清理、重塑、转换
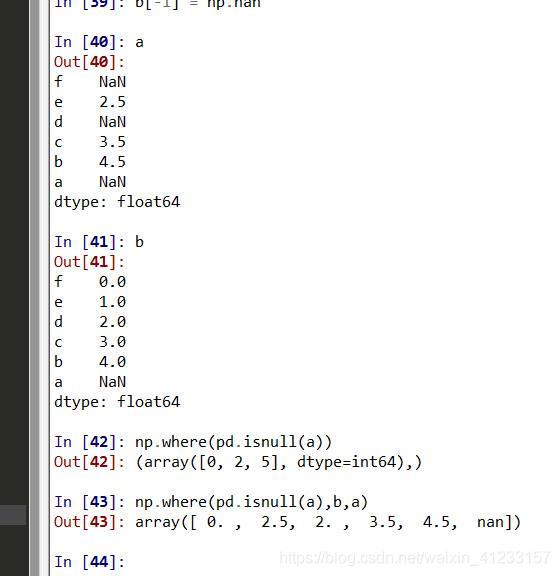
numpy.where(condition[, x, y])
1、这里x,y是可选参数,condition是条件,这三个输入参数都是array_like的形式;而且三者的维度相同
2、当conditon的某个位置的为true时,输出x的对应位置的元素,否则选择y对应位置的元素;
3、如果只有参数condition,则函数返回为true的元素的坐标位置信息;
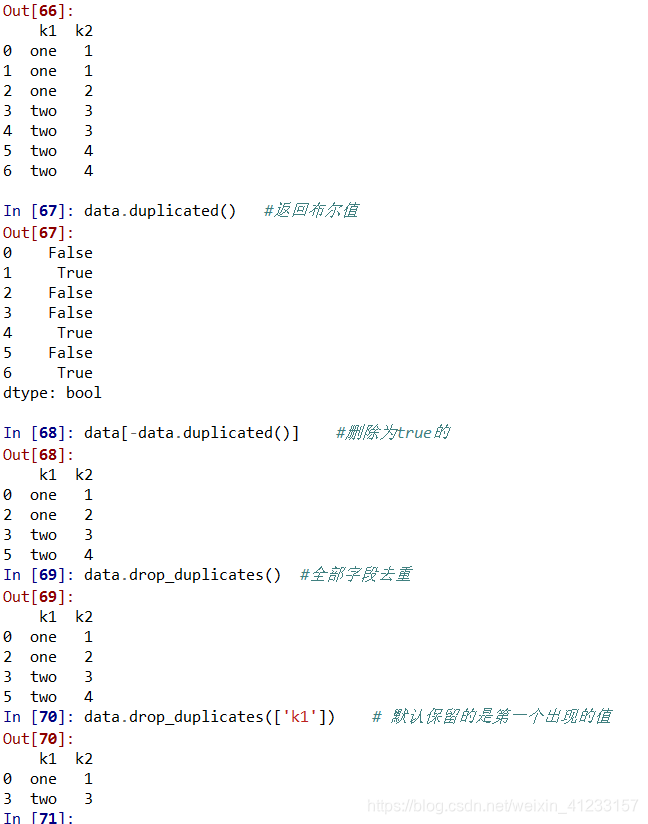
移除重复数据
data = pd.DataFrame({‘k1’:[‘one’]*3 + [‘two’]*4,
‘k2’:[1,1,2,3,3,4,4]})
data
data.duplicated() #返回布尔值
data[-data.duplicated()] #删除为true的
data.drop_duplicates() #全部字段去重
data.drop_duplicates([‘k1’]) # 默认保留的是第一个出现的值
data.drop_duplicates([‘k1’,‘k2’],take_last=True) #take_last保留最后一个
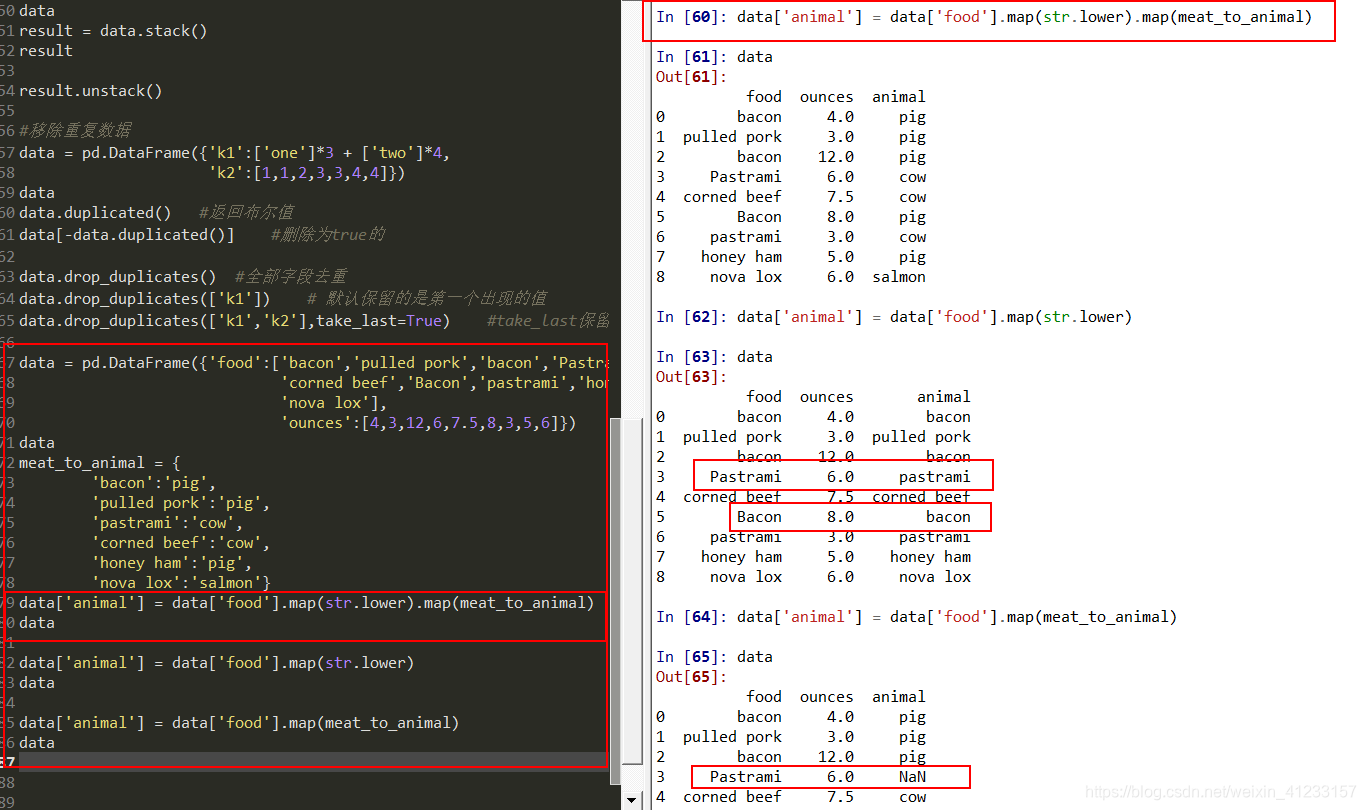
map操作
data = pd.DataFrame({‘food’:[‘bacon’,‘pulled pork’,‘bacon’,‘Pastrami’,
‘corned beef’,‘Bacon’,‘pastrami’,‘honey ham’,
‘nova lox’],
‘ounces’:[4,3,12,6,7.5,8,3,5,6]})
meat_to_animal = {
‘bacon’:‘pig’,
‘pulled pork’:‘pig’,
‘pastrami’:‘cow’,
‘corned beef’:‘cow’,
‘honey ham’:‘pig’,
‘nova lox’:‘salmon’}
data[‘animal’] = data[‘food’].map(str.lower).map(meat_to_animal)
data

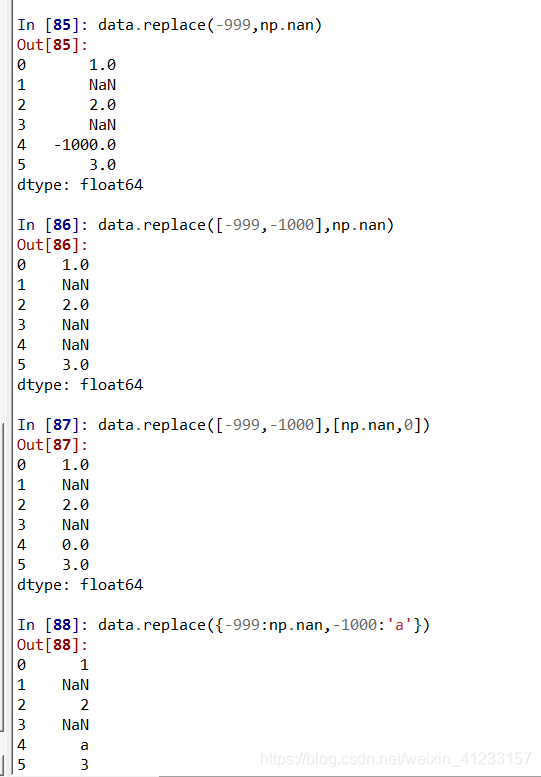
缺失值替换fillna或replace
重命名轴索引


离散化和面元划分(bin)
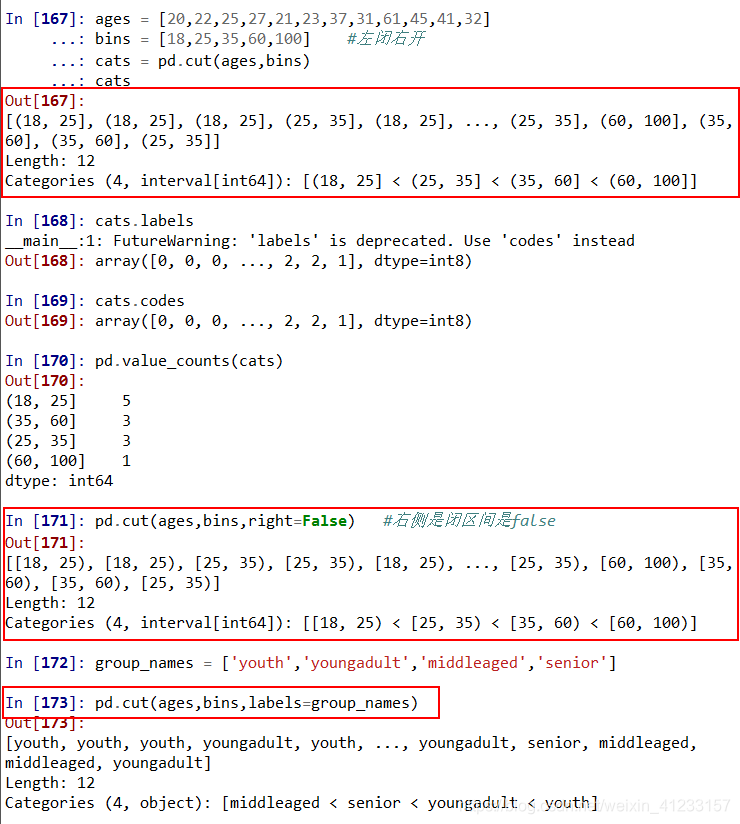
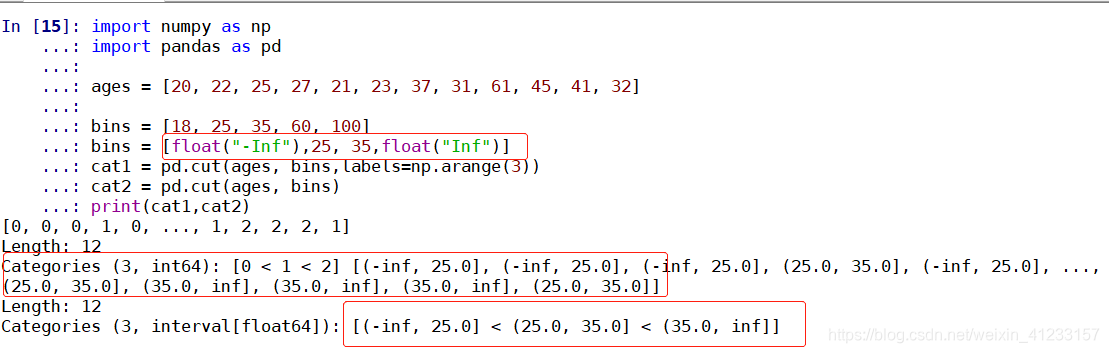
ages = [20,22,25,27,21,23,37,31,61,45,41,32]
bins = [18,25,35,60,100] #默认左闭右开
cats = pd.cut(ages,bins)
pd.cut(ages,bins,right=False) #右侧是闭区间是false
group_names = [‘youth’,‘youngadult’,‘middleaged’,‘senior’]
pd.cut(ages,bins,labels=group_names)
data = np.random.rand(20)
cat2 = pd.cut(data,4,precision=2) #根据min和max计算等长面元,将均匀分布数据分四组,保留两位小数
data = np.random.randn(1000) #正态分布
cats = pd.qcut(data,4) # 按四分位数进行切割
cat1 = pd.qcut(data,[0,0.1,0.5,0.9,1.],precision=2) #自定义分位数

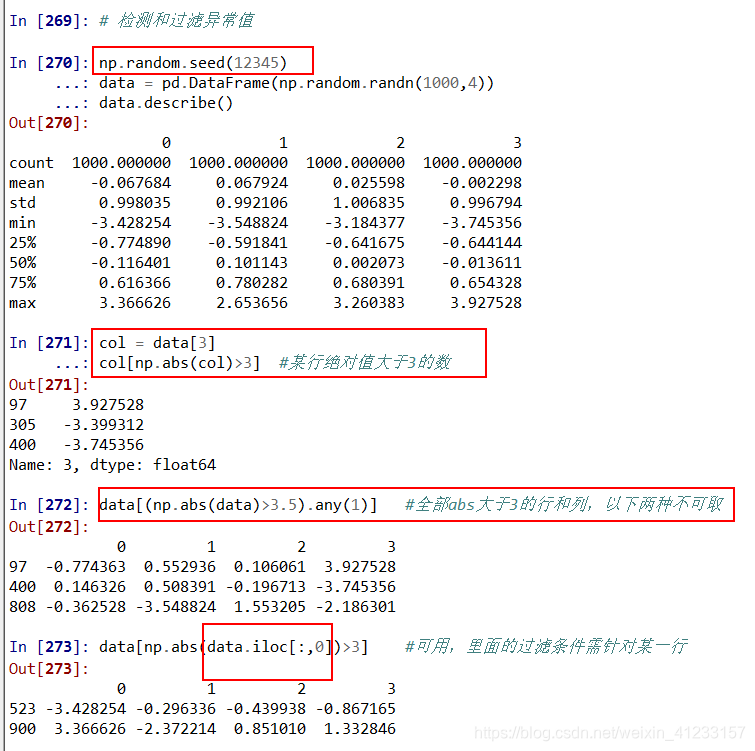
检测和过滤异常值
col = data[3]
col[np.abs(col)>3] #某行绝对值大于3的数
data[(np.abs(data)>3).any(1)] #全部abs大于3的行和列,以下两种不可取
#data[np.abs(data)>3]
#data[data>3]
data[np.abs(data.ix[:,0])>3] #可用,里面的过滤条件需针对某一行
排列和随机采样
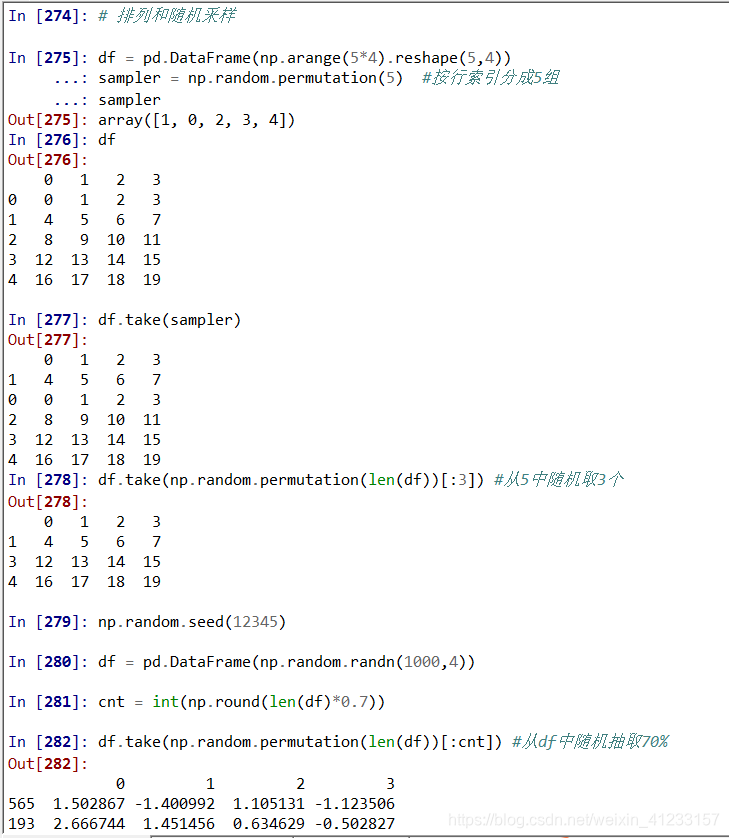
1.dataframe
df = pd.DataFrame(np.arange(5*4).reshape(5,4))
sampler = np.random.permutation(5) #按行索引分成5组
df.take(sampler)
df.take(np.random.permutation(len(df))[:3]) #从5中随机取3个
np.random.seed(12345)
df = pd.DataFrame(np.random.randn(1000,4))
cnt = int(np.round(len(df)*0.7))
df.take(np.random.permutation(len(df))[:cnt]) #从df中随机抽取70%
2.list
random.sample(range(10),3)

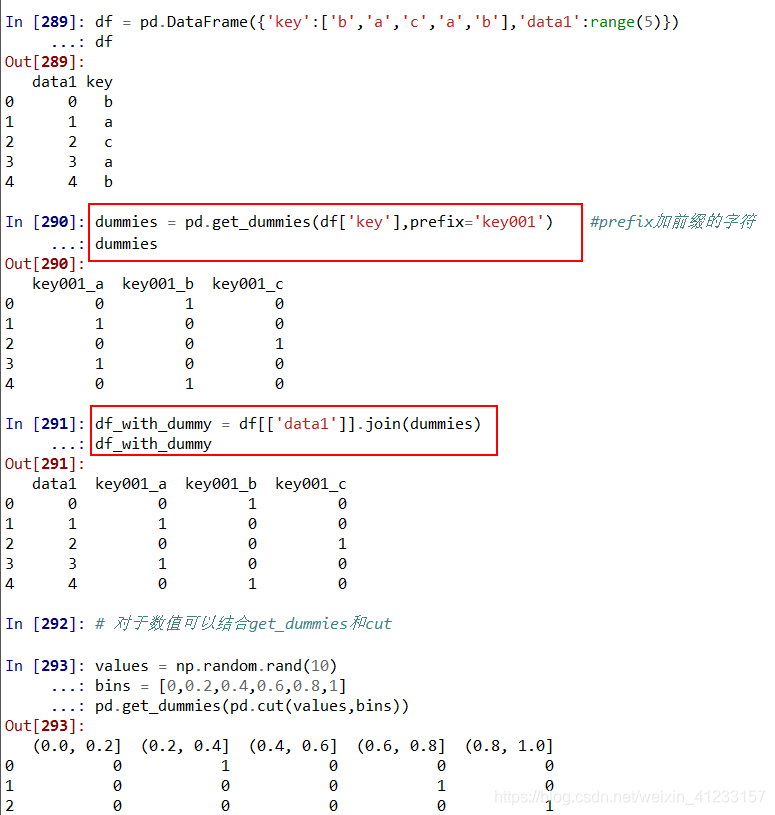
计算指标/哑变量
dummies = pd.get_dummies(df[‘key’],prefix=‘key001’) #prefix加前缀的字符
df_with_dummy = df[[‘data1’]].join(dummies)
对于数值可以结合get_dummies和cut
values = np.random.rand(10)
bins = [0,0.2,0.4,0.6,0.8,1]
pd.get_dummies(pd.cut(values,bins))
#排序和排名
obj = Series(range(4),index=[‘d’,‘a’,‘b’,‘c’])
obj.sort_index()
frame=DataFrame(np.arange(8).reshape((2,4)),index=[‘three’,‘one’],
columns=[‘d’,‘a’,‘b’,‘c’])
frame.sort_index()
frame.sort_index(axis=1, ascending=False) #降序排列,axis=1是对列,0是对行。
frame=DataFrame({‘b’:[4,7,-3,2],‘a’:[0,1,0,1]});frame
frame.sort_values(by=‘b’)
frame.sort_values(by=[‘a’,‘b’])
ROC
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_est_p)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_est_p)
plt.figure(figsize=[6,6])
plt.plot(fpr_test, tpr_test, color=blue)
plt.plot(fpr_train, tpr_train, color=red)
plt.title('ROC curve')
tree.export_graphviz(clf,out_file='tree.dot')#查看树结构
import pickle as pickle
model_file = open(r'clf.model', 'wb')
pickle.dump(clf, model_file)
model_file.close()
model_load_file = open(r'clf.model', 'rb')
model_load = pickle.load(model_load_file)
model_load_file.close()
test_est_load = model_load.predict(test_data)
pd.crosstab(test_est_load,test_est)