从15年3月接触Ceph分布式存储系统,至今已经5年了;因为工作的需要,对Ceph的主要模块进行了较深入的学习,也在Ceph代码层面做了些许改进,以满足业务需要(我们主要使用M版本)。最近得闲,将过往的一些学习心得、改进以及优化思路记录下了,希望能对后来者有所帮助。
这是第四篇:Ceph bluestore中的缓存管理
前言
bluestore构建在裸盘上,在用户空间,通过FreelistManager以及Allocator来管理磁盘空间且通过direct-io访问磁盘,所以它不能够利用到系统的pagecache。为了提升性能,bluestore在用户态实现了基于2q和lru算法的cache。
bluestore中的缓存管理
缓存对象及相关数据结构
在继续后文前,我们先来明确几个主要的结构及其作用:
- Object: Ceph实际上分布式对象存储系统,通过Object来表示存储系统中的IO对象,类似传统文件系统中的文件,由数据(Bufferlist)和元数据(Onode)两部分组成
- Collection:pg的内存表示,常驻内存,它是Object对象的逻辑仓库
- bluestore_cnode_t:Collection的元数据
- Onode: Object的元数据,包含对象id以及指向对象数据逻辑位置<offset, len>的ExtentMap结构
- bluestore_onode_t:Onode的元数据,存储在db中
- Cache:bluestore 缓存对象,有LRUCache和TwoQCache两种
- OnodeSpace:Onode的缓存管理对象,包含一个Cache对象以及一个unordered_map类型的Onode映射
- Buffer:Object对象数据(bufferlist,offset,len)的缓存表示
- BufferSpace:用于管理Buffer,包含一个Buffer的map,角色类似OnodeSpace
Collection与bluestore_cnode_t, Onode与bluestore_onode_t的关系类似于Linux文件系统中内存inode与磁盘inode的关系
下面的UML类图展示了上述对象之间的关系:
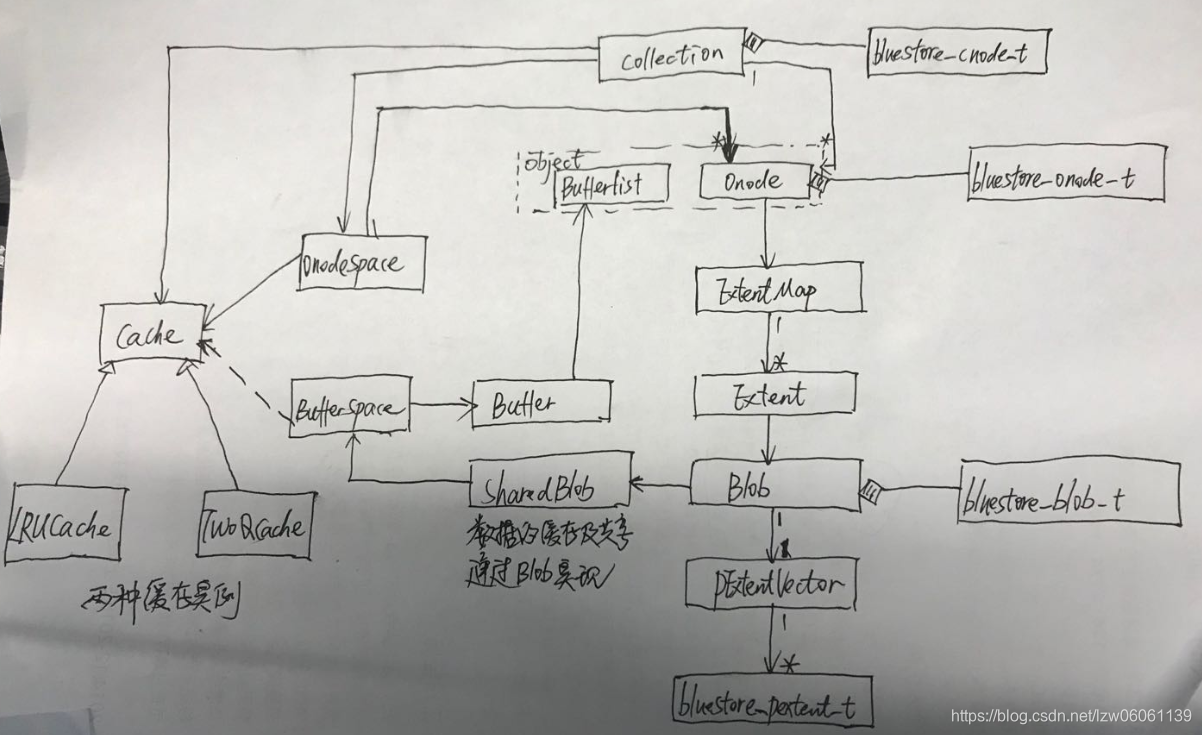
OSD启动时,Bluestore会创建多个Cache实例,之后从db加载Collection到内存中时,通过cid % shard_num模与Cache关联,所有的Collection常驻内存,通过一个map来管理;每个Collection包含一个Cache指针,一个元数据对象bluestore_cnode_t以及一个OnodeSpace类型的onode_map变量,这个变量包含与Collection相同的Cache实例以及一个Onode的unorderd_map对象(这个unorderd_map应该是用来加速查找的,因为Cache可能被多个Collection共享,通过每个OnodeSpace中的专属结构来管理本Collection的Onode,可以提升效率)。
Ceph中的对象元数据(这里说的元数据是指数据元数据,对象属性通过ObjectMap来管理)通过Onode来管理,包含对象的id以及一个ExtentMap结构来表示对象的数据偏移及长度信息,每个Extent表示逻辑上连续的数据片段,通过<offset, len>来标识;由于一段逻辑数据在物理上可能不连续,可能对应多个物理存储区bluestore_pextent_t, 为便于管理引入了Blob,它是bluestore_pextent_t的集合(PExtentVector),Blob还是Ceph中的数据共享单位,快照克隆的时候,共享数据通过更新引用计数即可,不需要磁盘拷贝。
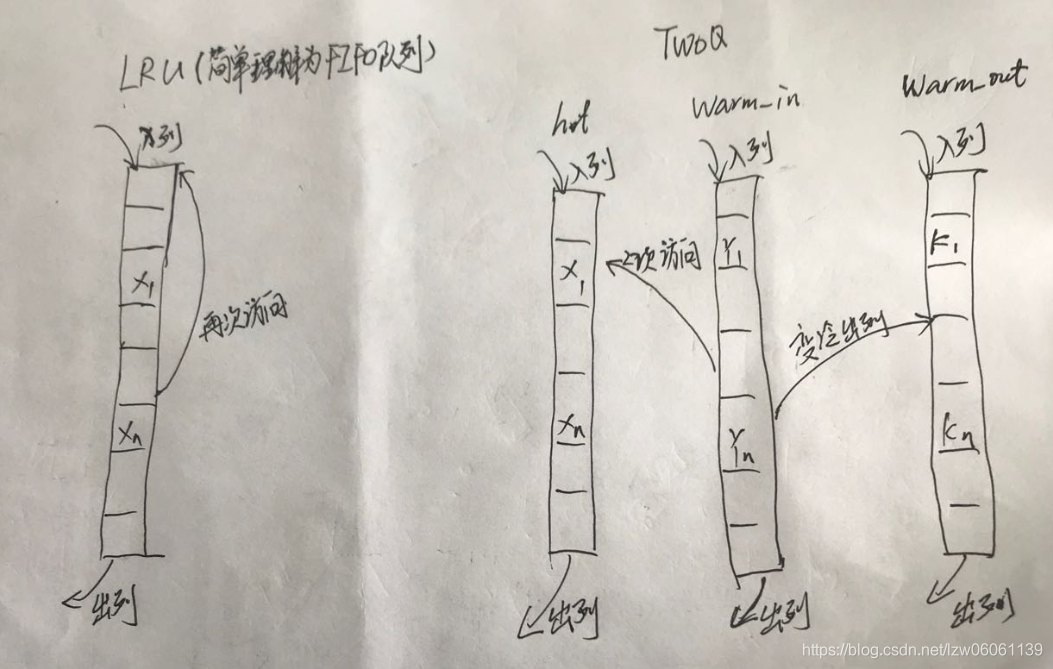
Bluestore提供了LRU cache 和 2Q cache两种缓存机制,默认采用2Q cache。LRUCache,淘汰最近最少使用的item,采用list来实现,Onode和Buffer各占用一个队列;TwoQCache,针对Onode和Buffer采用不同的处理方式,其中Onode缓存采用LRU实现,而Buffer将整个缓存空间分为三部分,使用三个队列,分别称为hot,warm_in,warm_out来管理,新加入的数据加入到warm_in队列,再次访问的数据加入到hot队列,warm_in中的冷数据向移到warm_out队列,另外TwoQCache充分利用局部性原理,加入对象时会根据offset匹配前后的对象,将新对象加入到临近对象的前面。下图是LRU和2Q缓存的一个示例说明:
缓存管理
缓存系统的基本操作包括CRUD四种,Cache主要提供了:add(C),touch(U),rm(D),trim(D)四个方法,OnodeSpace或者BufferSpace提供了:add(C),rename(U),lookup(R),discard (U),remove(D)四个方法, 可以想到OnodeSpace和BufferSpace实现了一部分业务语义:
add方法:包括Onode和Buffer两部分,就Onode而言:LRUCache和TwoQCache采用相同的策略,如果对象已经在缓存中,则直接返回,否则将Onode加入到OnodeSpace的onode_map中并插入到cache的onode队列的头部;对于Buffer:LRUCache采用与Onode相同的策略,将对象插入到cache的buffer队列的头部,而TwoQCache维护了三个队列,根据热度属性将对象分别添加到hot,warm_in,warm_out队列。
lookup方法:用来从OnodeSpace的onode_map中查找对象,如果找到则通过touch方法将对象提升到cache的onode队列的头部,需要注意的是TwoQCache中,只有hot队列中的队列才会提升到cache的头部。
rm方法:包括Onode和Buffer两部分,就Onode而已:LRUCache和TwoQCache采用相同的策略,将对象从队列中删除,将对象从OnodeSpace的onode_map中删除;对于Buffer:LRUCache采用与Onode相同的策略,将对象从队列中删除,TwoQCache则将对象从hot,warm_in,warm_out之一中移除。
trim方法:根据需要保留的onode_max以及buffer_max清理缓存,包括Onode和Buffer两部分,基本上就是简单的将对象从队列中移除,TwoQCache对Buffer的处理有些许不同:它根据各队列的数据空间占比(ratio)来计算每个队列需要移除的对象。
rename方法:处理对象的重命名操作。
discard方法:淘汰给定区间的缓存对象。
缓存的使用
下文从缓存初始化,读IO和写IO三个方面来分析Bluestore cache的使用。
- 缓存的初始化
1)OSD init初始化时 Bluestore根据设置的shard_num, cache_type创建cache实例
2)Bluestore mount时从db加载Collection,通过cid与 shard_num取模关联特定的cache实例,Blustore通过一个map来管理内存中的Collection。
- 读io缓存使用
1)Bluestore收到读请求后,从cache中获取对象的onode(包含extent信息),并且将onode移到队列的头部
2)如果上述获取的onode的extent中不全部包含<offset, len>所需要的信息,则从db中加载缺失部分的extent
3)根据<offset, len>从cache中读取缓存数据,并将命中的数据移到队列头部
4)对于不在缓存中的数据则从后端磁盘上读取,如果启用了bufferIO,则将数据加入到缓存队列头部(warm_in队列)
- 写io缓存使用
1)Bluestore收到写请求后,从cache中获取onode或者创建一个onode, 并将onode插入队列的头部
2)如果上述获取的onode的extent中不全部包含<offset, len>所需要的信息,则从db中加载缺失部分的extent
3)如果启用了bufferIO,则将数据(如果IO区间有重叠会先从磁盘读取数据做合并)加入到缓存队列的头部
4)(在执行io前)将缓存元数据(Onode,SharedBlob)持久化到db中(这个过程中,ExtentMap可能需要分片,根据needs_reshard_begin/needs_reshard_end来决定需要reshard的区间)。
步骤3中有几点需要注意:
- 数据缓存是以Blob单位进行的,
- 如果和之前的缓存数据有部分重叠,会truncate掉front和tail,如果完全包含则先从cache中删除掉
- 根据数据的热度属性将对象添加到不同的队列中,新增的数据插入到warm_in队列,如果与之前的数据有重叠,那么加入哪个队列与之前数据的热度属性相关