b站up主:刘二大人《PyTorch深度学习实践》
教程: https://www.bilibili.com/video/BV1Y7411d7Ys?p=6&vd_source=715b347a0d6cb8aa3822e5a102f366fe
单层
R
N
N
:
t
o
r
c
h
.
n
n
.
R
N
N
+
E
m
b
e
d
d
i
n
g
+
F
C
交叉熵损失函数:
n
n
.
C
r
o
s
s
E
n
t
r
o
p
y
L
o
s
s
优化器:
o
p
t
i
m
.
A
d
a
m
数据集:
h
e
l
l
o
→
期望输出
o
h
l
o
l
单层RNN:torch.nn.RNN+Embedding+FC \\交叉熵损失函数:nn.CrossEntropyLoss \\优化器:optim.Adam \\数据集:hello→期望输出ohlol
单层RNN:torch.nn.RNN+Embedding+FC交叉熵损失函数:nn.CrossEntropyLoss优化器:optim.Adam数据集:hello→期望输出ohlol
网络结构:
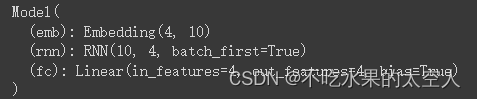
训练过程:
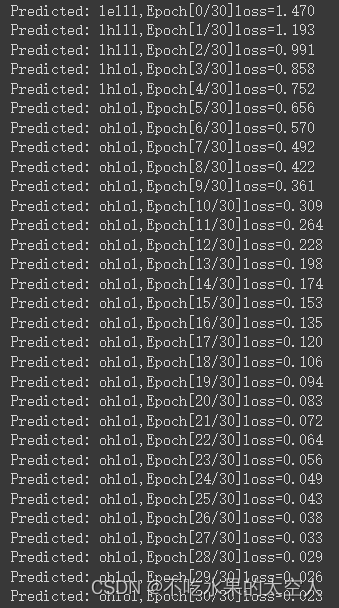
源码:
import torch
input_size = 4
hidden_size = 4
batch_size = 1
embedding_size = 10
num_class = 4
num_layers = 1
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1,0,2,2,3]] #(batch, seq_len)
y_data = [3,1,2,3,2] #(batch, seq_len)
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers = 1):
super(Model, self).__init__()
self.batch_size=batch_size #批量大小
self.input_size=input_size #freature in X, x_t的维度
self.hidden_size=hidden_size #hidden层向量的维度 h_t的维度
self.num_layers=num_layers #层数(上下)
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=self.hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(self.num_layers,
self.batch_size,
self.hidden_size)
x = self.emb(x)
x,_ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
net=Model(input_size=input_size,
hidden_size=hidden_size,
batch_size=batch_size,
num_layers=num_layers)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(0, 30):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
_,idx=outputs.max(dim=1)
idx=idx.data.numpy()
print('Predicted:',''.join([idx2char[x] for x in idx]),end='')
print(',Epoch[%d/30]loss=%.3f'%(epoch,loss.item()))