直接修改

1.4 DataFrame类型
DataFrame数据类型可以表示二维或者多维的数据, 但是由于在生产环境中, 大多都是二维数据, 因此先主要集中处理二维数据
DataFrame类型是由共用相同索引的一组列组成

实际二维数据可以看做是一个表格, 索引就是行头, 列的名字就是列头

1) DataFrame数据类型的创建
可以通过 二维ndarray对象; 由一组ndarray, 列表, 字典, 元组, Series构成的字典; Series数据, 其他DataFrame数据 构成
从ndarray创建
可以通过传入一个二维的ndarray数据来直接形成一个DataFrame数据

从一维ndarray对象字典创建
也可以传入一个一维的字典
DataFrame的处理是, 把字典的键作为列的索引值, 字典的值一般设置为Series数据, Series的值就是值, 索引就是整个DataFrame的索引
但是需要处理的是, 整个索引是各个Series值的索引的并集
如果涉及该索引没值的, 值设为NaN, 这个操作叫做 数据根据行列索引自动补齐

从列表类型的字典创建
道理和用以为的字典创建类似
只是由于字典的值仅仅只是列表, 没有二维信息, 所以需要在创建的时候, 加入index信息

2) 一些简单的操作
可以使用 .index .columns .values分别获取索引, 列名, 值的信息


获得一列的值可以直接使用 数据[列名]
获得一行的值需要使用 数据.ix[行名]
要获得具体的值只需要 数据[列名][行名] 或者 数据.ix[行名][列名]

1.5 数据类型操作
数据操作主要有两种
增加和重排: 解决办法是重新索引
删除: 使用的是drop
重新索引
使用 .reindex()能够改变或重排Series和DataFrame索引

.reindex(index=None, columns=None, …) 的参数

向前填充指的是, 当值为空时, 该值设为前面的值的值, 同理向后填充就是值设为后面的值的值
具体使用如下

索引类型
Series和DataFrame的索引是Index类型
Index对象是不可修改类型
对索引类型的常用方法

使用

要注意, 序号的是要顺序排列的, 新增的需要也需要按序新增, 不然对应的就是不能生成nd和新生成的一行是NaN
核心提醒, 对索引的操作实际上也是对数据的操作, 这点是pandas与numpy的区别, pandas引入对索引的处理让护具处理更加简便, 而numpy对数据的处理需要对数据维度进行控制管理
删除指定索引对象
.drop()能够删除Series和DataFrame指定行或列索引

drop()操作DataFrame数据的时候, 由于DataFrame有0轴和1轴, 默认是删除0轴的数据

1.6 数据类型运算
算数运算法则
算术运算根据行列索引,索引首先补齐后运算,不同索引之间不进行运算, 运算默认产生浮点数
补齐时缺项填充NaN (空值)
二维和一维、一维和零维间为广播运算
采用+ ‐ * /符号进行的二元运算产生新的对象
数据类型的算数运算
NaN与任何类型的数据进行运算都是NaN
关于行列补齐的标准解释: 小的缺少的部分都补全成一样大小的, 补全的值一般默认是NaN, 再进行运算

数据类型的方法形式的运算
使用方法形式的原因是因为可以有一些可选参数, 这些可选参数可以进一步扩展运算的功能


广播运算是逐个进行运算, Series数据与标量进行运算的时候, 是Series的每个值与该标量进行运算
DataFrame数据与Series数据进行运算, 是二维数据与一维数据进行运算, 其中默认情况是在轴1上进行运算
也就是说, 行的每个值对应的与Series的值对象进行运算
结论: DataFrame数据的1轴是一行, 0轴是一行的每一列的数据, 也就是如下的形式:


要想在二维与一维的数据进行运算, 需要使用方法的形式, 并且传入参数axis=0才能保证在每一列上运行
快捷的看法是, 默认轴1是先行后列, 轴0是先列后行

比较运算法则
比较运算只能比较相同索引的元素,不进行补齐
二维和一维、一维和零维间为广播运算
采用> < >= <= == !=等符号进行的二元运算产生布尔对象
数据类型的比较运算
特别注意, 维度相同的时候, 比较运算需要是两者是相同size的, 不同是无法运算的

当维度不同时, 也就是二维与一维的运算, 默认也是在轴1上运算

2 数据特征分析
2.1 数据的排序
一组数据的含义主要是看它表现的摘要
摘要, 将一组数据 有损的提取 数据特征的过程
摘要的形成的数据特征有: 基本统计(含排序); 分布/累计统计; 数据特征; 相关性、周期性等; 数据挖掘(形成知识)
1) 排序
pandas支持对索引的运算和对数据的运算两个方面, 对索引的运算采用sort_index方法, 对数据的运算采用的是.sort_values()方法
.sort_index() 指定轴上根据索引进行排序, 默认是升序
.sort_index(axis=0, ascending=True)
其中轴默认是0, 也就是对行名字进行排序, 轴设为1时, 对一行中的值进行排序
默认是升序为True, 降序为False


.sort_values()指定在轴上根据数值进行排序, 默认升序
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True)
其中by指定行名字或者是列名字, 写入的是索引或者索引列表, 需要与axis配合使用
axis默认是0, 是列; 设为1时, 是行
ascending默认是True为升序; 设为False为降序

当值有NaN时, 排序会把它放到末尾

2.2 数据的基本统计分析
基本的统计分析函数
1) Series和DataFrame类型都可以使用的函数
Series数据只有0轴, 如果Series和DataFrame数据都可以使用, 那么默认的就是应该处理0轴

有一个可以囊括所有结果的函数describe()函数

具体使用实例
.describe()函数返回的结果是Series类型的数据, 所以可以通过Series数据的处理方式可以分析describe()的结果


2) 仅仅是Series类型使用的函数

2.3 数据的累计统计分析
累计统计分析就是对序列的前1~n个数进行一些累计运算, 这样可以减少一些for循环, 使得数据运算更加的灵活
1) 适用于Series和DataFrame类型, 用于累计计算, 默认也是0轴的运算

使用实例

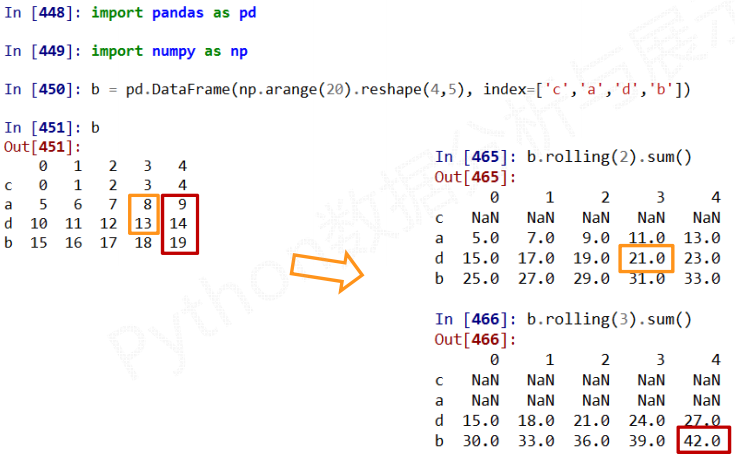
2) 适用于Series和DataFrame类型, 滚动计算(窗口计算)

使用实例
2.4 数据的相关分析
相关分析
针对值X和Y, X的变化会引起Y的变化
当 X增大,Y增大,两个变量正相关
当 X增大,Y减小,两个变量负相关
当 X增大,Y无视,两个变量不相关
协方差
协方差>0 X和Y正相关
协方差<0 X和Y负相关
协方差=0 X和Y独立无关
但是协方差获得的相关性不是很精确, 有更多用于描述相关性的参数, 如Pearson相关系数
Pearson相关系数
计算公式

r的取值范围是[-1, 1]
取得r的绝对值:
当r在0.8-1.0 极强相关
当r在0.6-0.8 强相关
当r在0.4-0.6 中等程度相关
当r在0.2-0.4 弱相关
当r在0.0-0.2 极弱相关或者无相关
相关分析函数
适用于Series和DataFrame类型
