一 架构
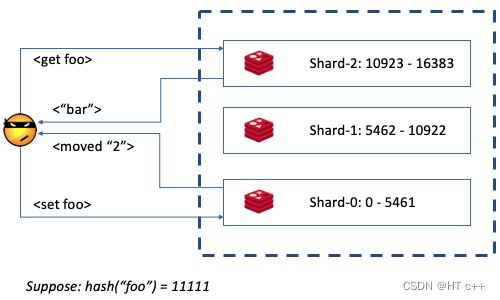
Redis Cluster使用 Slot 的概念:作为一个KV系统,它把每个key的值hash成0 ~ 16383之间的一个数。这个hash值被用来确定对应的数据存储在哪个节点中。集群中的每个节点都存储了一份类似路由表的东西,描述每个节点所拥有的 Slots;当用户请求一个不在本机的key的时候,它可以根据这个路由表找到正确的服务节点,然后回复给用户一个moved,告知用户正确的服务节点。
-
slot = CRC16(key) % 16383;
-
是集群内数据管理和迁移的最小单位,保证数据管理的粒度易于管理;
-
每个节点都知道slot在集群中的分布,并能把对应信息回复给无法服务的请求。
-
节点之间保持Gossip通信

gossip 协议包含多种消息,包括ping,pong,meet,fail等等。
-
meet:某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信。
-
ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据(类似自己感知到的集群节点增加和移除,hash slot信息等)。
-
pong: 对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新。
-
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
-
gossip协议的优点在于元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力;缺点在于元数据更新有延时可能导致集群的一些操作会有一些滞后。
二 连接与部署
2.1客户端查找数据
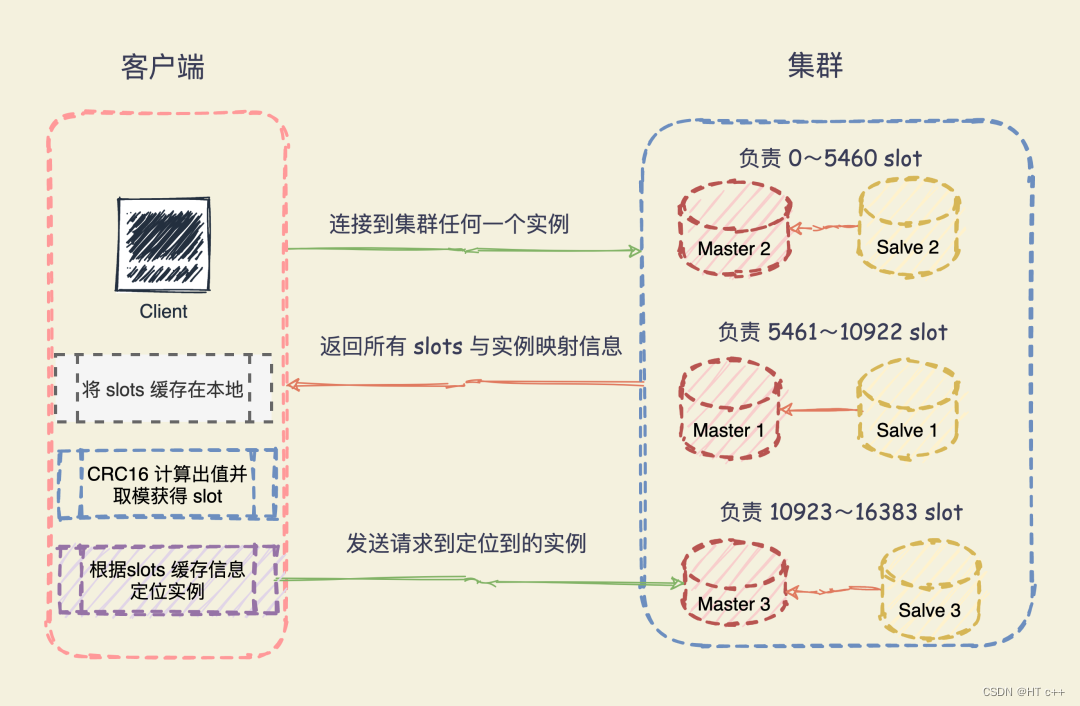
比如:MOVED 10086 127.0.0.1:7002 表示,客户端请求的键值对所在的哈希槽 10086,实际是在 127.0.0.1:7002 这个实例上。
通过返回的 MOVED 命令,就相当于把哈希槽所在的新实例的信息告诉给客户端了。
这样一来,客户端就可以直接和 7002 连接,并发送操作请求了。
同时,客户端还会更新本地缓存,将该槽与 Redis 实例对应关系更新正确
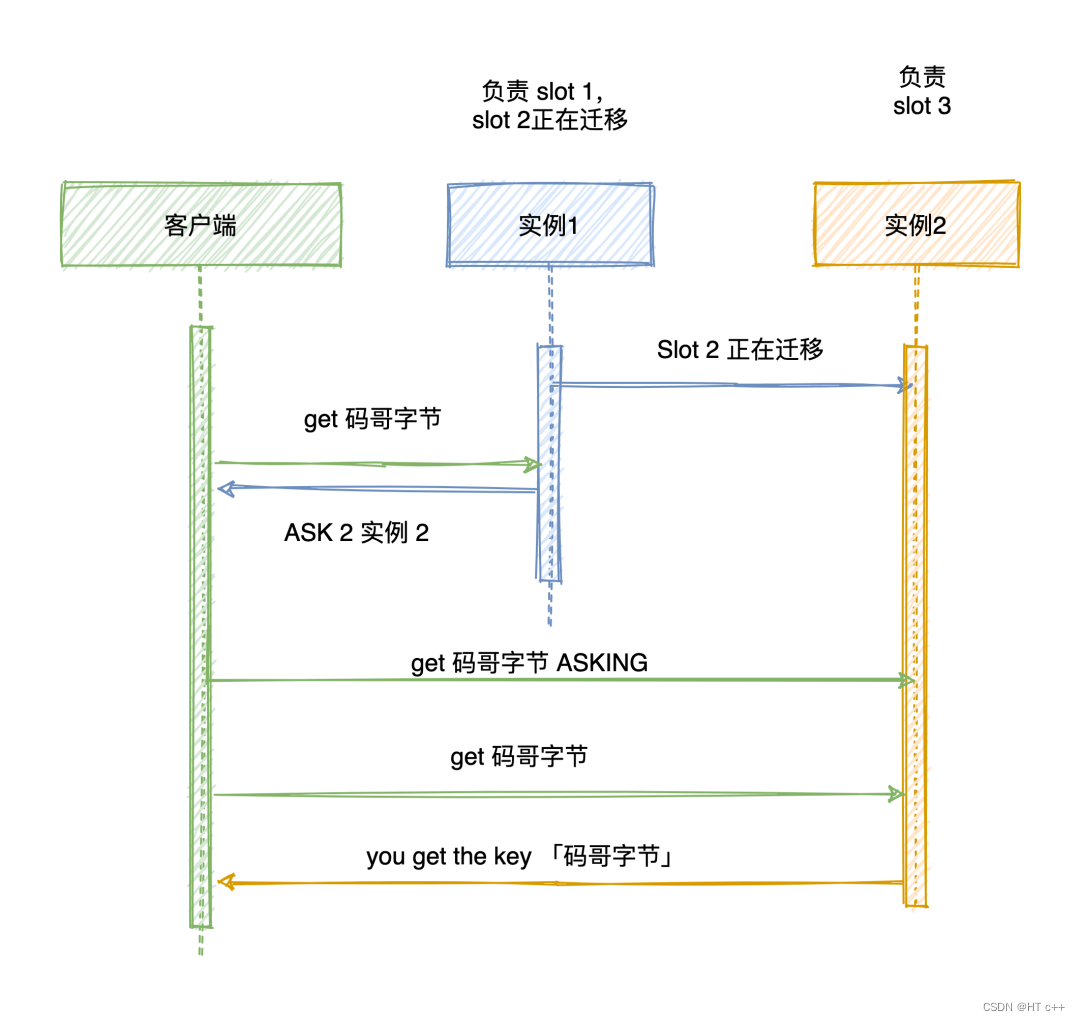
MOVED 错误表示客户端请求的 key 不在当前实例的槽位上,客户端需要重定向到 MOVED 错误指向的实例
而 ASK 错误只是两个节点迁移槽过程中的一种临时措施,客户端请求的 key 正在迁移而且迁移到新实例上去时,就会返回一个 ASK 错误,客户端就会将请求的 key 重定向到 ASK 错误指向的新实例上
如果客户端再次请求相同的 key,它还是会向原来负责该槽位的实例发送请求
ASK 命令只是让客户端给新实例发送一起请求,不像 MOVED命令一样会更改本地缓存的哈希槽分配信息,让后续所有请求都发往新实例
单个集群节点不建议设置过多,过多的节点间的通信会带来较大的网络开销。按照服务来区分部署集群
1.集群能在挂一台机器的情况下不影响服务,要满足这个要求,主从节点就不能在一台机器上,也不能有过半数(包括半数)主节点在同一台机器上。
2.集群在挂一台机器的情况下,压力应尽可能平均分流到其他机器。
3.主节点和从节点在各台机器上的分布应当平均。
4.一个分片只配置一个slave
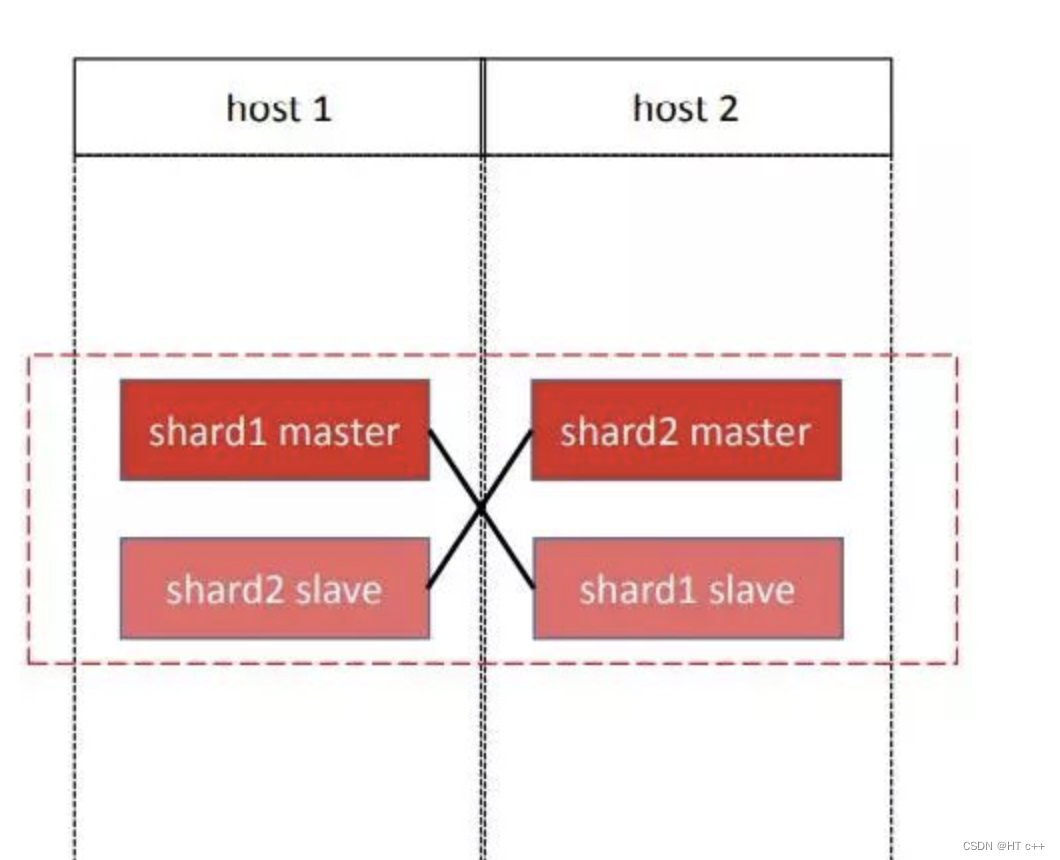
为了简化管理, 我们规定了集群的规格. 具体做法是每个主节点有且只有一个从节点. 并且以4个节点为最小的管理单位, 我们称为chunk. 一个chunk有两主两从, 分布在两台机器上面, 每台机器两个节点, 且4个节点内互相组成主从关系, 要求负责一个分片的主从分布在不同的机器上面.
一个chunk:
machine A machine B
master 1 / master 2
slave 2 /\ slave 1
三 故障检测与切换
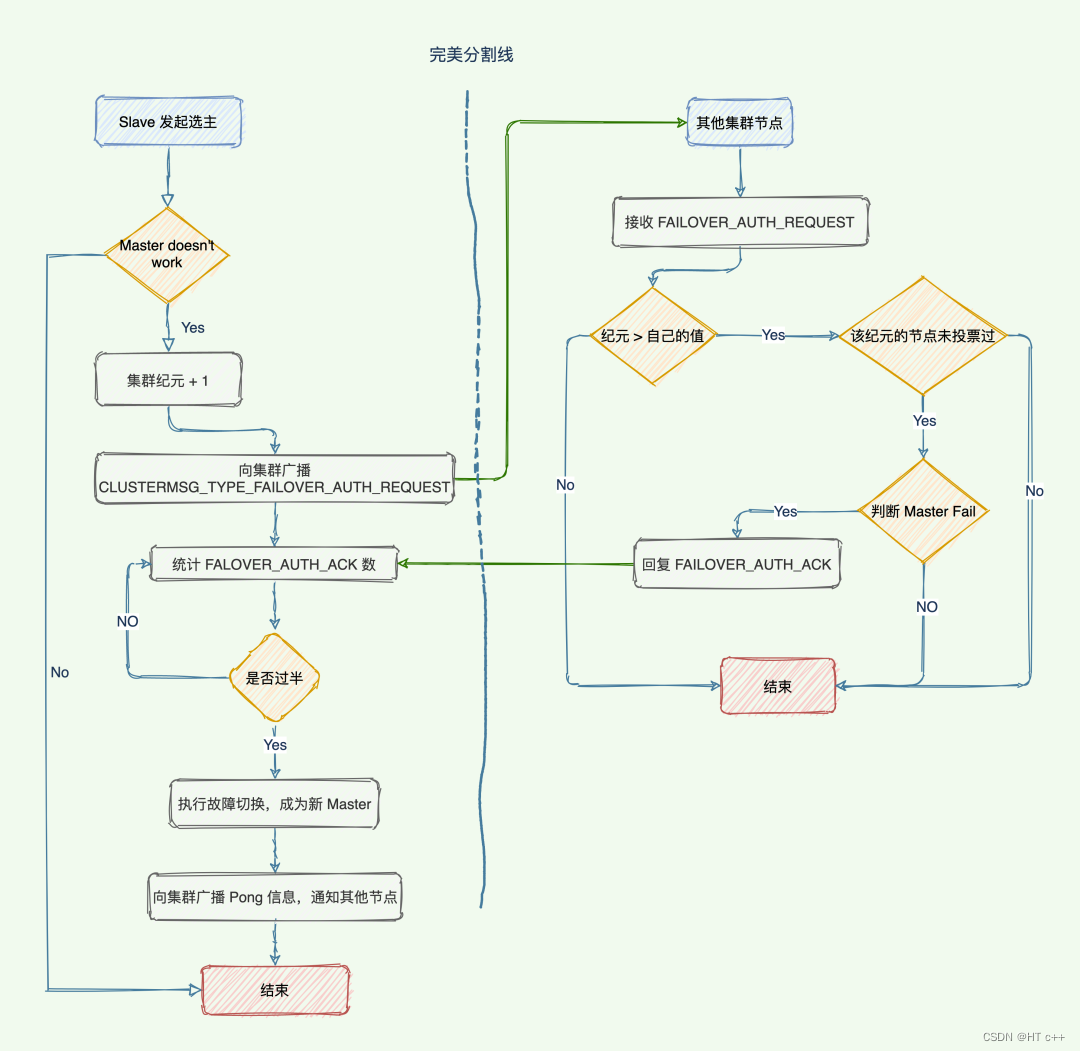
-
slave发现自己的master变为FAIL
-
将自己记录的集群currentEpoch加1,并广播Failover Request信息
-
其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
-
尝试failover的slave收集FAILOVER_AUTH_ACK
-
超过半数后变成新Master
-
广播Pong通知其他集群节点
1.SlaveMigration
/* Step 1: Don't migrate if the cluster state is not ok. */
if (server.cluster->state != CLUSTER_OK) return;
/* Step 2: Don't migrate if my master will not be left with at least
* 'migration-barrier' slaves after my migration. */
if (mymaster == NULL) return;
for (j = 0; j < mymaster->numslaves; j++)
if (!nodeFailed(mymaster->slaves[j]) &&
!nodeTimedOut(mymaster->slaves[j])) okslaves++;
if (okslaves <= server.cluster_migration_barrier) return;
candidate = myself;
di = dictGetSafeIterator(server.cluster->nodes);
while((de = dictNext(di)) != NULL) {
clusterNode *node = dictGetVal(de);
int okslaves = 0, is_orphaned = 1;
/* We want to migrate only if this master is working, orphaned, and
* used to have slaves or if failed over a master that had slaves
* (MIGRATE_TO flag). This way we only migrate to instances that were
* supposed to have replicas. */
if (nodeIsSlave(node) || nodeFailed(node)) is_orphaned = 0;
if (!(node->flags & CLUSTER_NODE_MIGRATE_TO)) is_orphaned = 0;
/* Check number of working slaves. */
if (nodeIsMaster(node)) okslaves = clusterCountNonFailingSlaves(node);
if (okslaves > 0) is_orphaned = 0;
if (is_orphaned) {
if (!target && node->numslots > 0) target = node;
/* Track the starting time of the orphaned condition for this
* master. */
if (!node->orphaned_time) node->orphaned_time = mstime();
} else {
node->orphaned_time = 0;
}
/* Check if I'm the slave candidate for the migration: attached
* to a master with the maximum number of slaves and with the smallest
* node ID. */
if (okslaves == max_slaves) {
for (j = 0; j < node->numslaves; j++) {
if (memcmp(node->slaves[j]->name,
candidate->name,
CLUSTER_NAMELEN) < 0)
{
candidate = node->slaves[j];
}
}
}
}
dictReleaseIterator(di);
/* Step 4: perform the migration if there is a target, and if I'm the
* candidate, but only if the master is continuously orphaned for a
* couple of seconds, so that during failovers, we give some time to
* the natural slaves of this instance to advertise their switch from
* the old master to the new one. */
if (target && candidate == myself &&
(mstime()-target->orphaned_time) > CLUSTER_SLAVE_MIGRATION_DELAY &&
!(server.cluster_module_flags & CLUSTER_MODULE_FLAG_NO_FAILOVER))
{
serverLog(LL_WARNING,"Migrating to orphaned master %.40s",
target->name);
clusterSetMaster(target);
}
四 需要注意的坑
1.压力分布不均:
宕机后slave会选举为master 这台机器上会出现较多的master节点,在创建集群时需要预估该机器挂了后机器能否承受上面对应的服务产生的压力
保存初始主从节点的分布情况并及时更新,宕机后可以尽快的给集群补充机器
Redis Cluster 不建议使用 pipeline 和 multi-keys 操作(如 mset/mget. multi-key 操作),减少 max redirect 的产生;
五 常见问题排查
1.OOM
redis内存分布:
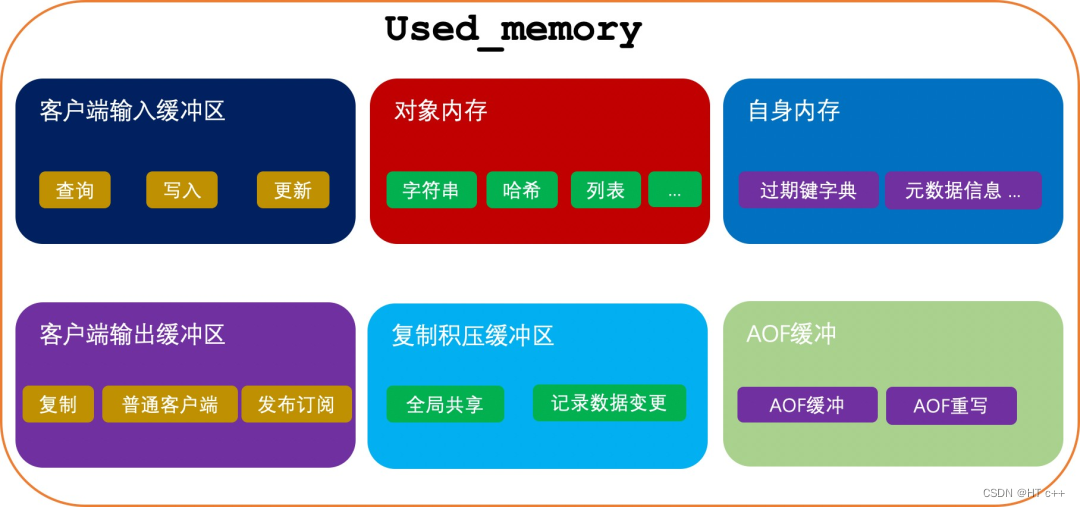
- 客户端内存 :不受maxmemory限制
- 对象内存: 主要占用内存的部分
- 复制积压缓冲: 所有从库客户端共享、保存固定大小的写入命令用于从库失连后数据补偿
- redis自身内存
oom导致:无法写入;大量key过期 影响读取
检查内存使用情况:
redis-cli -p 6383 memory stats|egrep -A 1 '(total.allocated|overhead.total|dataset.bytes|clients.normal)'
overhead.total:复制缓冲区、客户端输入输出缓冲区等,另外还包括⼀些元数据如 overhead.hashtable
dataset.bytes:数据对象使用内存
数据达到⼀定规模后,因需消耗额外的元数据、缓存内存,Redis 最终将超过 maxmemory 而 OOM
占用最多内存的连接数
# 1. 快速查看Redis内存是否够用
redis-cli -p 9999 info memory |egrep
'(used_memory_human|maxmemory_human|maxmemory_policy)'
# 2. 检查复制积压缓冲区使用情况
redis-cli -p 9999 memory stats|egrep -A 1
'(total.allocated|replication.backlog)'
# 3. 检查客户端输入缓冲区内存使用总量
redis-cli -p 9999 client list| awk 'BEGIN{sum=0}
{sum+=substr($12,6);sum+=substr($13,11)}END{print sum}'
# 4. 检查客户端输入缓冲区各客户端连接的内存情况
redis-cli -p 6383 client list|awk '{print substr($12,6),$1,$12,$18,$20}'|sort -nrk1,1|head -3| cut -f1 -d " " --complement
# 5. 检查客户端输出缓冲区内存使用总量
redis-cli -p 9999 client list| awk 'BEGIN{sum=0} {sum+=substr($16,6)}END{print
sum}'
# 6. 检查客户端输出缓冲区各客户端连接的内存使用排序
redis-cli -p 9999 client list|awk '{print substr($16,6),$1,$16,$18}'|sort -
nrk1,1 | cut -f1 -d" " --complement |head -n10
# 7. 检查数据对象使用内存总量
redis-cli -p 9999 memory stats|grep -A 1 'dataset.bytes'
如果定位到有连接异常,可以使用如下命令杀掉
CLIENT KILL ID
压测常用命令:
# 1. 持续给Redis灌数据
redis-benchmark -p 9999 -t set -r 100000000 -l
# 2. 模拟输入缓冲区过大
redis-benchmark -p 9999 -q -c 10 -d 102400000 -n 10000000 -r 50000 -t set
# 3. 模拟输出缓冲区过大
redis-benchmark -p 9999 -t get -r 5000000 -n 10000000 -d 100 -c 1000 -P 500 -l
2.常用运维命令
2.1慢日志
#获取5条慢日志
slowlog get 5
#设置阈值
config set slowlog-log-slower-than 2000
2.2 rename高危操作
#在配置文件中添加:
rename-command flushdb flushddbb
rename-command flushall flushallall
rename-command keys keysys
2.3 monitor
#输出keys命令的执行情况
redis-cli -p 6380 monitor | grep keys
2.4 config
#将config热修改的参数刷到redis配置文件中持久化
config rewrite
2.5 redis 查看cluster各节点ip
redis-cli -p 6380 cluster nodes |awk '{print $2}' |awk -F'@' '{print "- "$1}'
2.6 关闭&打开 rdb持久化
redis-cli --cluster call 127.0.0.1:6380 config set save ""
redis-cli --cluster call 127.0.0.1:6380 config rewrite
redis-cli --cluster call 127.0.0.1:6380 config get save*
redis-cli --cluster call 127.0.0.1:6380 config set save "900 1 300 10 60 10000"
redis-cli --cluster call 127.0.0.1:6380 config rewrite
2.7 下线节点
redis-cli --cluster del-node host:port node_id
#删除节点 需要通过reshard命令把slot分配到其他节点,然后再执行删除命令
#或者
cluster forget <node_id> :从集群中移除 node_id 指定的节点(需在所有节点执行)
#echo "usage: host port"
nodes_addrs=$(redis-cli -h $1 -p $2 cluster nodes|grep -v handshake| awk '{print $2}')
echo $nodes_addrs
for addr in ${nodes_addrs[@]}; do
host=${addr%:*}
port=${addr#*:}
del_nodeids=$(redis-cli -h $host -p $port cluster nodes|grep -E 'handshake|fail'| awk '{print $1}')
for nodeid in ${del_nodeids[@]}; do
echo $host $port $nodeid
redis-cli -h $host -p $port cluster forget $nodeid
done
done