个人主页:为梦而生~ 关注我一起学习吧!
专栏:python网络爬虫从基础到实战 欢迎订阅!后面的内容会越来越有意思~
往期推荐:
【Python爬虫开发基础⑦】urllib库的基本使用
【Python爬虫开发基础⑧】XPath库及其基本用法
我们在之前已经有8篇文章讲述基础知识了,下面我们利用已有的知识来进行一个简单的爬虫实战,感受一下爬虫的魅力,同时也可以增加学习的乐趣~
本文爬虫程序用到了urllib库和XPath库,都是上两次文章讲过的,链接已经放在上面了,没有看过的先看一下前置知识哦~下面我们马上开始!
首先来看一下效果:

1 确定爬取目标
我们第一步要做的,就是找到要爬取的目标网站,同时利用开发者工具看清楚前端的代码结构,方便我们写合适的xpath代码。
在这里,我们可以看到,class属性为container的div标签有两个,通过定位知道下面的标签包含着想要的图片。
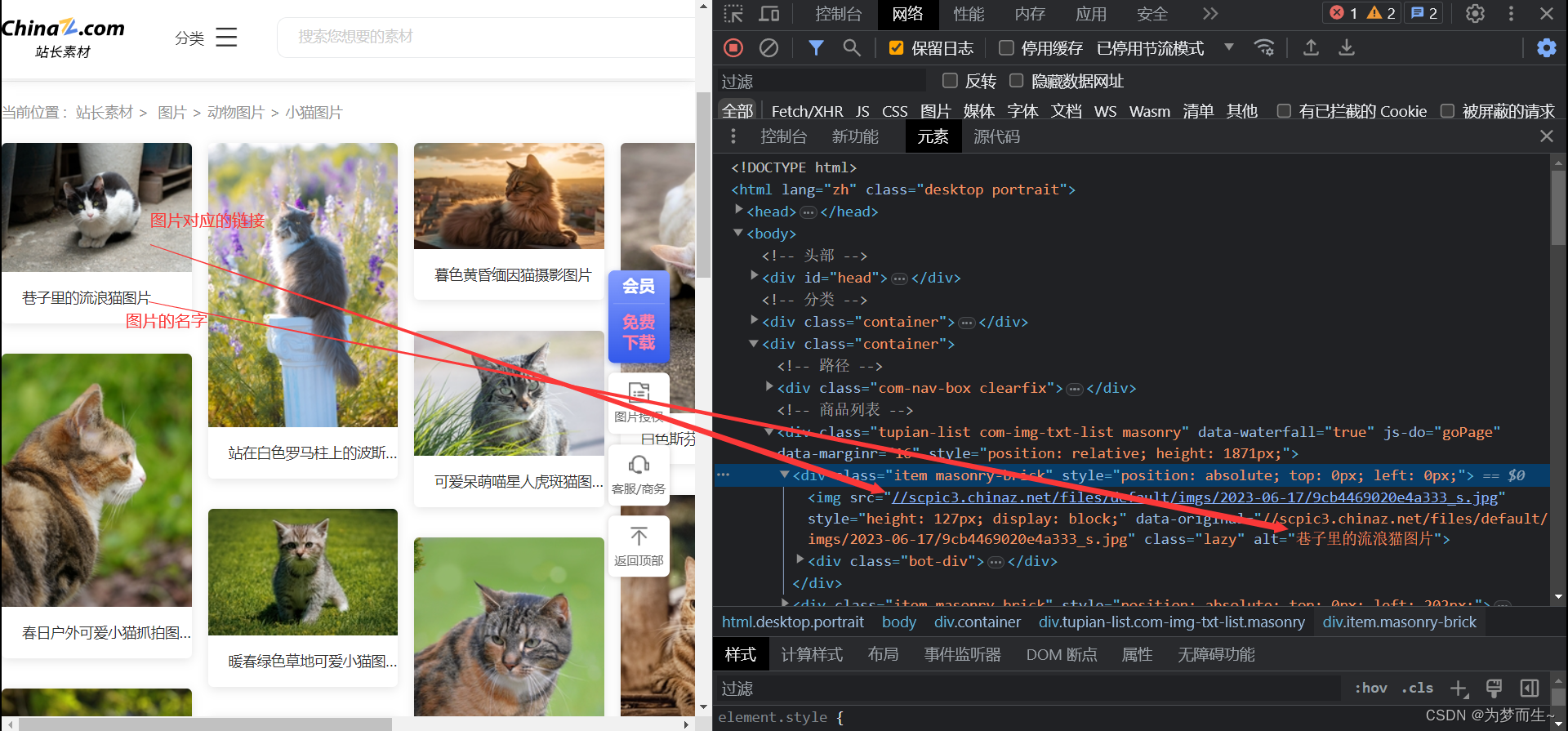
在其中包含图片的div标签里面,我们注意到,每一个class属性为item masonry-brick的div标签对应着一个图片。
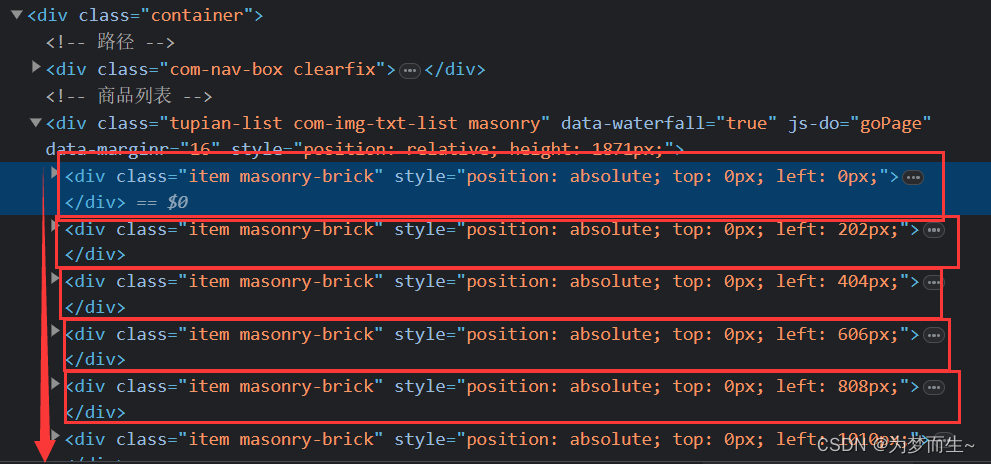
每一个图片的地址和名字就藏在这里面,但是着并不代表可以直接用,具体原因我们后面再说。

2 开始写代码
from lxml import etree
import urllib.request
start_page = int(input('请输入起始页码:'))
end_page = int(input('清输入结束页码:'))
- 然后,对每一页的数据,都按照这三步进行:(1)请求对象的定制 (2)获取网页的源码 (3)下载图片
- 可以用一个for循环来完成
for page in range(start_page, end_page+1):
# (1) 请求对象的定制
request = create_request(page)
# (2) 获取网页的源码
content = get_content(request)
# (3) 下载
down_load(content)
- 下面来定义里面的每一个函数(细节放在代码的注释中讲解)
# 请求对象的定制
def create_request(page):
# 由于不同的页码会导致网址的改变,所以我们把不变的部分作为base_url
base_url = 'https://sc.chinaz.com/tupian/xiaomaotupian.html'
# 对于形参不同的page,我们通过简单的字符串拼接得到响应的网址
if page == 1 :
url = base_url
else :
url = 'https://sc.chinaz.com/tupian/xiaomaotupian_' + str(page) + '.html'
print(url)
# 设置请求头,这里设置了UA,每一个浏览器的UA不一样,可以到抓包后的报文中找
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 生成请求对象,用于向服务器发送请求
request = urllib.request.Request(url = url, headers = headers)
# 返回请求对象
return request
# 获取网页的源码
def get_content(request):
# 发送请求获取响应
response = urllib.request.urlopen(request)
# 对响应进行解码
content = response.read().decode('utf-8')
# 返回
return content
# 下载
def down_load(content):
# 创建ElementTree对象
tree = etree.HTML(content)
# 使用xpath表达式,获取图片的名字和对应的地址
name_list = tree.xpath('//div[@class="container"]//img/@alt')
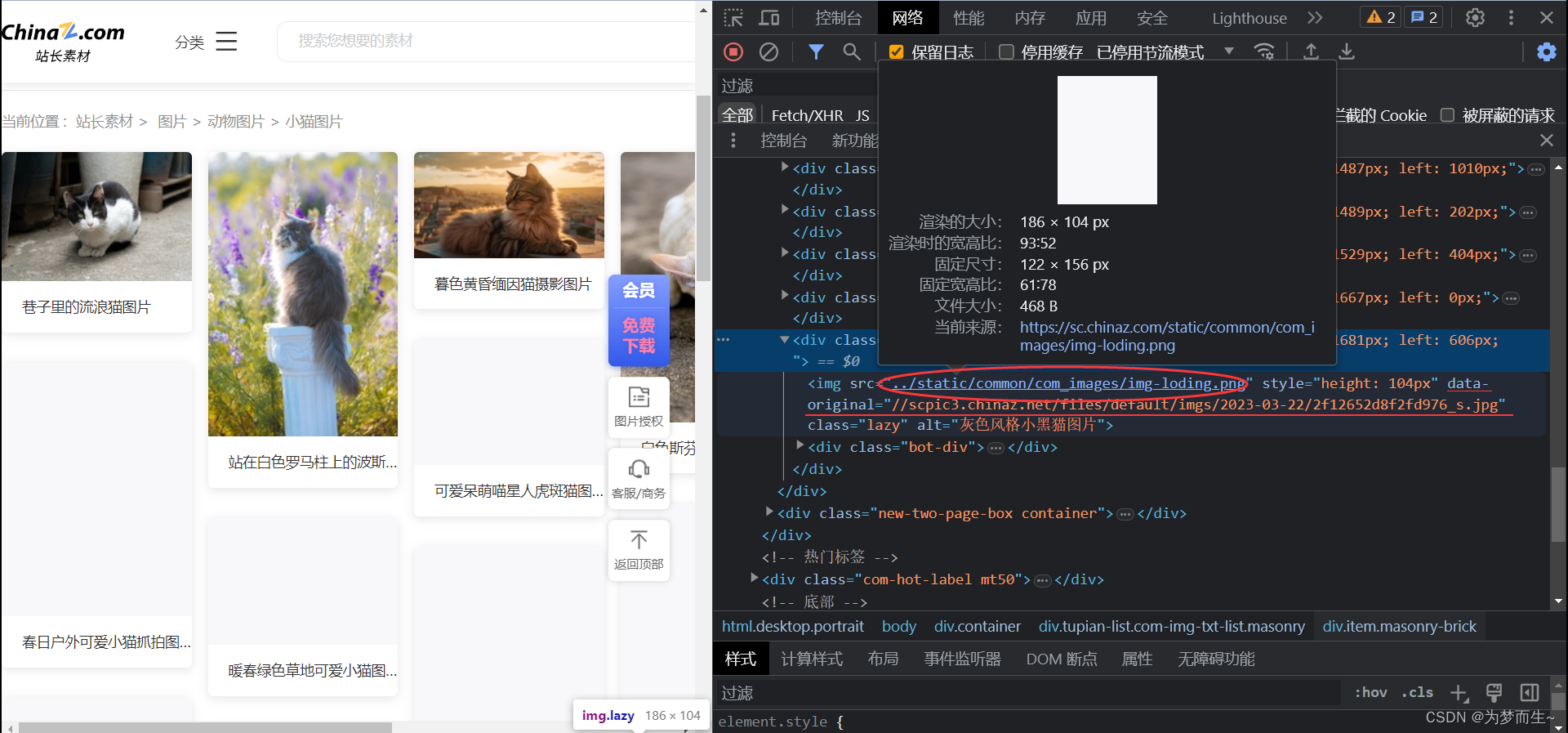
# 由于页面的预加载,获取到的HTML代码中,图片的地址并不会直接存在src里面,而是后面的data-original
src_list = tree.xpath('//div[@class="container"]//img/@data-original')
# print(len(name_list), len(src_list))
# 遍历本页面的所有图片
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
# print(name, url)
# 利用urlretrieve进行图片的下载
urllib.request.urlretrieve(url = url, filename = './cat imgs/' + name + '.jpg')
注意:上面的图片预加载是指:当页面还没有滑倒最下面的时候,后面的img标签里面的src属性并没有存储图片的地址,而地址是存在后面的data-original里面,如下图所示:
最后,我们运行代码,就可以得到一开始的图片了!赶紧试一下吧!后面的文章会介绍更加丰富多彩的爬虫基础~敬请期待